 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibration vs Decision Making: Revisiting the Reliability Paradox in Unlearned Language Models
May 20, 2026Machine unlearning aims to remove the influence of specific training data from a model while preserving reliable behavior on the remaining data, making reliable prediction and uncertainty estimation essential for evaluation. Calibration is commonly used as a proxy for reliability in language models, but low calibration error does not necessarily imply reliable decision rules, as models may rely on spurious correlations while remaining well calibrated. We investigate this gap in generative language models using the multiple-choice question-answering evaluation protocol on the TOFU benchmark, measuring probabilistic reliability with calibration metrics (ECE, MCE, Brier) and decision-rule reliability via attribution-based shortcut detection with Integrated Gradients and Local Mutual Information. We find that fine-tuned models achieve low calibration error (ECE ~ 0.04) compared to pretrained models (ECE > 0.5), and models after unlearning retain similarly low calibration despite reduced accuracy on the forget split, while attribution analysis shows increased reliance on correlation-based tokens. These results demonstrate that good calibration can coexist with shortcut-based decision rules after unlearning, extending the reliability paradox to the machine unlearning setting.
CoMuMDR: Code-mixed Multi-modal Multi-domain corpus for Discourse paRsing in conversations
Jun 10, 2025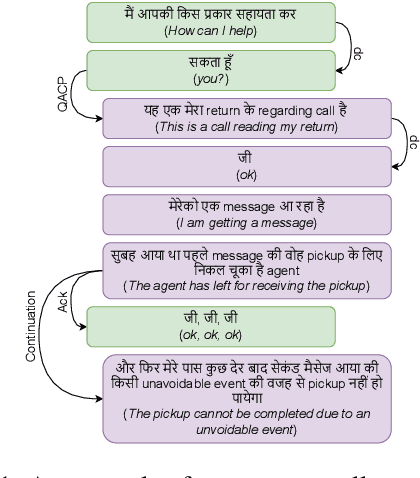
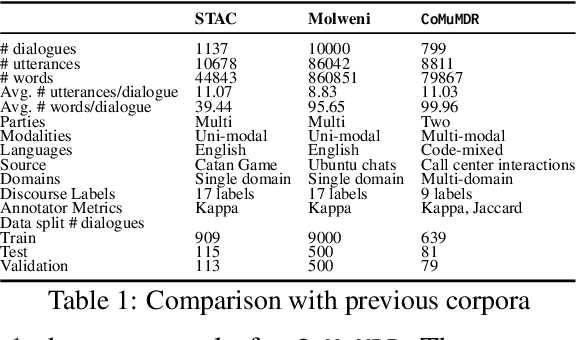
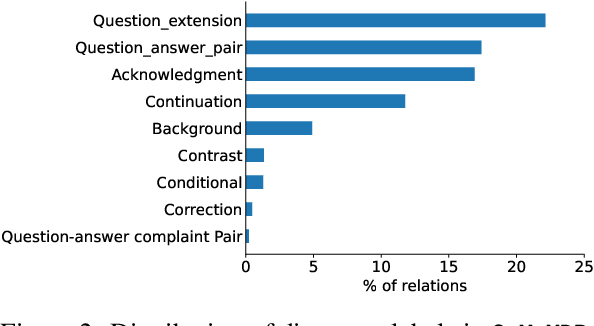

Discourse parsing is an important task useful for NLU applications such as summarization, machine comprehension, and emotion recognition. The current discourse parsing datasets based on conversations consists of written English dialogues restricted to a single domain. In this resource paper, we introduce CoMuMDR: Code-mixed Multi-modal Multi-domain corpus for Discourse paRsing in conversations. The corpus (code-mixed in Hindi and English) has both audio and transcribed text and is annotated with nine discourse relations. We experiment with various SoTA baseline models; the poor performance of SoTA models highlights the challenges of multi-domain code-mixed corpus, pointing towards the need for developing better models for such realistic settings.
Towards Quantifying Commonsense Reasoning with Mechanistic Insights
Apr 14, 2025Commonsense reasoning deals with the implicit knowledge that is well understood by humans and typically acquired via interactions with the world. In recent times, commonsense reasoning and understanding of various LLMs have been evaluated using text-based tasks. In this work, we argue that a proxy of this understanding can be maintained as a graphical structure that can further help to perform a rigorous evaluation of commonsense reasoning abilities about various real-world activities. We create an annotation scheme for capturing this implicit knowledge in the form of a graphical structure for 37 daily human activities. We find that the created resource can be used to frame an enormous number of commonsense queries (~ 10^{17}), facilitating rigorous evaluation of commonsense reasoning in LLMs. Moreover, recently, the remarkable performance of LLMs has raised questions about whether these models are truly capable of reasoning in the wild and, in general, how reasoning occurs inside these models. In this resource paper, we bridge this gap by proposing design mechanisms that facilitate research in a similar direction. Our findings suggest that the reasoning components are localized in LLMs that play a prominent role in decision-making when prompted with a commonsense query.
Towards Robust Evaluation of Unlearning in LLMs via Data Transformations
Nov 23, 2024
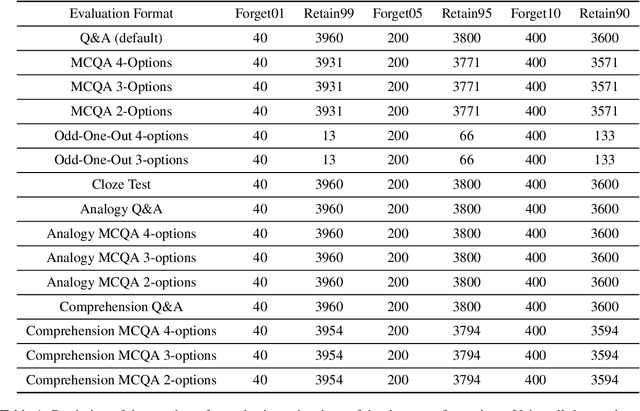


