Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLM Meets LLM: Balancing Latency, Interpretability and Consistency in Hallucination Detection
Paper and Code

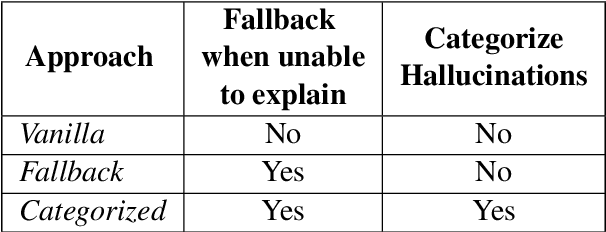


Large language models (LLMs) are highly capable but face latency challenges in real-time applications, such as conducting online hallucination detection. To overcome this issue, we propose a novel framework that leverages a small language model (SLM) classifier for initial detection, followed by a LLM as constrained reasoner to generate detailed explanations for detected hallucinated content. This study optimizes the real-time interpretable hallucination detection by introducing effective prompting techniques that align LLM-generated explanations with SLM decisions. Empirical experiment results demonstrate its effectiveness, thereby enhancing the overall user experience.
* preprint under review
View paper on