 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSide Effects of Erasing Concepts from Diffusion Models
Aug 20, 2025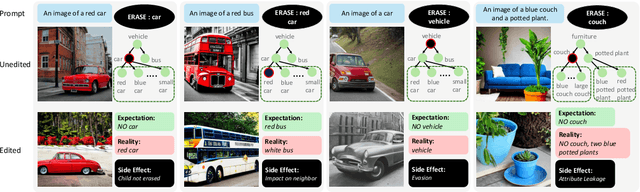
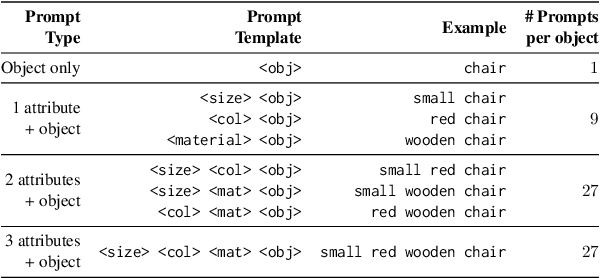
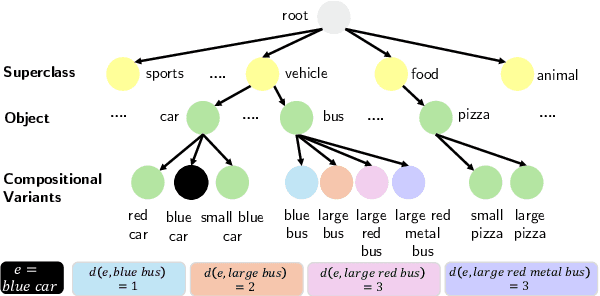

Concerns about text-to-image (T2I) generative models infringing on privacy, copyright, and safety have led to the development of Concept Erasure Techniques (CETs). The goal of an effective CET is to prohibit the generation of undesired ``target'' concepts specified by the user, while preserving the ability to synthesize high-quality images of the remaining concepts. In this work, we demonstrate that CETs can be easily circumvented and present several side effects of concept erasure. For a comprehensive measurement of the robustness of CETs, we present Side Effect Evaluation (\see), an evaluation benchmark that consists of hierarchical and compositional prompts that describe objects and their attributes. This dataset and our automated evaluation pipeline quantify side effects of CETs across three aspects: impact on neighboring concepts, evasion of targets, and attribute leakage. Our experiments reveal that CETs can be circumvented by using superclass-subclass hierarchy and semantically similar prompts, such as compositional variants of the target. We show that CETs suffer from attribute leakage and counterintuitive phenomena of attention concentration or dispersal. We release our dataset, code, and evaluation tools to aid future work on robust concept erasure.
Towards Robust Evaluation of Unlearning in LLMs via Data Transformations
Nov 23, 2024
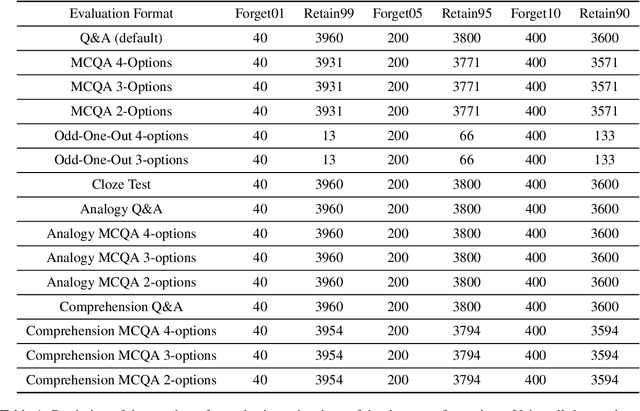


Large Language Models (LLMs) have shown to be a great success in a wide range of applications ranging from regular NLP-based use cases to AI agents. LLMs have been trained on a vast corpus of texts from various sources; despite the best efforts during the data pre-processing stage while training the LLMs, they may pick some undesirable information such as personally identifiable information (PII). Consequently, in recent times research in the area of Machine Unlearning (MUL) has become active, the main idea is to force LLMs to forget (unlearn) certain information (e.g., PII) without suffering from performance loss on regular tasks. In this work, we examine the robustness of the existing MUL techniques for their ability to enable leakage-proof forgetting in LLMs. In particular, we examine the effect of data transformation on forgetting, i.e., is an unlearned LLM able to recall forgotten information if there is a change in the format of the input? Our findings on the TOFU dataset highlight the necessity of using diverse data formats to quantify unlearning in LLMs more reliably.
RFC-Net: Learning High Resolution Global Features for Medical Image Segmentation on a Computational Budget
Feb 13, 2023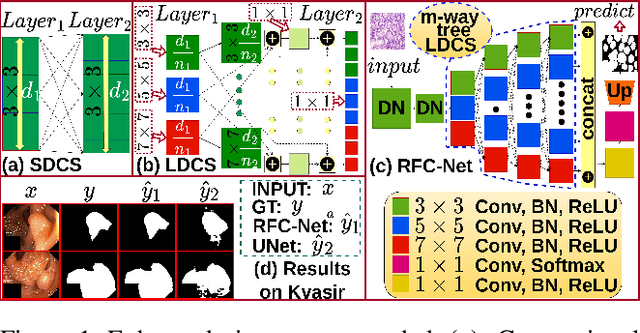

Learning High-Resolution representations is essential for semantic segmentation. Convolutional neural network (CNN)architectures with downstream and upstream propagation flow are popular for segmentation in medical diagnosis. However, due to performing spatial downsampling and upsampling in multiple stages, information loss is inexorable. On the contrary, connecting layers densely on high spatial resolution is computationally expensive. In this work, we devise a Loose Dense Connection Strategy to connect neurons in subsequent layers with reduced parameters. On top of that, using a m-way Tree structure for feature propagation we propose Receptive Field Chain Network (RFC-Net) that learns high resolution global features on a compressed computational space. Our experiments demonstrates that RFC-Net achieves state-of-the-art performance on Kvasir and CVC-ClinicDB benchmarks for Polyp segmentation.