 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAime: Towards Fully-Autonomous Multi-Agent Framework
Jul 16, 2025Multi-Agent Systems (MAS) powered by Large Language Models (LLMs) are emerging as a powerful paradigm for solving complex, multifaceted problems. However, the potential of these systems is often constrained by the prevalent plan-and-execute framework, which suffers from critical limitations: rigid plan execution, static agent capabilities, and inefficient communication. These weaknesses hinder their adaptability and robustness in dynamic environments. This paper introduces Aime, a novel multi-agent framework designed to overcome these challenges through dynamic, reactive planning and execution. Aime replaces the conventional static workflow with a fluid and adaptive architecture. Its core innovations include: (1) a Dynamic Planner that continuously refines the overall strategy based on real-time execution feedback; (2) an Actor Factory that implements Dynamic Actor instantiation, assembling specialized agents on-demand with tailored tools and knowledge; and (3) a centralized Progress Management Module that serves as a single source of truth for coherent, system-wide state awareness. We empirically evaluated Aime on a diverse suite of benchmarks spanning general reasoning (GAIA), software engineering (SWE-bench Verified), and live web navigation (WebVoyager). The results demonstrate that Aime consistently outperforms even highly specialized state-of-the-art agents in their respective domains. Its superior adaptability and task success rate establish Aime as a more resilient and effective foundation for multi-agent collaboration.
FactCG: Enhancing Fact Checkers with Graph-Based Multi-Hop Data
Jan 28, 2025Prior research on training grounded factuality classification models to detect hallucinations in large language models (LLMs) has relied on public natural language inference (NLI) data and synthetic data. However, conventional NLI datasets are not well-suited for document-level reasoning, which is critical for detecting LLM hallucinations. Recent approaches to document-level synthetic data generation involve iteratively removing sentences from documents and annotating factuality using LLM-based prompts. While effective, this method is computationally expensive for long documents and limited by the LLM's capabilities. In this work, we analyze the differences between existing synthetic training data used in state-of-the-art models and real LLM output claims. Based on our findings, we propose a novel approach for synthetic data generation, CG2C, that leverages multi-hop reasoning on context graphs extracted from documents. Our fact checker model, FactCG, demonstrates improved performance with more connected reasoning, using the same backbone models. Experiments show it even outperforms GPT-4-o on the LLM-Aggrefact benchmark with much smaller model size.
InvisMark: Invisible and Robust Watermarking for AI-generated Image Provenance
Nov 19, 2024



The proliferation of AI-generated images has intensified the need for robust content authentication methods. We present InvisMark, a novel watermarking technique designed for high-resolution AI-generated images. Our approach leverages advanced neural network architectures and training strategies to embed imperceptible yet highly robust watermarks. InvisMark achieves state-of-the-art performance in imperceptibility (PSNR$\sim$51, SSIM $\sim$ 0.998) while maintaining over 97\% bit accuracy across various image manipulations. Notably, we demonstrate the successful encoding of 256-bit watermarks, significantly expanding payload capacity while preserving image quality. This enables the embedding of UUIDs with error correction codes, achieving near-perfect decoding success rates even under challenging image distortions. We also address potential vulnerabilities against advanced attacks and propose mitigation strategies. By combining high imperceptibility, extended payload capacity, and resilience to manipulations, InvisMark provides a robust foundation for ensuring media provenance in an era of increasingly sophisticated AI-generated content. Source code of this paper is available at: https://github.com/microsoft/InvisMark.
