 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVER-Bench: Evaluating MLLMs on Reasoning with Fine-Grained Visual Evidence
Aug 06, 2025With the rapid development of MLLMs, evaluating their visual capabilities has become increasingly crucial. Current benchmarks primarily fall into two main types: basic perception benchmarks, which focus on local details but lack deep reasoning (e.g., "what is in the image?"), and mainstream reasoning benchmarks, which concentrate on prominent image elements but may fail to assess subtle clues requiring intricate analysis. However, profound visual understanding and complex reasoning depend more on interpreting subtle, inconspicuous local details than on perceiving salient, macro-level objects. These details, though occupying minimal image area, often contain richer, more critical information for robust analysis. To bridge this gap, we introduce the VER-Bench, a novel framework to evaluate MLLMs' ability to: 1) identify fine-grained visual clues, often occupying on average just 0.25% of the image area; 2) integrate these clues with world knowledge for complex reasoning. Comprising 374 carefully designed questions across Geospatial, Temporal, Situational, Intent, System State, and Symbolic reasoning, each question in VER-Bench is accompanied by structured evidence: visual clues and question-related reasoning derived from them. VER-Bench reveals current models' limitations in extracting subtle visual evidence and constructing evidence-based arguments, highlighting the need to enhance models's capabilities in fine-grained visual evidence extraction, integration, and reasoning for genuine visual understanding and human-like analysis. Dataset and additional materials are available https://github.com/verbta/ACMMM-25-Materials.
USAD: An Unsupervised Data Augmentation Spatio-Temporal Attention Diffusion Network
Jul 03, 2025The primary objective of human activity recognition (HAR) is to infer ongoing human actions from sensor data, a task that finds broad applications in health monitoring, safety protection, and sports analysis. Despite proliferating research, HAR still faces key challenges, including the scarcity of labeled samples for rare activities, insufficient extraction of high-level features, and suboptimal model performance on lightweight devices. To address these issues, this paper proposes a comprehensive optimization approach centered on multi-attention interaction mechanisms. First, an unsupervised, statistics-guided diffusion model is employed to perform data augmentation, thereby alleviating the problems of labeled data scarcity and severe class imbalance. Second, a multi-branch spatio-temporal interaction network is designed, which captures multi-scale features of sequential data through parallel residual branches with 3*3, 5*5, and 7*7 convolutional kernels. Simultaneously, temporal attention mechanisms are incorporated to identify critical time points, while spatial attention enhances inter-sensor interactions. A cross-branch feature fusion unit is further introduced to improve the overall feature representation capability. Finally, an adaptive multi-loss function fusion strategy is integrated, allowing for dynamic adjustment of loss weights and overall model optimization. Experimental results on three public datasets, WISDM, PAMAP2, and OPPORTUNITY, demonstrate that the proposed unsupervised data augmentation spatio-temporal attention diffusion network (USAD) achieves accuracies of 98.84%, 93.81%, and 80.92% respectively, significantly outperforming existing approaches. Furthermore, practical deployment on embedded devices verifies the efficiency and feasibility of the proposed method.
CMD-HAR: Cross-Modal Disentanglement for Wearable Human Activity Recognition
Mar 27, 2025Human Activity Recognition (HAR) is a fundamental technology for numerous human - centered intelligent applications. Although deep learning methods have been utilized to accelerate feature extraction, issues such as multimodal data mixing, activity heterogeneity, and complex model deployment remain largely unresolved. The aim of this paper is to address issues such as multimodal data mixing, activity heterogeneity, and complex model deployment in sensor-based human activity recognition. We propose a spatiotemporal attention modal decomposition alignment fusion strategy to tackle the problem of the mixed distribution of sensor data. Key discriminative features of activities are captured through cross-modal spatio-temporal disentangled representation, and gradient modulation is combined to alleviate data heterogeneity. In addition, a wearable deployment simulation system is constructed. We conducted experiments on a large number of public datasets, demonstrating the effectiveness of the model.