Large Language Models (LLMs) have shown to be a great success in a wide range of applications ranging from regular NLP-based use cases to AI agents. LLMs have been trained on a vast corpus of texts from various sources; despite the best efforts during the data pre-processing stage while training the LLMs, they may pick some undesirable information such as personally identifiable information (PII). Consequently, in recent times research in the area of Machine Unlearning (MUL) has become active, the main idea is to force LLMs to forget (unlearn) certain information (e.g., PII) without suffering from performance loss on regular tasks. In this work, we examine the robustness of the existing MUL techniques for their ability to enable leakage-proof forgetting in LLMs. In particular, we examine the effect of data transformation on forgetting, i.e., is an unlearned LLM able to recall forgotten information if there is a change in the format of the input? Our findings on the TOFU dataset highlight the necessity of using diverse data formats to quantify unlearning in LLMs more reliably.
IITK at SemEval-2024 Task 10: Who is the speaker? Improving Emotion Recognition and Flip Reasoning in Conversations via Speaker Embeddings
Apr 06, 2024

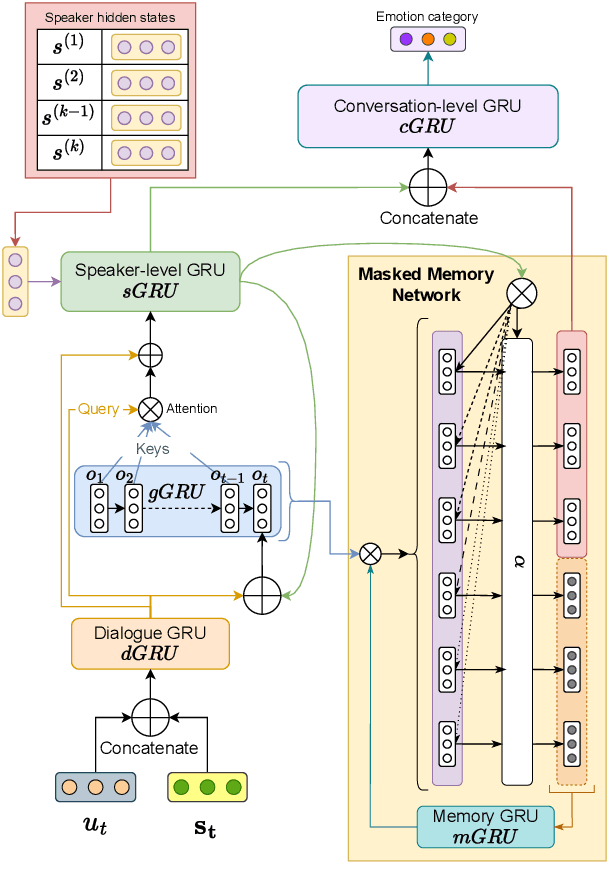

This paper presents our approach for the SemEval-2024 Task 10: Emotion Discovery and Reasoning its Flip in Conversations. For the Emotion Recognition in Conversations (ERC) task, we utilize a masked-memory network along with speaker participation. We propose a transformer-based speaker-centric model for the Emotion Flip Reasoning (EFR) task. We also introduce Probable Trigger Zone, a region of the conversation that is more likely to contain the utterances causing the emotion to flip. For sub-task 3, the proposed approach achieves a 5.9 (F1 score) improvement over the task baseline. The ablation study results highlight the significance of various design choices in the proposed method.