 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2020 Challenge on Video Quality Mapping: Methods and Results
May 06, 2020

This paper reviews the NTIRE 2020 challenge on video quality mapping (VQM), which addresses the issues of quality mapping from source video domain to target video domain. The challenge includes both a supervised track (track 1) and a weakly-supervised track (track 2) for two benchmark datasets. In particular, track 1 offers a new Internet video benchmark, requiring algorithms to learn the map from more compressed videos to less compressed videos in a supervised training manner. In track 2, algorithms are required to learn the quality mapping from one device to another when their quality varies substantially and weakly-aligned video pairs are available. For track 1, in total 7 teams competed in the final test phase, demonstrating novel and effective solutions to the problem. For track 2, some existing methods are evaluated, showing promising solutions to the weakly-supervised video quality mapping problem.
Unsupervised Real-world Image Super Resolution via Domain-distance Aware Training
Apr 02, 2020



These days, unsupervised super-resolution (SR) has been soaring due to its practical and promising potential in real scenarios. The philosophy of off-the-shelf approaches lies in the augmentation of unpaired data, i.e. first generating synthetic low-resolution (LR) images $\mathcal{Y}^g$ corresponding to real-world high-resolution (HR) images $\mathcal{X}^r$ in the real-world LR domain $\mathcal{Y}^r$, and then utilizing the pseudo pairs $\{\mathcal{Y}^g, \mathcal{X}^r\}$ for training in a supervised manner. Unfortunately, since image translation itself is an extremely challenging task, the SR performance of these approaches are severely limited by the domain gap between generated synthetic LR images and real LR images. In this paper, we propose a novel domain-distance aware super-resolution (DASR) approach for unsupervised real-world image SR. The domain gap between training data (e.g. $\mathcal{Y}^g$) and testing data (e.g. $\mathcal{Y}^r$) is addressed with our \textbf{domain-gap aware training} and \textbf{domain-distance weighted supervision} strategies. Domain-gap aware training takes additional benefit from real data in the target domain while domain-distance weighted supervision brings forward the more rational use of labeled source domain data. The proposed method is validated on synthetic and real datasets and the experimental results show that DASR consistently outperforms state-of-the-art unsupervised SR approaches in generating SR outputs with more realistic and natural textures.
Fine-grained Attention and Feature-sharing Generative Adversarial Networks for Single Image Super-Resolution
Nov 25, 2019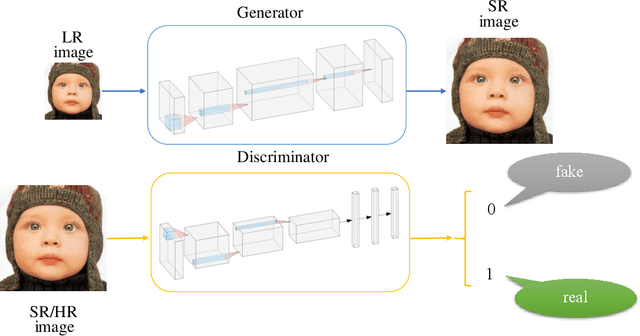
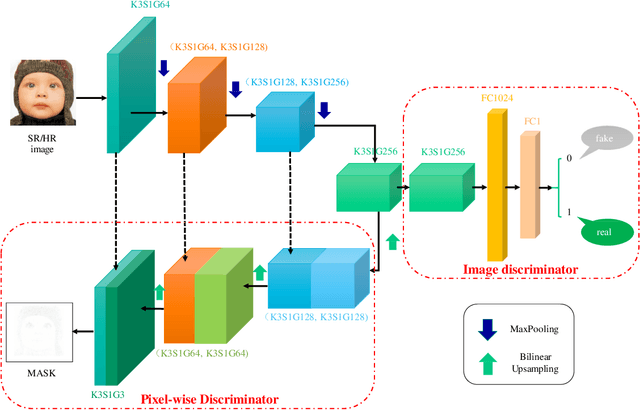
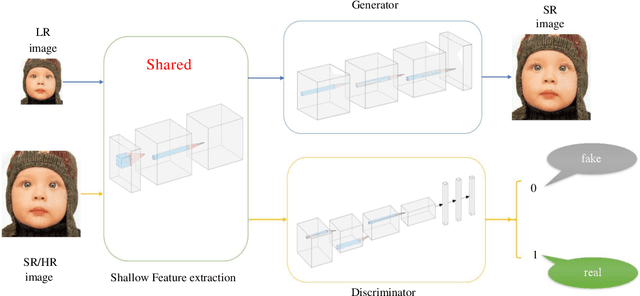
The traditional super-resolution methods that aim to minimize the mean square error usually produce the images with over-smoothed and blurry edges, due to the lose of high-frequency details. In this paper, we propose two novel techniques in the generative adversarial networks to produce photo-realistic images for image super-resolution. Firstly, instead of producing a single score to discriminate images between real and fake, we propose a variant, called Fine-grained Attention Generative Adversarial Network for image super-resolution (FASRGAN), to discriminate each pixel between real and fake. FASRGAN adopts a Unet-like network as the discriminator with two outputs: an image score and an image score map. The score map has the same spatial size as the HR/SR images, serving as the fine-grained attention to represent the degree of reconstruction difficulty for each pixel. Secondly, instead of using different networks for the generator and the discriminator in the SR problem, we use a feature-sharing network (Fs-SRGAN) for both the generator and the discriminator. By network sharing, certain information is shared between the generator and the discriminator, which in turn can improve the ability of producing high-quality images. Quantitative and visual comparisons with the state-of-the-art methods on the benchmark datasets demonstrate the superiority of our methods. The application of super-resolution images to object recognition further proves that the proposed methods endow the power to reconstruction capabilities and the excellent super-resolution effects.
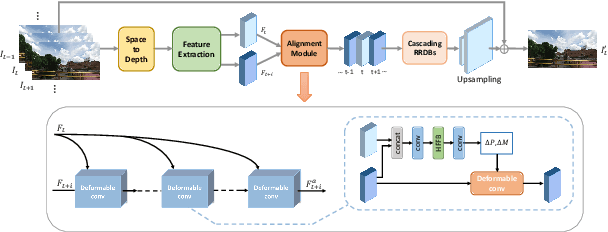
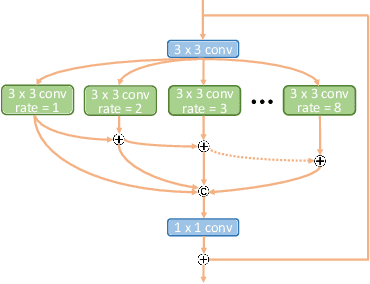
Deformable Non-local Network For Video Super-Resolution
Sep 24, 2019

