 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUSAD: An Unsupervised Data Augmentation Spatio-Temporal Attention Diffusion Network
Jul 03, 2025The primary objective of human activity recognition (HAR) is to infer ongoing human actions from sensor data, a task that finds broad applications in health monitoring, safety protection, and sports analysis. Despite proliferating research, HAR still faces key challenges, including the scarcity of labeled samples for rare activities, insufficient extraction of high-level features, and suboptimal model performance on lightweight devices. To address these issues, this paper proposes a comprehensive optimization approach centered on multi-attention interaction mechanisms. First, an unsupervised, statistics-guided diffusion model is employed to perform data augmentation, thereby alleviating the problems of labeled data scarcity and severe class imbalance. Second, a multi-branch spatio-temporal interaction network is designed, which captures multi-scale features of sequential data through parallel residual branches with 3*3, 5*5, and 7*7 convolutional kernels. Simultaneously, temporal attention mechanisms are incorporated to identify critical time points, while spatial attention enhances inter-sensor interactions. A cross-branch feature fusion unit is further introduced to improve the overall feature representation capability. Finally, an adaptive multi-loss function fusion strategy is integrated, allowing for dynamic adjustment of loss weights and overall model optimization. Experimental results on three public datasets, WISDM, PAMAP2, and OPPORTUNITY, demonstrate that the proposed unsupervised data augmentation spatio-temporal attention diffusion network (USAD) achieves accuracies of 98.84%, 93.81%, and 80.92% respectively, significantly outperforming existing approaches. Furthermore, practical deployment on embedded devices verifies the efficiency and feasibility of the proposed method.
Redundant feature screening method for human activity recognition based on attention purification mechanism
Mar 30, 2025In the field of sensor-based Human Activity Recognition (HAR), deep neural networks provide advanced technical support. Many studies have proven that recognition accuracy can be improved by increasing the depth or width of the network. However, for wearable devices, the balance between network performance and resource consumption is crucial. With minimum resource consumption as the basic principle, we propose a universal attention feature purification mechanism, called MSAP, which is suitable for multi-scale networks. The mechanism effectively solves the feature redundancy caused by the superposition of multi-scale features by means of inter-scale attention screening and connection method. In addition, we have designed a network correction module that integrates seamlessly between layers of individual network modules to mitigate inherent problems in deep networks. We also built an embedded deployment system that is in line with the current level of wearable technology to test the practical feasibility of the HAR model, and further prove the efficiency of the method. Extensive experiments on four public datasets show that the proposed method model effectively reduces redundant features in filtered data and provides excellent performance with little resource consumption.
CMD-HAR: Cross-Modal Disentanglement for Wearable Human Activity Recognition
Mar 27, 2025Human Activity Recognition (HAR) is a fundamental technology for numerous human - centered intelligent applications. Although deep learning methods have been utilized to accelerate feature extraction, issues such as multimodal data mixing, activity heterogeneity, and complex model deployment remain largely unresolved. The aim of this paper is to address issues such as multimodal data mixing, activity heterogeneity, and complex model deployment in sensor-based human activity recognition. We propose a spatiotemporal attention modal decomposition alignment fusion strategy to tackle the problem of the mixed distribution of sensor data. Key discriminative features of activities are captured through cross-modal spatio-temporal disentangled representation, and gradient modulation is combined to alleviate data heterogeneity. In addition, a wearable deployment simulation system is constructed. We conducted experiments on a large number of public datasets, demonstrating the effectiveness of the model.
LServe: Efficient Long-sequence LLM Serving with Unified Sparse Attention
Feb 20, 2025Large language models (LLMs) have shown remarkable potential in processing long sequences, yet efficiently serving these long-context models remains challenging due to the quadratic computational complexity of attention in the prefilling stage and the large memory footprint of the KV cache in the decoding stage. To address these issues, we introduce LServe, an efficient system that accelerates long-sequence LLM serving via hybrid sparse attention. This method unifies different hardware-friendly, structured sparsity patterns for both prefilling and decoding attention into a single framework, where computations on less important tokens are skipped block-wise. LServe demonstrates the compatibility of static and dynamic sparsity in long-context LLM attention. This design enables multiplicative speedups by combining these optimizations. Specifically, we convert half of the attention heads to nearly free streaming heads in both the prefilling and decoding stages. Additionally, we find that only a constant number of KV pages is required to preserve long-context capabilities, irrespective of context length. We then design a hierarchical KV page selection policy that dynamically prunes KV pages based on query-centric similarity. On average, LServe accelerates LLM prefilling by up to 2.9x and decoding by 1.3-2.1x over vLLM, maintaining long-context accuracy. Code is released at https://github.com/mit-han-lab/omniserve.
SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers
Oct 15, 2024



We introduce Sana, a text-to-image framework that can efficiently generate images up to 4096$\times$4096 resolution. Sana can synthesize high-resolution, high-quality images with strong text-image alignment at a remarkably fast speed, deployable on laptop GPU. Core designs include: (1) Deep compression autoencoder: unlike traditional AEs, which compress images only 8$\times$, we trained an AE that can compress images 32$\times$, effectively reducing the number of latent tokens. (2) Linear DiT: we replace all vanilla attention in DiT with linear attention, which is more efficient at high resolutions without sacrificing quality. (3) Decoder-only text encoder: we replaced T5 with modern decoder-only small LLM as the text encoder and designed complex human instruction with in-context learning to enhance the image-text alignment. (4) Efficient training and sampling: we propose Flow-DPM-Solver to reduce sampling steps, with efficient caption labeling and selection to accelerate convergence. As a result, Sana-0.6B is very competitive with modern giant diffusion model (e.g. Flux-12B), being 20 times smaller and 100+ times faster in measured throughput. Moreover, Sana-0.6B can be deployed on a 16GB laptop GPU, taking less than 1 second to generate a 1024$\times$1024 resolution image. Sana enables content creation at low cost. Code and model will be publicly released.
Deep Compression Autoencoder for Efficient High-Resolution Diffusion Models
Oct 14, 2024
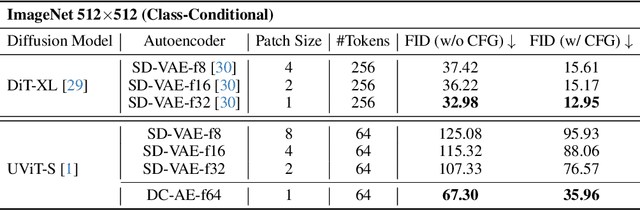
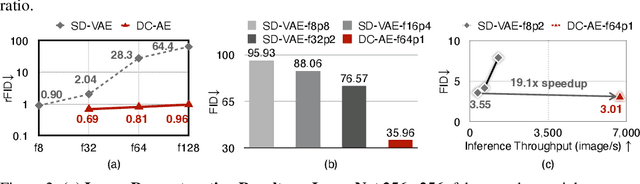
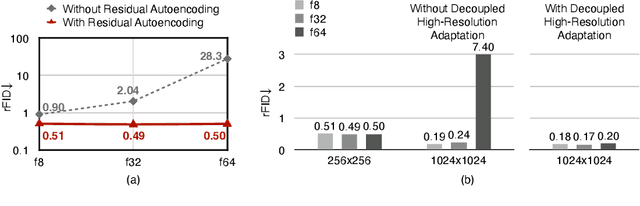
We present Deep Compression Autoencoder (DC-AE), a new family of autoencoder models for accelerating high-resolution diffusion models. Existing autoencoder models have demonstrated impressive results at a moderate spatial compression ratio (e.g., 8x), but fail to maintain satisfactory reconstruction accuracy for high spatial compression ratios (e.g., 64x). We address this challenge by introducing two key techniques: (1) Residual Autoencoding, where we design our models to learn residuals based on the space-to-channel transformed features to alleviate the optimization difficulty of high spatial-compression autoencoders; (2) Decoupled High-Resolution Adaptation, an efficient decoupled three-phases training strategy for mitigating the generalization penalty of high spatial-compression autoencoders. With these designs, we improve the autoencoder's spatial compression ratio up to 128 while maintaining the reconstruction quality. Applying our DC-AE to latent diffusion models, we achieve significant speedup without accuracy drop. For example, on ImageNet 512x512, our DC-AE provides 19.1x inference speedup and 17.9x training speedup on H100 GPU for UViT-H while achieving a better FID, compared with the widely used SD-VAE-f8 autoencoder. Our code is available at https://github.com/mit-han-lab/efficientvit.
