 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Hate Speech in Multi-modal Memes
Paper and Code
Dec 29, 2020

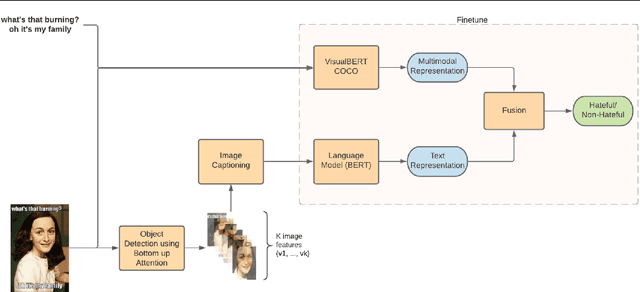
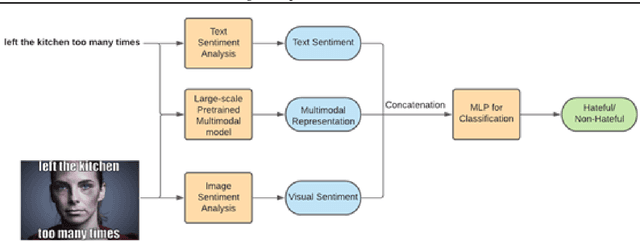
In the past few years, there has been a surge of interest in multi-modal problems, from image captioning to visual question answering and beyond. In this paper, we focus on hate speech detection in multi-modal memes wherein memes pose an interesting multi-modal fusion problem. We aim to solve the Facebook Meme Challenge \cite{kiela2020hateful} which aims to solve a binary classification problem of predicting whether a meme is hateful or not. A crucial characteristic of the challenge is that it includes "benign confounders" to counter the possibility of models exploiting unimodal priors. The challenge states that the state-of-the-art models perform poorly compared to humans. During the analysis of the dataset, we realized that majority of the data points which are originally hateful are turned into benign just be describing the image of the meme. Also, majority of the multi-modal baselines give more preference to the hate speech (language modality). To tackle these problems, we explore the visual modality using object detection and image captioning models to fetch the "actual caption" and then combine it with the multi-modal representation to perform binary classification. This approach tackles the benign text confounders present in the dataset to improve the performance. Another approach we experiment with is to improve the prediction with sentiment analysis. Instead of only using multi-modal representations obtained from pre-trained neural networks, we also include the unimodal sentiment to enrich the features. We perform a detailed analysis of the above two approaches, providing compelling reasons in favor of the methodologies used.