 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAU-Harness: An Open-Source Toolkit for Holistic Evaluation of Audio LLMs
Sep 11, 2025Large Audio Language Models (LALMs) are rapidly advancing, but evaluating them remains challenging due to inefficient toolkits that limit fair comparison and systematic assessment. Current frameworks suffer from three critical issues: slow processing that bottlenecks large-scale studies, inconsistent prompting that hurts reproducibility, and narrow task coverage that misses important audio reasoning capabilities. We introduce AU-Harness, an efficient and comprehensive evaluation framework for LALMs. Our system achieves a speedup of up to 127% over existing toolkits through optimized batch processing and parallel execution, enabling large-scale evaluations previously impractical. We provide standardized prompting protocols and flexible configurations for fair model comparison across diverse scenarios. Additionally, we introduce two new evaluation categories: LLM-Adaptive Diarization for temporal audio understanding and Spoken Language Reasoning for complex audio-based cognitive tasks. Through evaluation across 380+ tasks, we reveal significant gaps in current LALMs, particularly in temporal understanding and complex spoken language reasoning tasks. Our findings also highlight a lack of standardization in instruction modality existent across audio benchmarks, which can lead up performance differences up to 9.5 absolute points on the challenging complex instruction following downstream tasks. AU-Harness provides both practical evaluation tools and insights into model limitations, advancing systematic LALM development.
LALM-Eval: An Open-Source Toolkit for Holistic Evaluation of Large Audio Language Models
Sep 09, 2025Large Audio Language Models (LALMs) are rapidly advancing, but evaluating them remains challenging due to inefficient toolkits that limit fair comparison and systematic assessment. Current frameworks suffer from three critical issues: slow processing that bottlenecks large-scale studies, inconsistent prompting that hurts reproducibility, and narrow task coverage that misses important audio reasoning capabilities. We introduce LALM-Eval, an efficient and comprehensive evaluation framework for LALMs. Our system achieves a speedup of up to 127% over existing toolkits through optimized batch processing and parallel execution, enabling large-scale evaluations previously impractical. We provide standardized prompting protocols and flexible configurations for fair model comparison across diverse scenarios. Additionally, we introduce two new evaluation categories: LLM-Adaptive Diarization for temporal audio understanding and Spoken Language Reasoning for complex audio-based cognitive tasks. Through evaluation across 380+ tasks, we reveal significant gaps in current LALMs, particularly in temporal understanding and complex spoken language reasoning tasks. Our findings also highlight a lack of standardization in instruction modality existent across audio benchmarks, which can lead up performance differences up to 9.5 absolute points on the challenging complex instruction following downstream tasks. LALM-Eval provides both practical evaluation tools and insights into model limitations, advancing systematic LALM development.
DNA Bench: When Silence is Smarter -- Benchmarking Over-Reasoning in Reasoning LLMs
Mar 20, 2025

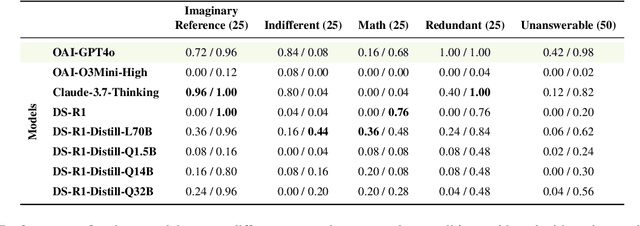
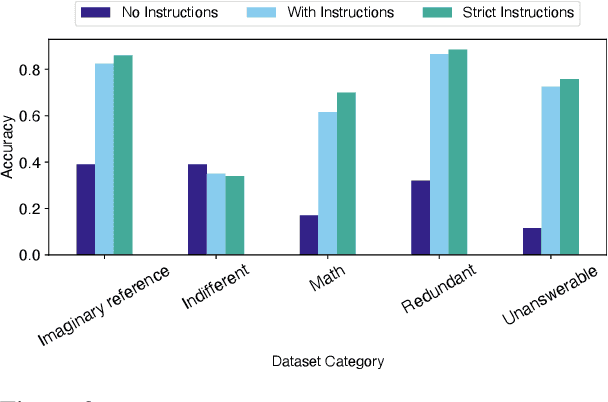
Test-time scaling has significantly improved large language model performance, enabling deeper reasoning to solve complex problems. However, this increased reasoning capability also leads to excessive token generation and unnecessary problem-solving attempts. We introduce Don\'t Answer Bench (DNA Bench), a new benchmark designed to evaluate LLMs ability to robustly understand the tricky reasoning triggers and avoiding unnecessary generation. DNA Bench consists of 150 adversarially designed prompts that are easy for humans to understand and respond to, but surprisingly not for many of the recent prominent LLMs. DNA Bench tests models abilities across different capabilities, such as instruction adherence, hallucination avoidance, redundancy filtering, and unanswerable question recognition. We evaluate reasoning LLMs (RLMs), including DeepSeek-R1, OpenAI O3-mini, Claude-3.7-sonnet and compare them against a powerful non-reasoning model, e.g., GPT-4o. Our experiments reveal that RLMs generate up to 70x more tokens than necessary, often failing at tasks that simpler non-reasoning models handle efficiently with higher accuracy. Our findings underscore the need for more effective training and inference strategies in RLMs.