HART: Efficient Visual Generation with Hybrid Autoregressive Transformer
Oct 14, 2024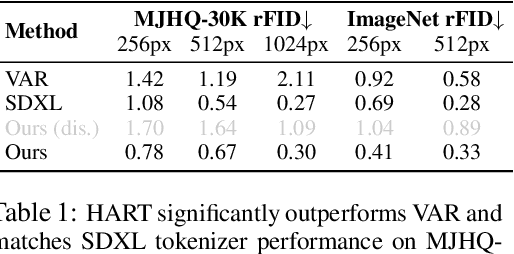

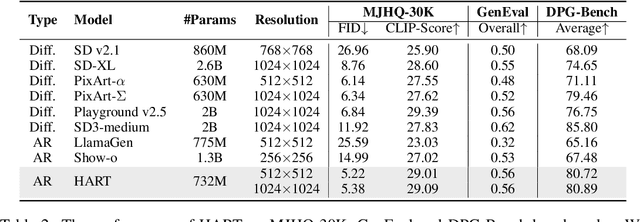

We introduce Hybrid Autoregressive Transformer (HART), an autoregressive (AR) visual generation model capable of directly generating 1024x1024 images, rivaling diffusion models in image generation quality. Existing AR models face limitations due to the poor image reconstruction quality of their discrete tokenizers and the prohibitive training costs associated with generating 1024px images. To address these challenges, we present the hybrid tokenizer, which decomposes the continuous latents from the autoencoder into two components: discrete tokens representing the big picture and continuous tokens representing the residual components that cannot be represented by the discrete tokens. The discrete component is modeled by a scalable-resolution discrete AR model, while the continuous component is learned with a lightweight residual diffusion module with only 37M parameters. Compared with the discrete-only VAR tokenizer, our hybrid approach improves reconstruction FID from 2.11 to 0.30 on MJHQ-30K, leading to a 31% generation FID improvement from 7.85 to 5.38. HART also outperforms state-of-the-art diffusion models in both FID and CLIP score, with 4.5-7.7x higher throughput and 6.9-13.4x lower MACs. Our code is open sourced at https://github.com/mit-han-lab/hart.
DuoAttention: Efficient Long-Context LLM Inference with Retrieval and Streaming Heads
Oct 14, 2024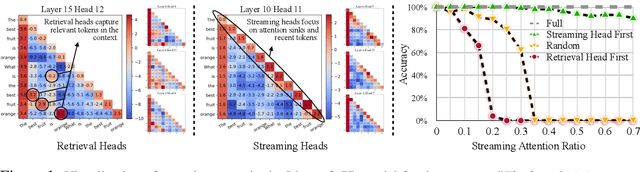
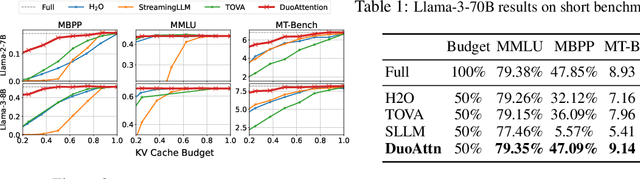
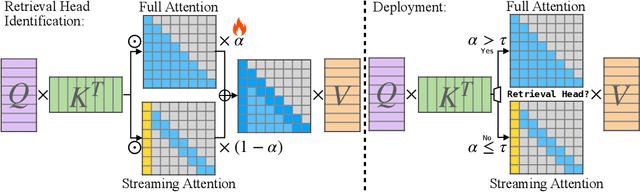

Deploying long-context large language models (LLMs) is essential but poses significant computational and memory challenges. Caching all Key and Value (KV) states across all attention heads consumes substantial memory. Existing KV cache pruning methods either damage the long-context capabilities of LLMs or offer only limited efficiency improvements. In this paper, we identify that only a fraction of attention heads, a.k.a, Retrieval Heads, are critical for processing long contexts and require full attention across all tokens. In contrast, all other heads, which primarily focus on recent tokens and attention sinks--referred to as Streaming Heads--do not require full attention. Based on this insight, we introduce DuoAttention, a framework that only applies a full KV cache to retrieval heads while using a light-weight, constant-length KV cache for streaming heads, which reduces both LLM's decoding and pre-filling memory and latency without compromising its long-context abilities. DuoAttention uses a lightweight, optimization-based algorithm with synthetic data to identify retrieval heads accurately. Our method significantly reduces long-context inference memory by up to 2.55x for MHA and 1.67x for GQA models while speeding up decoding by up to 2.18x and 1.50x and accelerating pre-filling by up to 1.73x and 1.63x for MHA and GQA models, respectively, with minimal accuracy loss compared to full attention. Notably, combined with quantization, DuoAttention enables Llama-3-8B decoding with 3.3 million context length on a single A100 GPU. Code is provided in https://github.com/mit-han-lab/duo-attention.