FactCG: Enhancing Fact Checkers with Graph-Based Multi-Hop Data
Jan 28, 2025Prior research on training grounded factuality classification models to detect hallucinations in large language models (LLMs) has relied on public natural language inference (NLI) data and synthetic data. However, conventional NLI datasets are not well-suited for document-level reasoning, which is critical for detecting LLM hallucinations. Recent approaches to document-level synthetic data generation involve iteratively removing sentences from documents and annotating factuality using LLM-based prompts. While effective, this method is computationally expensive for long documents and limited by the LLM's capabilities. In this work, we analyze the differences between existing synthetic training data used in state-of-the-art models and real LLM output claims. Based on our findings, we propose a novel approach for synthetic data generation, CG2C, that leverages multi-hop reasoning on context graphs extracted from documents. Our fact checker model, FactCG, demonstrates improved performance with more connected reasoning, using the same backbone models. Experiments show it even outperforms GPT-4-o on the LLM-Aggrefact benchmark with much smaller model size.
Compressed Sensing Inspired User Acquisition for Downlink Integrated Sensing and Communication Transmissions
Jul 01, 2024This paper investigates radar-assisted user acquisition for downlink multi-user multiple-input multiple-output (MIMO) transmission using Orthogonal Frequency Division Multiplexing (OFDM) signals. Specifically, we formulate a concise mathematical model for the user acquisition problem, where each user is characterized by its delay and beamspace response. Therefore, we propose a two-stage method for user acquisition, where the Multiple Signal Classification (MUSIC) algorithm is adopted for delay estimation, and then a least absolute shrinkage and selection operator (LASSO) is applied for estimating the user response in the beamspace. Furthermore, we also provide a comprehensive performance analysis of the considered problem based on the pair-wise error probability (PEP). Particularly, we show that the rank and the geometric mean of non-zero eigenvalues of the squared beamspace difference matrix determines the user acquisition performance. More importantly, we reveal that simultaneously probing multiple beams outperforms concentrating power on a specific beam direction in each time slot under the power constraint, when only limited OFDM symbols are transmitted. Our numerical results confirm our conclusions and also demonstrate a promising acquisition performance of the proposed two-stage method.
ChartReader: A Unified Framework for Chart Derendering and Comprehension without Heuristic Rules
Apr 05, 2023



Charts are a powerful tool for visually conveying complex data, but their comprehension poses a challenge due to the diverse chart types and intricate components. Existing chart comprehension methods suffer from either heuristic rules or an over-reliance on OCR systems, resulting in suboptimal performance. To address these issues, we present ChartReader, a unified framework that seamlessly integrates chart derendering and comprehension tasks. Our approach includes a transformer-based chart component detection module and an extended pre-trained vision-language model for chart-to-X tasks. By learning the rules of charts automatically from annotated datasets, our approach eliminates the need for manual rule-making, reducing effort and enhancing accuracy.~We also introduce a data variable replacement technique and extend the input and position embeddings of the pre-trained model for cross-task training. We evaluate ChartReader on Chart-to-Table, ChartQA, and Chart-to-Text tasks, demonstrating its superiority over existing methods. Our proposed framework can significantly reduce the manual effort involved in chart analysis, providing a step towards a universal chart understanding model. Moreover, our approach offers opportunities for plug-and-play integration with mainstream LLMs such as T5 and TaPas, extending their capability to chart comprehension tasks. The code is available at https://github.com/zhiqic/ChartReader.