SLM Meets LLM: Balancing Latency, Interpretability and Consistency in Hallucination Detection
Aug 22, 2024
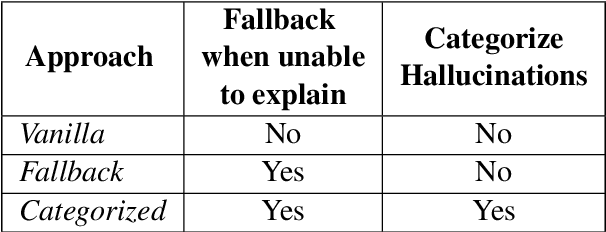


Large language models (LLMs) are highly capable but face latency challenges in real-time applications, such as conducting online hallucination detection. To overcome this issue, we propose a novel framework that leverages a small language model (SLM) classifier for initial detection, followed by a LLM as constrained reasoner to generate detailed explanations for detected hallucinated content. This study optimizes the real-time interpretable hallucination detection by introducing effective prompting techniques that align LLM-generated explanations with SLM decisions. Empirical experiment results demonstrate its effectiveness, thereby enhancing the overall user experience.
Group Distributionally Robust Dataset Distillation with Risk Minimization
Feb 07, 2024



Dataset distillation (DD) has emerged as a widely adopted technique for crafting a synthetic dataset that captures the essential information of a training dataset, facilitating the training of accurate neural models. Its applications span various domains, including transfer learning, federated learning, and neural architecture search. The most popular methods for constructing the synthetic data rely on matching the convergence properties of training the model with the synthetic dataset and the training dataset. However, targeting the training dataset must be thought of as auxiliary in the same sense that the training set is an approximate substitute for the population distribution, and the latter is the data of interest. Yet despite its popularity, an aspect that remains unexplored is the relationship of DD to its generalization, particularly across uncommon subgroups. That is, how can we ensure that a model trained on the synthetic dataset performs well when faced with samples from regions with low population density? Here, the representativeness and coverage of the dataset become salient over the guaranteed training error at inference. Drawing inspiration from distributionally robust optimization, we introduce an algorithm that combines clustering with the minimization of a risk measure on the loss to conduct DD. We provide a theoretical rationale for our approach and demonstrate its effective generalization and robustness across subgroups through numerical experiments.
Self-Supervised Bird's Eye View Motion Prediction with Cross-Modality Signals
Jan 21, 2024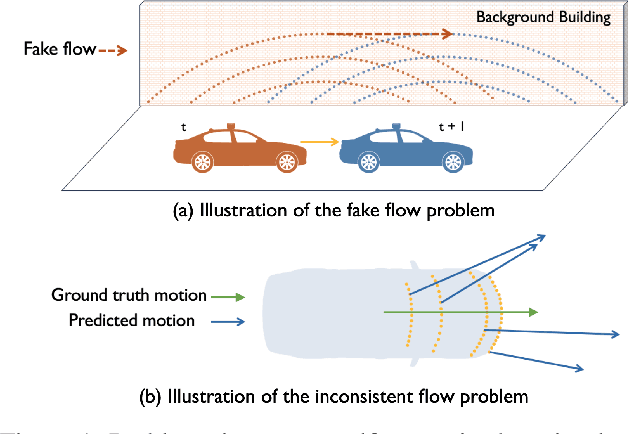
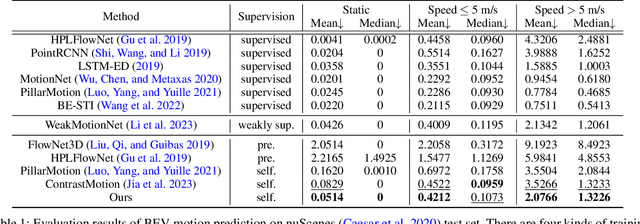
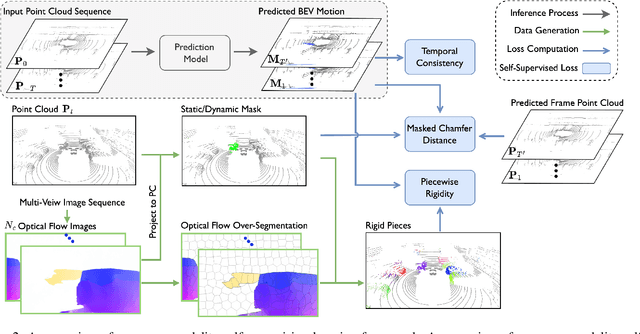
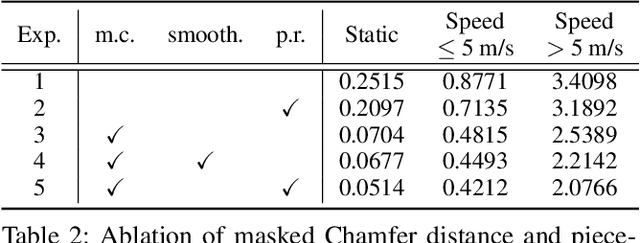
Learning the dense bird's eye view (BEV) motion flow in a self-supervised manner is an emerging research for robotics and autonomous driving. Current self-supervised methods mainly rely on point correspondences between point clouds, which may introduce the problems of fake flow and inconsistency, hindering the model's ability to learn accurate and realistic motion. In this paper, we introduce a novel cross-modality self-supervised training framework that effectively addresses these issues by leveraging multi-modality data to obtain supervision signals. We design three innovative supervision signals to preserve the inherent properties of scene motion, including the masked Chamfer distance loss, the piecewise rigidity loss, and the temporal consistency loss. Through extensive experiments, we demonstrate that our proposed self-supervised framework outperforms all previous self-supervision methods for the motion prediction task.
