 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Tokenization Bottleneck: How Vocabulary Extension Improves Chemistry Representation Learning in Pretrained Language Models
Nov 18, 2025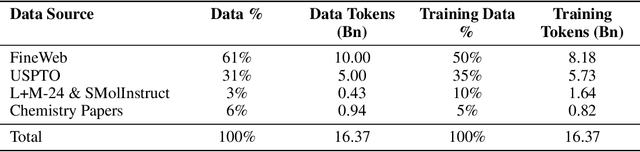



The application of large language models (LLMs) to chemistry is frequently hampered by a "tokenization bottleneck", where tokenizers tuned on general-domain text tend to fragment chemical representations such as SMILES into semantically uninformative sub-tokens. This paper introduces a principled methodology to resolve this bottleneck by unifying the representation of natural language and molecular structures within a single model. Our approach involves targeted vocabulary extension-augmenting a pretrained LLM's vocabulary with chemically salient tokens, followed by continued pretraining on chemistry-domain text to integrate this new knowledge. We provide an empirical demonstration of the effectiveness of this strategy, showing that our methodology leads to superior performance on a range of downstream chemical tasks.
Aalap: AI Assistant for Legal & Paralegal Functions in India
Jan 30, 2024Using proprietary Large Language Models on legal tasks poses challenges due to data privacy issues, domain data heterogeneity, domain knowledge sophistication, and domain objectives uniqueness. We created Aalalp, a fine-tuned Mistral 7B model on instructions data related to specific Indian legal tasks. The performance of Aalap is better than gpt-3.5-turbo in 31\% of our test data and obtains an equivalent score in 34\% of the test data as evaluated by GPT4. Training Aalap mainly focuses on teaching legal reasoning rather than legal recall. Aalap is definitely helpful for the day-to-day activities of lawyers, judges, or anyone working in legal systems.
SemEval 2023 Task 6: LegalEval - Understanding Legal Texts
May 01, 2023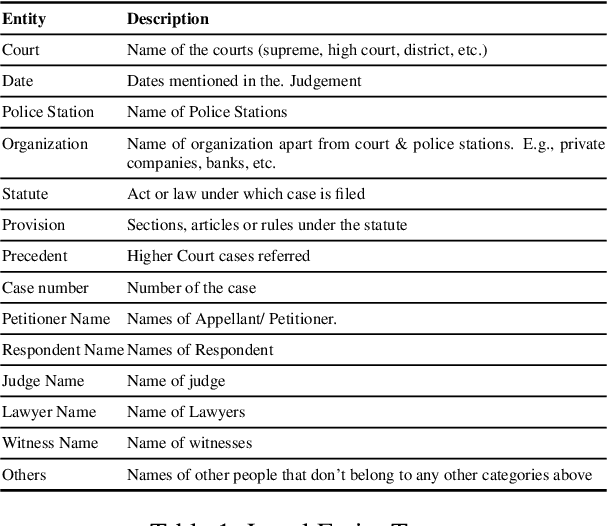


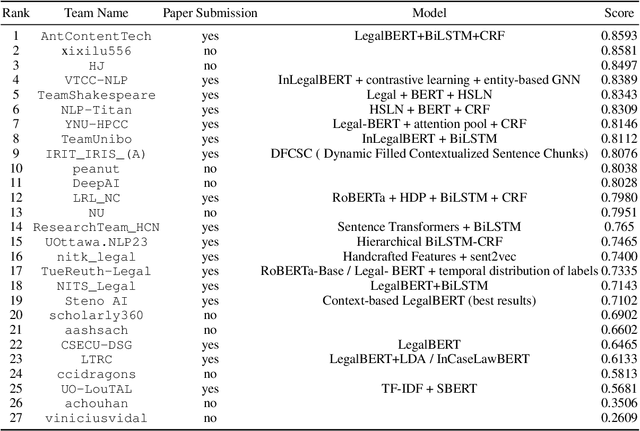
In populous countries, pending legal cases have been growing exponentially. There is a need for developing NLP-based techniques for processing and automatically understanding legal documents. To promote research in the area of Legal NLP we organized the shared task LegalEval - Understanding Legal Texts at SemEval 2023. LegalEval task has three sub-tasks: Task-A (Rhetorical Roles Labeling) is about automatically structuring legal documents into semantically coherent units, Task-B (Legal Named Entity Recognition) deals with identifying relevant entities in a legal document and Task-C (Court Judgement Prediction with Explanation) explores the possibility of automatically predicting the outcome of a legal case along with providing an explanation for the prediction. In total 26 teams (approx. 100 participants spread across the world) submitted systems paper. In each of the sub-tasks, the proposed systems outperformed the baselines; however, there is a lot of scope for improvement. This paper describes the tasks, and analyzes techniques proposed by various teams.