GSRFormer: Grounded Situation Recognition Transformer with Alternate Semantic Attention Refinement
Sep 01, 2022
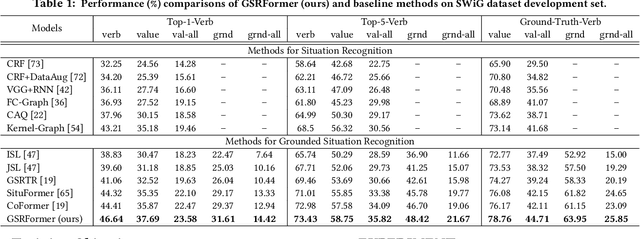

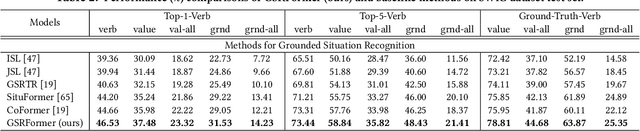
Grounded Situation Recognition (GSR) aims to generate structured semantic summaries of images for "human-like" event understanding. Specifically, GSR task not only detects the salient activity verb (e.g. buying), but also predicts all corresponding semantic roles (e.g. agent and goods). Inspired by object detection and image captioning tasks, existing methods typically employ a two-stage framework: 1) detect the activity verb, and then 2) predict semantic roles based on the detected verb. Obviously, this illogical framework constitutes a huge obstacle to semantic understanding. First, pre-detecting verbs solely without semantic roles inevitably fails to distinguish many similar daily activities (e.g., offering and giving, buying and selling). Second, predicting semantic roles in a closed auto-regressive manner can hardly exploit the semantic relations among the verb and roles. To this end, in this paper we propose a novel two-stage framework that focuses on utilizing such bidirectional relations within verbs and roles. In the first stage, instead of pre-detecting the verb, we postpone the detection step and assume a pseudo label, where an intermediate representation for each corresponding semantic role is learned from images. In the second stage, we exploit transformer layers to unearth the potential semantic relations within both verbs and semantic roles. With the help of a set of support images, an alternate learning scheme is designed to simultaneously optimize the results: update the verb using nouns corresponding to the image, and update nouns using verbs from support images. Extensive experimental results on challenging SWiG benchmarks show that our renovated framework outperforms other state-of-the-art methods under various metrics.
Guiding the Growth: Difficulty-Controllable Question Generation through Step-by-Step Rewriting
May 25, 2021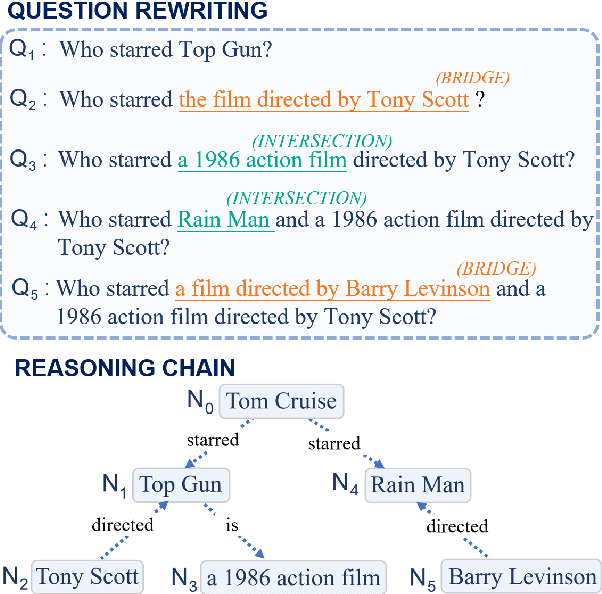
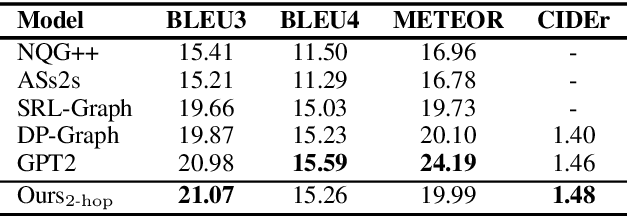
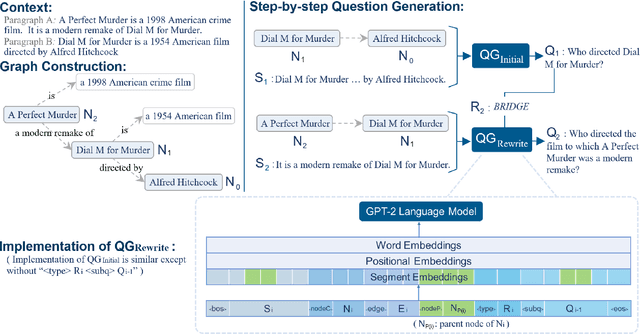

This paper explores the task of Difficulty-Controllable Question Generation (DCQG), which aims at generating questions with required difficulty levels. Previous research on this task mainly defines the difficulty of a question as whether it can be correctly answered by a Question Answering (QA) system, lacking interpretability and controllability. In our work, we redefine question difficulty as the number of inference steps required to answer it and argue that Question Generation (QG) systems should have stronger control over the logic of generated questions. To this end, we propose a novel framework that progressively increases question difficulty through step-by-step rewriting under the guidance of an extracted reasoning chain. A dataset is automatically constructed to facilitate the research, on which extensive experiments are conducted to test the performance of our method.
