 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeformable Non-local Network For Video Super-Resolution
Paper and Code
Sep 24, 2019

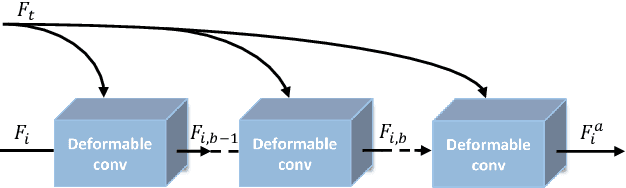
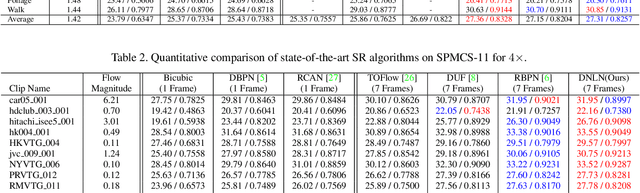
The video super-resolution (VSR) task aims to restore a high-resolution video frame by using its corresponding low-resolution frame and multiple neighboring frames. At present, many deep learning-based VSR methods rely on optical flow to perform frame alignment. The final recovery results will be greatly affected by the accuracy of optical flow. However, optical flow estimation cannot be completely accurate, and there are always some errors. In this paper, we propose a novel deformable non-local network (DNLN) which is non-flow-based. Specifically, we apply the improved deformable convolution in our alignment module to achieve adaptive frame alignment at the feature level. Furthermore, we utilize a non-local module to capture the global correlation between the reference frame and aligned neighboring frame, and simultaneously enhance desired fine details in the aligned frame. To reconstruct the final high-quality HR video frames, we use residual in residual dense blocks to take full advantage of the hierarchical features. Experimental results on several datasets demonstrate that the proposed DNLN can achieve state of the art performance on video super-resolution task.