Chain of Natural Language Inference for Reducing Large Language Model Ungrounded Hallucinations
Oct 09, 2023Large language models (LLMs) can generate fluent natural language texts when given relevant documents as background context. This ability has attracted considerable interest in developing industry applications of LLMs. However, LLMs are prone to generate hallucinations that are not supported by the provided sources. In this paper, we propose a hierarchical framework to detect and mitigate such ungrounded hallucination. Our framework uses Chain of Natural Language Inference (CoNLI) for hallucination detection and hallucination reduction via post-editing. Our approach achieves state-of-the-art performance on hallucination detection and enhances text quality through rewrite, using LLMs without any fine-tuning or domain-specific prompt engineering. We show that this simple plug-and-play framework can serve as an effective choice for hallucination detection and reduction, achieving competitive performance across various contexts.
Game-Theoretic Planning for Autonomous Driving among Risk-Aware Human Drivers
May 01, 2022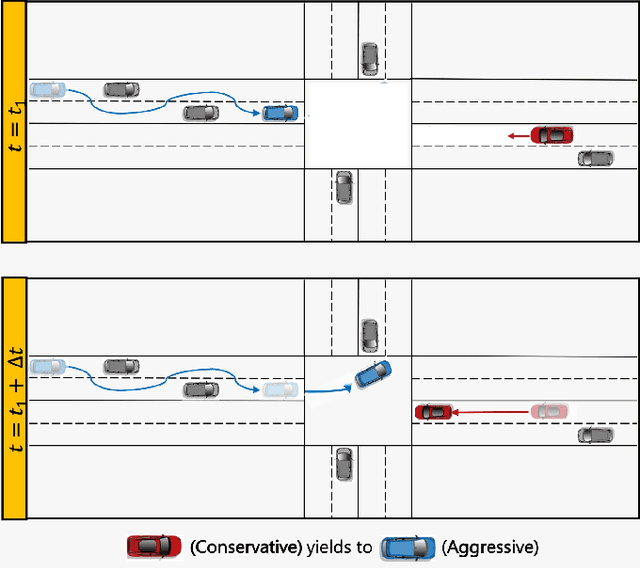


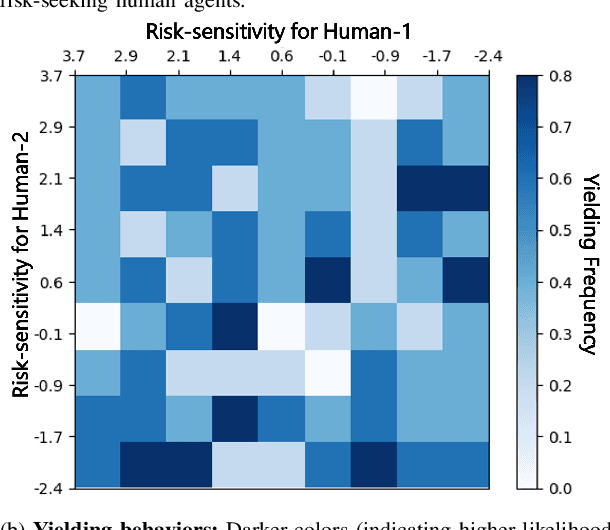
We present a novel approach for risk-aware planning with human agents in multi-agent traffic scenarios. Our approach takes into account the wide range of human driver behaviors on the road, from aggressive maneuvers like speeding and overtaking, to conservative traits like driving slowly and conforming to the right-most lane. In our approach, we learn a mapping from a data-driven human driver behavior model called the CMetric to a driver's entropic risk preference. We then use the derived risk preference within a game-theoretic risk-sensitive planner to model risk-aware interactions among human drivers and an autonomous vehicle in various traffic scenarios. We demonstrate our method in a merging scenario, where our results show that the final trajectories obtained from the risk-aware planner generate desirable emergent