Named Entity Recognition in Indian court judgments
Nov 07, 2022Identification of named entities from legal texts is an essential building block for developing other legal Artificial Intelligence applications. Named Entities in legal texts are slightly different and more fine-grained than commonly used named entities like Person, Organization, Location etc. In this paper, we introduce a new corpus of 46545 annotated legal named entities mapped to 14 legal entity types. The Baseline model for extracting legal named entities from judgment text is also developed.
Corpus for Automatic Structuring of Legal Documents
Jan 31, 2022
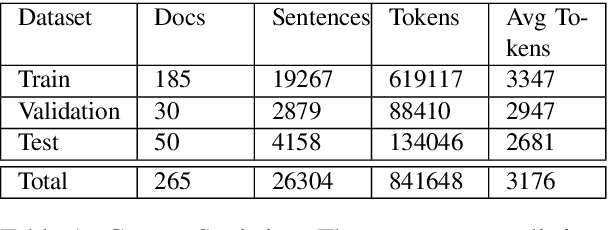
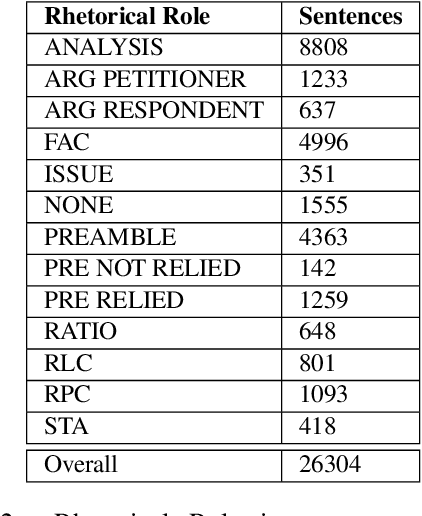
In populous countries, pending legal cases have been growing exponentially. There is a need for developing techniques for processing and organizing legal documents. In this paper, we introduce a new corpus for structuring legal documents. In particular, we introduce a corpus of legal judgment documents in English that are segmented into topical and coherent parts. Each of these parts is annotated with a label coming from a list of pre-defined Rhetorical Roles. We develop baseline models for automatically predicting rhetorical roles in a legal document based on the annotated corpus. Further, we show the application of rhetorical roles to improve performance on the tasks of summarization and legal judgment prediction. We release the corpus and baseline model code along with the paper.
Indian Legal NLP Benchmarks : A Survey
Jul 13, 2021
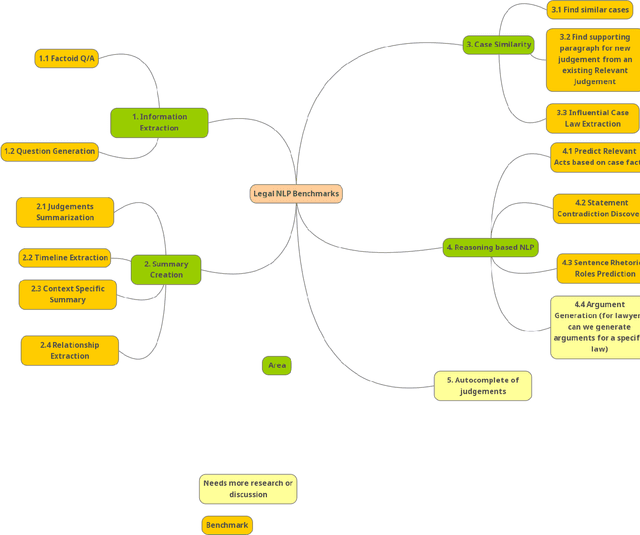
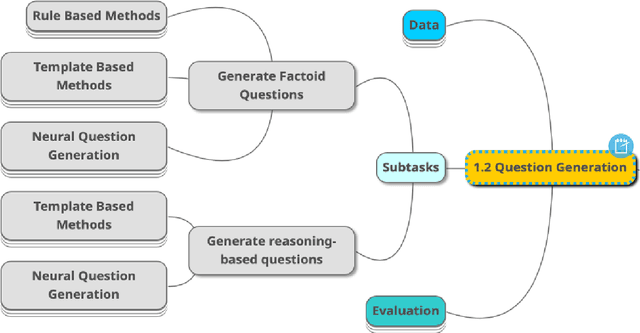
Availability of challenging benchmarks is the key to advancement of AI in a specific field.Since Legal Text is significantly different than normal English text, there is a need to create separate Natural Language Processing benchmarks for Indian Legal Text which are challenging and focus on tasks specific to Legal Systems. This will spur innovation in applications of Natural language Processing for Indian Legal Text and will benefit AI community and Legal fraternity. We review the existing work in this area and propose ideas to create new benchmarks for Indian Legal Natural Language Processing.