 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactCG: Enhancing Fact Checkers with Graph-Based Multi-Hop Data
Jan 28, 2025Prior research on training grounded factuality classification models to detect hallucinations in large language models (LLMs) has relied on public natural language inference (NLI) data and synthetic data. However, conventional NLI datasets are not well-suited for document-level reasoning, which is critical for detecting LLM hallucinations. Recent approaches to document-level synthetic data generation involve iteratively removing sentences from documents and annotating factuality using LLM-based prompts. While effective, this method is computationally expensive for long documents and limited by the LLM's capabilities. In this work, we analyze the differences between existing synthetic training data used in state-of-the-art models and real LLM output claims. Based on our findings, we propose a novel approach for synthetic data generation, CG2C, that leverages multi-hop reasoning on context graphs extracted from documents. Our fact checker model, FactCG, demonstrates improved performance with more connected reasoning, using the same backbone models. Experiments show it even outperforms GPT-4-o on the LLM-Aggrefact benchmark with much smaller model size.
InvisMark: Invisible and Robust Watermarking for AI-generated Image Provenance
Nov 19, 2024



The proliferation of AI-generated images has intensified the need for robust content authentication methods. We present InvisMark, a novel watermarking technique designed for high-resolution AI-generated images. Our approach leverages advanced neural network architectures and training strategies to embed imperceptible yet highly robust watermarks. InvisMark achieves state-of-the-art performance in imperceptibility (PSNR$\sim$51, SSIM $\sim$ 0.998) while maintaining over 97\% bit accuracy across various image manipulations. Notably, we demonstrate the successful encoding of 256-bit watermarks, significantly expanding payload capacity while preserving image quality. This enables the embedding of UUIDs with error correction codes, achieving near-perfect decoding success rates even under challenging image distortions. We also address potential vulnerabilities against advanced attacks and propose mitigation strategies. By combining high imperceptibility, extended payload capacity, and resilience to manipulations, InvisMark provides a robust foundation for ensuring media provenance in an era of increasingly sophisticated AI-generated content. Source code of this paper is available at: https://github.com/microsoft/InvisMark.
SLM Meets LLM: Balancing Latency, Interpretability and Consistency in Hallucination Detection
Aug 22, 2024
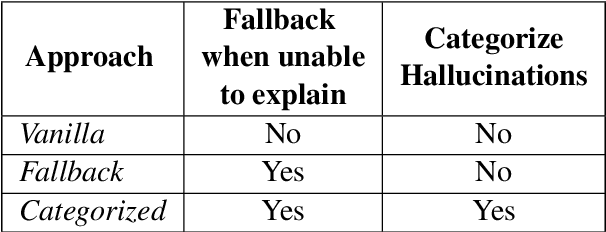


Large language models (LLMs) are highly capable but face latency challenges in real-time applications, such as conducting online hallucination detection. To overcome this issue, we propose a novel framework that leverages a small language model (SLM) classifier for initial detection, followed by a LLM as constrained reasoner to generate detailed explanations for detected hallucinated content. This study optimizes the real-time interpretable hallucination detection by introducing effective prompting techniques that align LLM-generated explanations with SLM decisions. Empirical experiment results demonstrate its effectiveness, thereby enhancing the overall user experience.
Chain of Natural Language Inference for Reducing Large Language Model Ungrounded Hallucinations
Oct 09, 2023Large language models (LLMs) can generate fluent natural language texts when given relevant documents as background context. This ability has attracted considerable interest in developing industry applications of LLMs. However, LLMs are prone to generate hallucinations that are not supported by the provided sources. In this paper, we propose a hierarchical framework to detect and mitigate such ungrounded hallucination. Our framework uses Chain of Natural Language Inference (CoNLI) for hallucination detection and hallucination reduction via post-editing. Our approach achieves state-of-the-art performance on hallucination detection and enhances text quality through rewrite, using LLMs without any fine-tuning or domain-specific prompt engineering. We show that this simple plug-and-play framework can serve as an effective choice for hallucination detection and reduction, achieving competitive performance across various contexts.