behaviors. Particularly, our planner recognizes aggressive human drivers and yields to them while maintaining a greater distance from them. In a user study, participants were able to distinguish between aggressive and conservative simulated drivers based on trajectories generated from our risk-sensitive planner. We also observe that aggressive human driving results in more frequent lane-changing in the planner. Finally, we compare the performance of our modified risk-aware planner with existing methods and show that modeling human driver behavior leads to safer navigation.
Maximum-Entropy Multi-Agent Dynamic Games: Forward and Inverse Solutions
Oct 03, 2021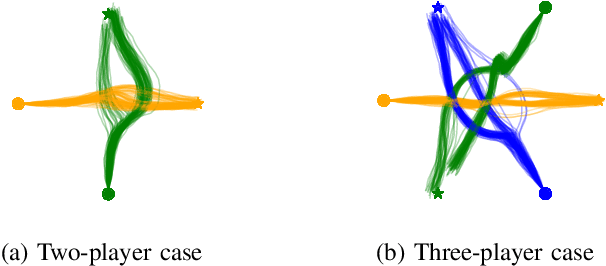


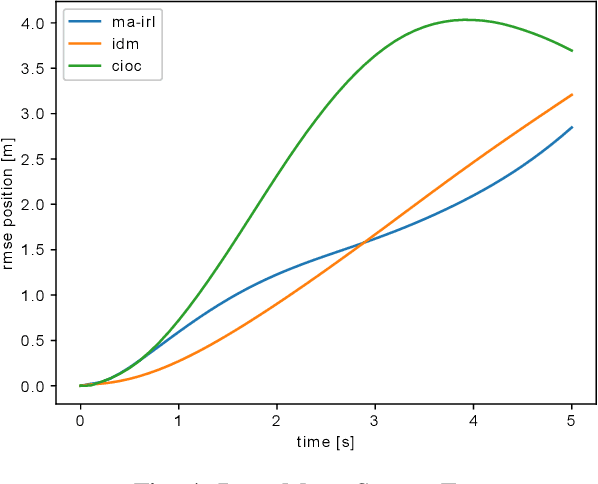
In this paper, we study the problem of multiple stochastic agents interacting in a dynamic game scenario with continuous state and action spaces. We define a new notion of stochastic Nash equilibrium for boundedly rational agents, which we call the Entropic Cost Equilibrium (ECE). We show that ECE is a natural extension to multiple agents of Maximum Entropy optimality for single agents. We solve both the "forward" and "inverse" problems for the multi-agent ECE game. For the forward problem, we provide a Riccati algorithm to compute closed-form ECE feedback policies for the agents, which are exact in the Linear-Quadratic-Gaussian case. We give an iterative variant to find locally ECE feedback policies for the nonlinear case. For the inverse problem, we present an algorithm to infer the cost functions of the multiple interacting agents given noisy, boundedly rational input and state trajectory examples from agents acting in an ECE. The effectiveness of our algorithms is demonstrated in a simulated multi-agent collision avoidance scenario, and with data from the INTERACTION traffic dataset. In both cases, we show that, by taking into account the agents' game theoretic interactions using our algorithm, a more accurate model of agents' costs can be learned, compared with standard inverse optimal control methods.