VILA-U: a Unified Foundation Model Integrating Visual Understanding and Generation
Sep 06, 2024


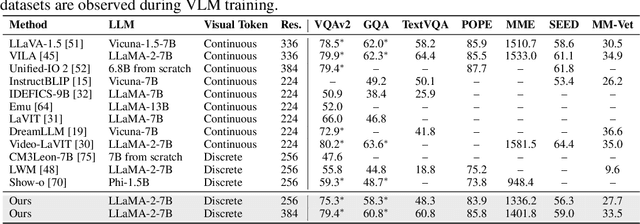
VILA-U is a Unified foundation model that integrates Video, Image, Language understanding and generation. Traditional visual language models (VLMs) use separate modules for understanding and generating visual content, which can lead to misalignment and increased complexity. In contrast, VILA-U employs a single autoregressive next-token prediction framework for both tasks, eliminating the need for additional components like diffusion models. This approach not only simplifies the model but also achieves near state-of-the-art performance in visual language understanding and generation. The success of VILA-U is attributed to two main factors: the unified vision tower that aligns discrete visual tokens with textual inputs during pretraining, which enhances visual perception, and autoregressive image generation can achieve similar quality as diffusion models with high-quality dataset. This allows VILA-U to perform comparably to more complex models using a fully token-based autoregressive framework.
LongVILA: Scaling Long-Context Visual Language Models for Long Videos
Aug 21, 2024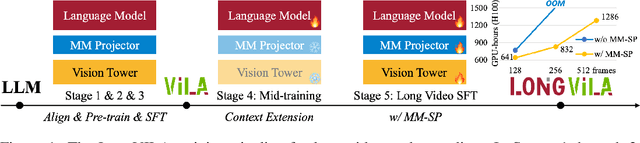

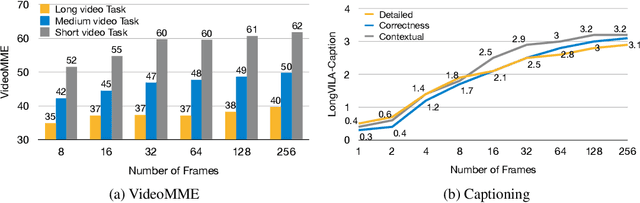
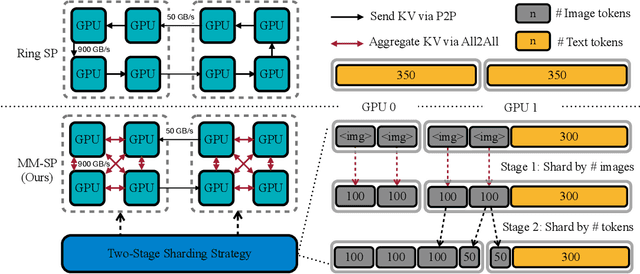
Long-context capability is critical for multi-modal foundation models, especially for long video understanding. We introduce LongVILA, a full-stack solution for long-context visual-language models by co-designing the algorithm and system. For model training, we upgrade existing VLMs to support long video understanding by incorporating two additional stages, i.e., long context extension and long supervised fine-tuning. However, training on long video is computationally and memory intensive. We introduce the long-context Multi-Modal Sequence Parallelism (MM-SP) system that efficiently parallelizes long video training and inference, enabling 2M context length training on 256 GPUs without any gradient checkpointing. LongVILA efficiently extends the number of video frames of VILA from 8 to 1024, improving the long video captioning score from 2.00 to 3.26 (out of 5), achieving 99.5% accuracy in 1400-frame (274k context length) video needle-in-a-haystack. LongVILA-8B demonstrates consistent accuracy improvements on long videos in the VideoMME benchmark as the number of frames increases. Besides, MM-SP is 2.1x - 5.7x faster than ring sequence parallelism and 1.1x - 1.4x faster than Megatron with context parallelism + tensor parallelism. Moreover, it seamlessly integrates with Hugging Face Transformers.