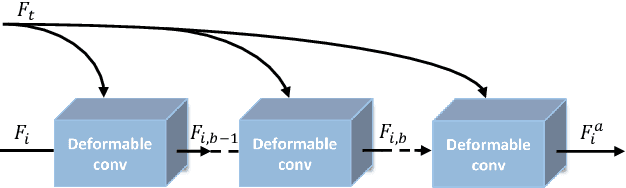
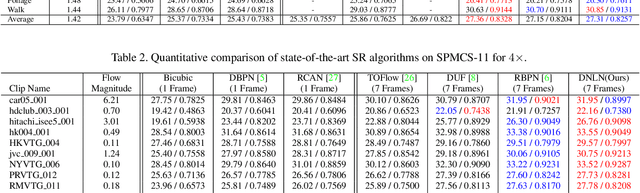
The video super-resolution (VSR) task aims to restore a high-resolution video frame by using its corresponding low-resolution frame and multiple neighboring frames. At present, many deep learning-based VSR methods rely on optical flow to perform frame alignment. The final recovery results will be greatly affected by the accuracy of optical flow. However, optical flow estimation cannot be completely accurate, and there are always some errors. In this paper, we propose a novel deformable non-local network (DNLN) which is non-flow-based. Specifically, we apply the improved deformable convolution in our alignment module to achieve adaptive frame alignment at the feature level. Furthermore, we utilize a non-local module to capture the global correlation between the reference frame and aligned neighboring frame, and simultaneously enhance desired fine details in the aligned frame. To reconstruct the final high-quality HR video frames, we use residual in residual dense blocks to take full advantage of the hierarchical features. Experimental results on several datasets demonstrate that the proposed DNLN can achieve state of the art performance on video super-resolution task.