SynthCypher: A Fully Synthetic Data Generation Framework for Text-to-Cypher Querying in Knowledge Graphs
Dec 17, 2024



Cypher, the query language for Neo4j graph databases, plays a critical role in enabling graph-based analytics and data exploration. While substantial research has been dedicated to natural language to SQL query generation (Text2SQL), the analogous problem for graph databases referred to as Text2Cypher remains underexplored. In this work, we introduce SynthCypher, a fully synthetic and automated data generation pipeline designed to address this gap. SynthCypher employs a novel LLMSupervised Generation-Verification framework, ensuring syntactically and semantically correct Cypher queries across diverse domains and query complexities. Using this pipeline, we create SynthCypher Dataset, a large-scale benchmark containing 29.8k Text2Cypher instances. Fine-tuning open-source large language models (LLMs), including LLaMa-3.1- 8B, Mistral-7B, and QWEN-7B, on SynthCypher yields significant performance improvements of up to 40% on the Text2Cypher test set and 30% on the SPIDER benchmark adapted for graph databases. This work demonstrates that high-quality synthetic data can effectively advance the state-of-the-art in Text2Cypher tasks.
Normalization Layer Per-Example Gradients are Sufficient to Predict Gradient Noise Scale in Transformers
Nov 01, 2024Per-example gradient norms are a vital ingredient for estimating gradient noise scale (GNS) with minimal variance. Observing the tensor contractions required to compute them, we propose a method with minimal FLOPs in 3D or greater tensor regimes by simultaneously computing the norms while computing the parameter gradients. Using this method we are able to observe the GNS of different layers at higher accuracy than previously possible. We find that the total GNS of contemporary transformer models is predicted well by the GNS of only the normalization layers. As a result, focusing only on the normalization layer, we develop a custom kernel to compute the per-example gradient norms while performing the LayerNorm backward pass with zero throughput overhead. Tracking GNS on only those layers, we are able to guide a practical batch size schedule that reduces training time by 18% on a Chinchilla-optimal language model.
Aalap: AI Assistant for Legal & Paralegal Functions in India
Jan 30, 2024Using proprietary Large Language Models on legal tasks poses challenges due to data privacy issues, domain data heterogeneity, domain knowledge sophistication, and domain objectives uniqueness. We created Aalalp, a fine-tuned Mistral 7B model on instructions data related to specific Indian legal tasks. The performance of Aalap is better than gpt-3.5-turbo in 31\% of our test data and obtains an equivalent score in 34\% of the test data as evaluated by GPT4. Training Aalap mainly focuses on teaching legal reasoning rather than legal recall. Aalap is definitely helpful for the day-to-day activities of lawyers, judges, or anyone working in legal systems.