Directional Primitives for Uncertainty-Aware Motion Estimation in Urban Environments
Jul 01, 2020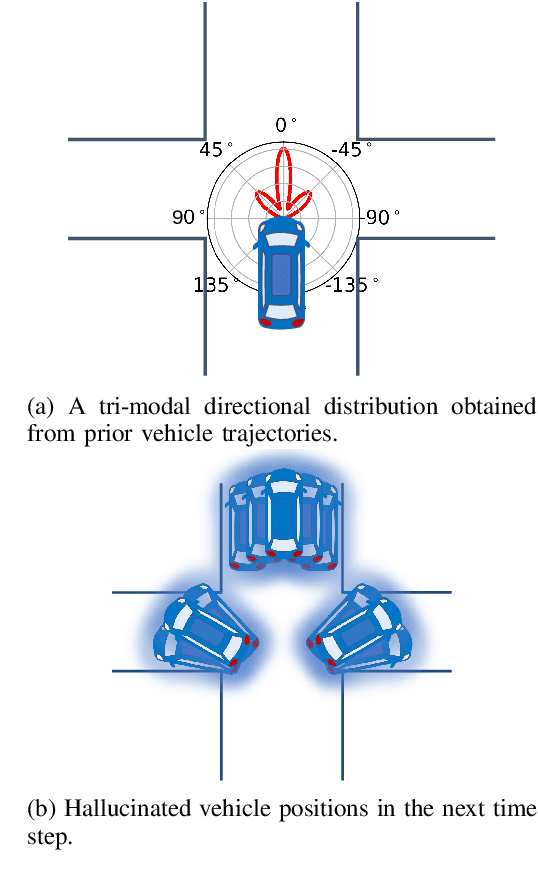
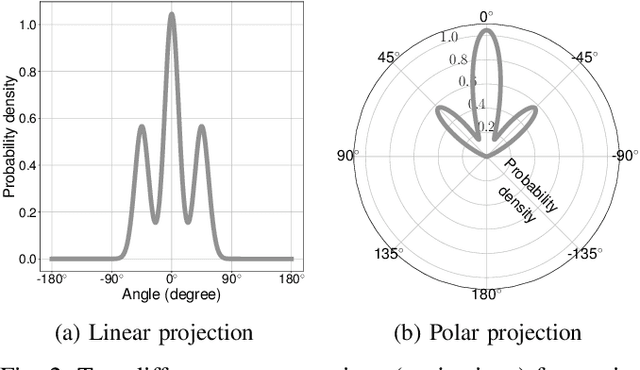
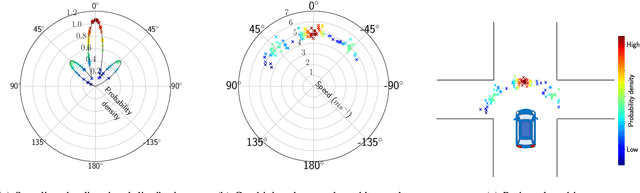
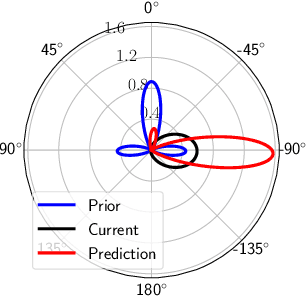
We can use driving data collected over a long period of time to extract rich information about how vehicles behave in different areas of the roads. In this paper, we introduce the concept of directional primitives, which is a representation of prior information of road networks. Specifically, we represent the uncertainty of directions using a mixture of von Mises distributions and associated speeds using gamma distributions. These location-dependent primitives can be combined with motion information of surrounding vehicles to predict their future behavior in the form of probability distributions. Experiments conducted on highways, intersections, and roundabouts in the Carla simulator, as well as real-world urban driving datasets, indicate that primitives lead to better uncertainty-aware motion estimation.