Detecting Hate Speech in Multi-modal Memes
Dec 29, 2020

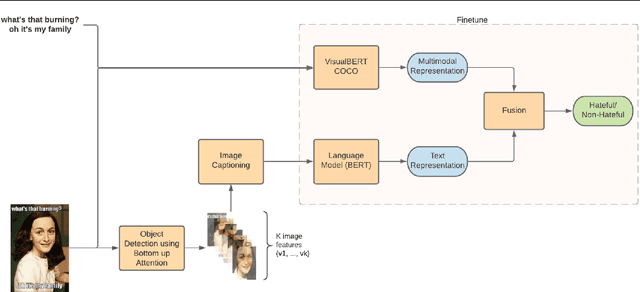
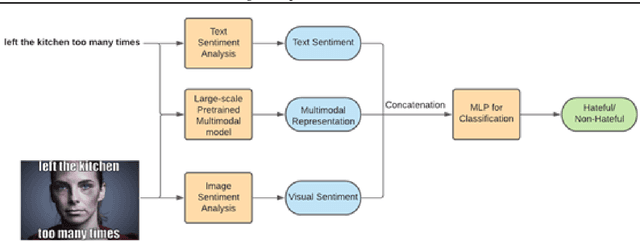
In the past few years, there has been a surge of interest in multi-modal problems, from image captioning to visual question answering and beyond. In this paper, we focus on hate speech detection in multi-modal memes wherein memes pose an interesting multi-modal fusion problem. We aim to solve the Facebook Meme Challenge \cite{kiela2020hateful} which aims to solve a binary classification problem of predicting whether a meme is hateful or not. A crucial characteristic of the challenge is that it includes "benign confounders" to counter the possibility of models exploiting unimodal priors. The challenge states that the state-of-the-art models perform poorly compared to humans. During the analysis of the dataset, we realized that majority of the data points which are originally hateful are turned into benign just be describing the image of the meme. Also, majority of the multi-modal baselines give more preference to the hate speech (language modality). To tackle these problems, we explore the visual modality using object detection and image captioning models to fetch the "actual caption" and then combine it with the multi-modal representation to perform binary classification. This approach tackles the benign text confounders present in the dataset to improve the performance. Another approach we experiment with is to improve the prediction with sentiment analysis. Instead of only using multi-modal representations obtained from pre-trained neural networks, we also include the unimodal sentiment to enrich the features. We perform a detailed analysis of the above two approaches, providing compelling reasons in favor of the methodologies used.
NTIRE 2020 Challenge on Video Quality Mapping: Methods and Results
May 06, 2020

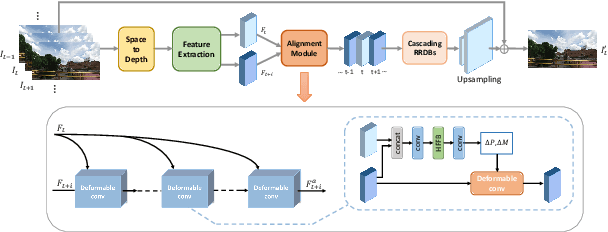
This paper reviews the NTIRE 2020 challenge on video quality mapping (VQM), which addresses the issues of quality mapping from source video domain to target video domain. The challenge includes both a supervised track (track 1) and a weakly-supervised track (track 2) for two benchmark datasets. In particular, track 1 offers a new Internet video benchmark, requiring algorithms to learn the map from more compressed videos to less compressed videos in a supervised training manner. In track 2, algorithms are required to learn the quality mapping from one device to another when their quality varies substantially and weakly-aligned video pairs are available. For track 1, in total 7 teams competed in the final test phase, demonstrating novel and effective solutions to the problem. For track 2, some existing methods are evaluated, showing promising solutions to the weakly-supervised video quality mapping problem.