 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Comfort Zone: Emerging Solutions to Overcome Challenges in Integrating LLMs into Software Products
Oct 15, 2024
Large Language Models (LLMs) are increasingly embedded into software products across diverse industries, enhancing user experiences, but at the same time introducing numerous challenges for developers. Unique characteristics of LLMs force developers, who are accustomed to traditional software development and evaluation, out of their comfort zones as the LLM components shatter standard assumptions about software systems. This study explores the emerging solutions that software developers are adopting to navigate the encountered challenges. Leveraging a mixed-method research, including 26 interviews and a survey with 332 responses, the study identifies 19 emerging solutions regarding quality assurance that practitioners across several product teams at Microsoft are exploring. The findings provide valuable insights that can guide the development and evaluation of LLM-based products more broadly in the face of these challenges.
Evaluating the Evaluator: Measuring LLMs' Adherence to Task Evaluation Instructions
Aug 16, 2024
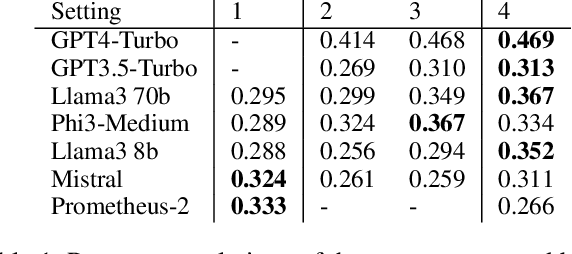
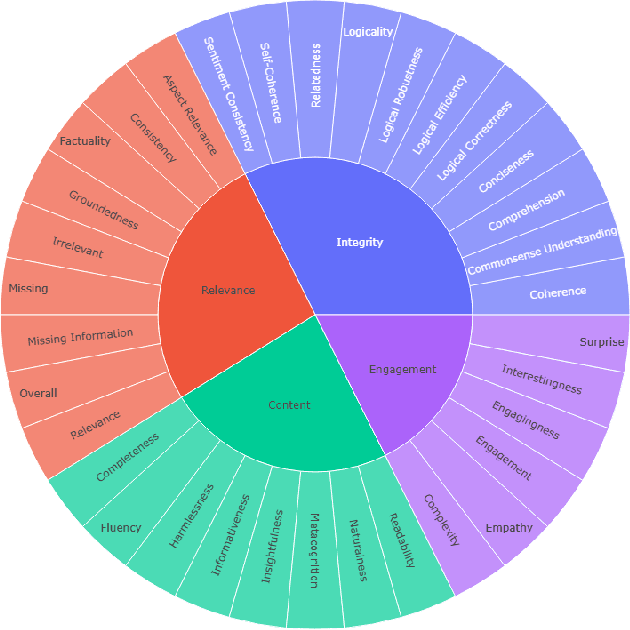
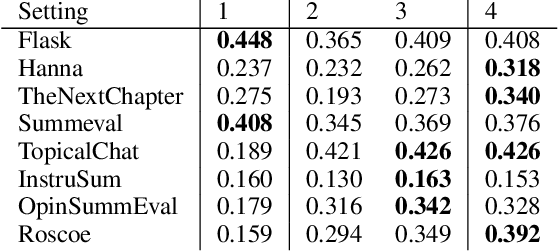
LLMs-as-a-judge is a recently popularized method which replaces human judgements in task evaluation (Zheng et al. 2024) with automatic evaluation using LLMs. Due to widespread use of RLHF (Reinforcement Learning from Human Feedback), state-of-the-art LLMs like GPT4 and Llama3 are expected to have strong alignment with human preferences when prompted for a quality judgement, such as the coherence of a text. While this seems beneficial, it is not clear whether the assessments by an LLM-as-a-judge constitute only an evaluation based on the instructions in the prompts, or reflect its preference for high-quality data similar to its fine-tune data. To investigate how much influence prompting the LLMs-as-a-judge has on the alignment of AI judgements to human judgements, we analyze prompts with increasing levels of instructions about the target quality of an evaluation, for several LLMs-as-a-judge. Further, we compare to a prompt-free method using model perplexity as a quality measure instead. We aggregate a taxonomy of quality criteria commonly used across state-of-the-art evaluations with LLMs and provide this as a rigorous benchmark of models as judges. Overall, we show that the LLMs-as-a-judge benefit only little from highly detailed instructions in prompts and that perplexity can sometimes align better with human judgements than prompting, especially on textual quality.
Exploring Interaction Patterns for Debugging: Enhancing Conversational Capabilities of AI-assistants
Feb 09, 2024



The widespread availability of Large Language Models (LLMs) within Integrated Development Environments (IDEs) has led to their speedy adoption. Conversational interactions with LLMs enable programmers to obtain natural language explanations for various software development tasks. However, LLMs often leap to action without sufficient context, giving rise to implicit assumptions and inaccurate responses. Conversations between developers and LLMs are primarily structured as question-answer pairs, where the developer is responsible for asking the the right questions and sustaining conversations across multiple turns. In this paper, we draw inspiration from interaction patterns and conversation analysis -- to design Robin, an enhanced conversational AI-assistant for debugging. Through a within-subjects user study with 12 industry professionals, we find that equipping the LLM to -- (1) leverage the insert expansion interaction pattern, (2) facilitate turn-taking, and (3) utilize debugging workflows -- leads to lowered conversation barriers, effective fault localization, and 5x improvement in bug resolution rates.
Tabular Representation, Noisy Operators, and Impacts on Table Structure Understanding Tasks in LLMs
Oct 16, 2023Large language models (LLMs) are increasingly applied for tabular tasks using in-context learning. The prompt representation for a table may play a role in the LLMs ability to process the table. Inspired by prior work, we generate a collection of self-supervised structural tasks (e.g. navigate to a cell and row; transpose the table) and evaluate the performance differences when using 8 formats. In contrast to past work, we introduce 8 noise operations inspired by real-world messy data and adversarial inputs, and show that such operations can impact LLM performance across formats for different structural understanding tasks.