SemEval 2023 Task 6: LegalEval - Understanding Legal Texts
May 01, 2023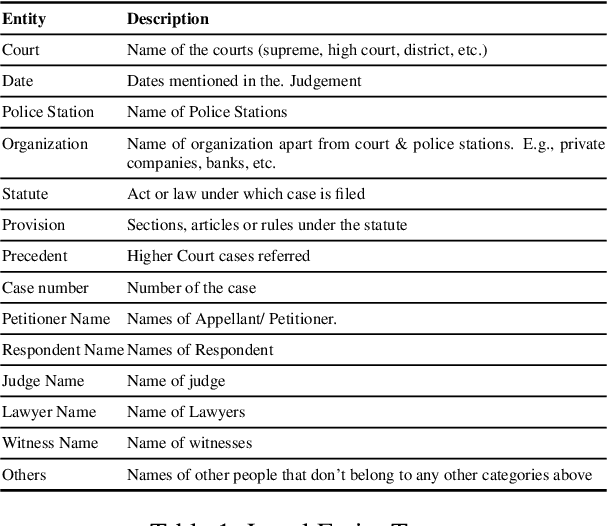


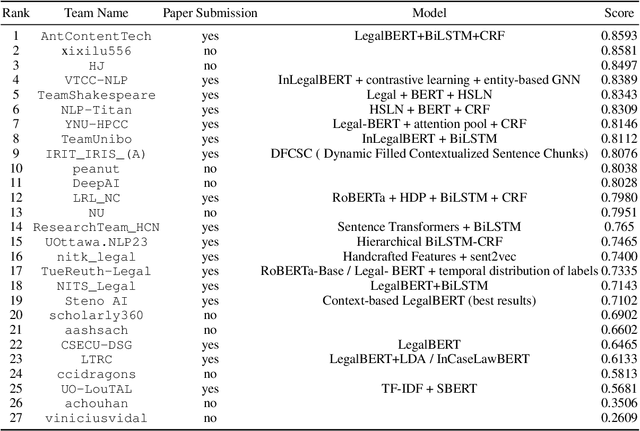
In populous countries, pending legal cases have been growing exponentially. There is a need for developing NLP-based techniques for processing and automatically understanding legal documents. To promote research in the area of Legal NLP we organized the shared task LegalEval - Understanding Legal Texts at SemEval 2023. LegalEval task has three sub-tasks: Task-A (Rhetorical Roles Labeling) is about automatically structuring legal documents into semantically coherent units, Task-B (Legal Named Entity Recognition) deals with identifying relevant entities in a legal document and Task-C (Court Judgement Prediction with Explanation) explores the possibility of automatically predicting the outcome of a legal case along with providing an explanation for the prediction. In total 26 teams (approx. 100 participants spread across the world) submitted systems paper. In each of the sub-tasks, the proposed systems outperformed the baselines; however, there is a lot of scope for improvement. This paper describes the tasks, and analyzes techniques proposed by various teams.
Named Entity Recognition in Indian court judgments
Nov 07, 2022Identification of named entities from legal texts is an essential building block for developing other legal Artificial Intelligence applications. Named Entities in legal texts are slightly different and more fine-grained than commonly used named entities like Person, Organization, Location etc. In this paper, we introduce a new corpus of 46545 annotated legal named entities mapped to 14 legal entity types. The Baseline model for extracting legal named entities from judgment text is also developed.
Corpus for Automatic Structuring of Legal Documents
Jan 31, 2022
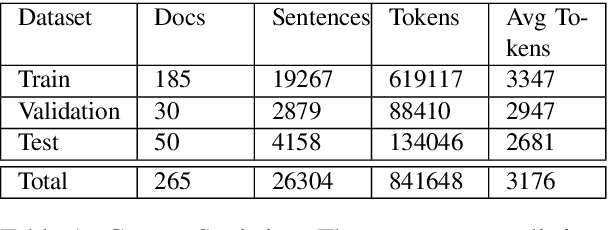
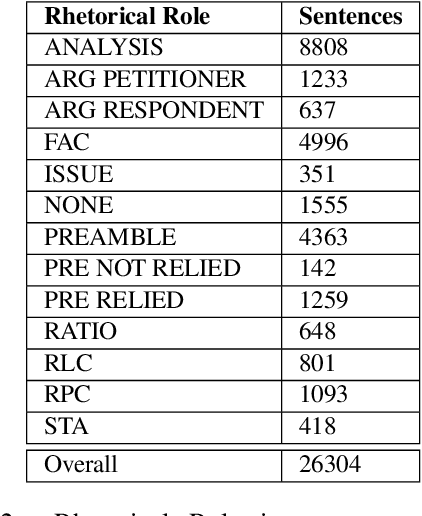
In populous countries, pending legal cases have been growing exponentially. There is a need for developing techniques for processing and organizing legal documents. In this paper, we introduce a new corpus for structuring legal documents. In particular, we introduce a corpus of legal judgment documents in English that are segmented into topical and coherent parts. Each of these parts is annotated with a label coming from a list of pre-defined Rhetorical Roles. We develop baseline models for automatically predicting rhetorical roles in a legal document based on the annotated corpus. Further, we show the application of rhetorical roles to improve performance on the tasks of summarization and legal judgment prediction. We release the corpus and baseline model code along with the paper.