 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence-driven Gradient Modulation for Multimodal Human Activity Recognition: A Dynamic Contrastive Dual-Path Learning Approach
Jul 03, 2025Sensor-based Human Activity Recognition (HAR) is a core technology that enables intelligent systems to perceive and interact with their environment. However, multimodal HAR systems still encounter key challenges, such as difficulties in cross-modal feature alignment and imbalanced modality contributions. To address these issues, we propose a novel framework called the Dynamic Contrastive Dual-Path Network (DCDP-HAR). The framework comprises three key components. First, a dual-path feature extraction architecture is employed, where ResNet and DenseNet branches collaboratively process multimodal sensor data. Second, a multi-stage contrastive learning mechanism is introduced to achieve progressive alignment from local perception to semantic abstraction. Third, we present a confidence-driven gradient modulation strategy that dynamically monitors and adjusts the learning intensity of each modality branch during backpropagation, effectively alleviating modality competition. In addition, a momentum-based gradient accumulation strategy is adopted to enhance training stability. We conduct ablation studies to validate the effectiveness of each component and perform extensive comparative experiments on four public benchmark datasets.
USAD: An Unsupervised Data Augmentation Spatio-Temporal Attention Diffusion Network
Jul 03, 2025The primary objective of human activity recognition (HAR) is to infer ongoing human actions from sensor data, a task that finds broad applications in health monitoring, safety protection, and sports analysis. Despite proliferating research, HAR still faces key challenges, including the scarcity of labeled samples for rare activities, insufficient extraction of high-level features, and suboptimal model performance on lightweight devices. To address these issues, this paper proposes a comprehensive optimization approach centered on multi-attention interaction mechanisms. First, an unsupervised, statistics-guided diffusion model is employed to perform data augmentation, thereby alleviating the problems of labeled data scarcity and severe class imbalance. Second, a multi-branch spatio-temporal interaction network is designed, which captures multi-scale features of sequential data through parallel residual branches with 3*3, 5*5, and 7*7 convolutional kernels. Simultaneously, temporal attention mechanisms are incorporated to identify critical time points, while spatial attention enhances inter-sensor interactions. A cross-branch feature fusion unit is further introduced to improve the overall feature representation capability. Finally, an adaptive multi-loss function fusion strategy is integrated, allowing for dynamic adjustment of loss weights and overall model optimization. Experimental results on three public datasets, WISDM, PAMAP2, and OPPORTUNITY, demonstrate that the proposed unsupervised data augmentation spatio-temporal attention diffusion network (USAD) achieves accuracies of 98.84%, 93.81%, and 80.92% respectively, significantly outperforming existing approaches. Furthermore, practical deployment on embedded devices verifies the efficiency and feasibility of the proposed method.
CMD-HAR: Cross-Modal Disentanglement for Wearable Human Activity Recognition
Mar 27, 2025Human Activity Recognition (HAR) is a fundamental technology for numerous human - centered intelligent applications. Although deep learning methods have been utilized to accelerate feature extraction, issues such as multimodal data mixing, activity heterogeneity, and complex model deployment remain largely unresolved. The aim of this paper is to address issues such as multimodal data mixing, activity heterogeneity, and complex model deployment in sensor-based human activity recognition. We propose a spatiotemporal attention modal decomposition alignment fusion strategy to tackle the problem of the mixed distribution of sensor data. Key discriminative features of activities are captured through cross-modal spatio-temporal disentangled representation, and gradient modulation is combined to alleviate data heterogeneity. In addition, a wearable deployment simulation system is constructed. We conducted experiments on a large number of public datasets, demonstrating the effectiveness of the model.
Isotropic3D: Image-to-3D Generation Based on a Single CLIP Embedding
Mar 15, 2024Encouraged by the growing availability of pre-trained 2D diffusion models, image-to-3D generation by leveraging Score Distillation Sampling (SDS) is making remarkable progress. Most existing methods combine novel-view lifting from 2D diffusion models which usually take the reference image as a condition while applying hard L2 image supervision at the reference view. Yet heavily adhering to the image is prone to corrupting the inductive knowledge of the 2D diffusion model leading to flat or distorted 3D generation frequently. In this work, we reexamine image-to-3D in a novel perspective and present Isotropic3D, an image-to-3D generation pipeline that takes only an image CLIP embedding as input. Isotropic3D allows the optimization to be isotropic w.r.t. the azimuth angle by solely resting on the SDS loss. The core of our framework lies in a two-stage diffusion model fine-tuning. Firstly, we fine-tune a text-to-3D diffusion model by substituting its text encoder with an image encoder, by which the model preliminarily acquires image-to-image capabilities. Secondly, we perform fine-tuning using our Explicit Multi-view Attention (EMA) which combines noisy multi-view images with the noise-free reference image as an explicit condition. CLIP embedding is sent to the diffusion model throughout the whole process while reference images are discarded once after fine-tuning. As a result, with a single image CLIP embedding, Isotropic3D is capable of generating multi-view mutually consistent images and also a 3D model with more symmetrical and neat content, well-proportioned geometry, rich colored texture, and less distortion compared with existing image-to-3D methods while still preserving the similarity to the reference image to a large extent. The project page is available at https://isotropic3d.github.io/. The code and models are available at https://github.com/pkunliu/Isotropic3D.
StereoScene: BEV-Assisted Stereo Matching Empowers 3D Semantic Scene Completion
Mar 30, 20233D semantic scene completion (SSC) is an ill-posed task that requires inferring a dense 3D scene from incomplete observations. Previous methods either explicitly incorporate 3D geometric input or rely on learnt 3D prior behind monocular RGB images. However, 3D sensors such as LiDAR are expensive and intrusive while monocular cameras face challenges in modeling precise geometry due to the inherent ambiguity. In this work, we propose StereoScene for 3D Semantic Scene Completion (SSC), which explores taking full advantage of light-weight camera inputs without resorting to any external 3D sensors. Our key insight is to leverage stereo matching to resolve geometric ambiguity. To improve its robustness in unmatched areas, we introduce bird's-eye-view (BEV) representation to inspire hallucination ability with rich context information. On top of the stereo and BEV representations, a mutual interactive aggregation (MIA) module is carefully devised to fully unleash their power. Specifically, a Bi-directional Interaction Transformer (BIT) augmented with confidence re-weighting is used to encourage reliable prediction through mutual guidance while a Dual Volume Aggregation (DVA) module is designed to facilitate complementary aggregation. Experimental results on SemanticKITTI demonstrate that the proposed StereoScene outperforms the state-of-the-art camera-based methods by a large margin with a relative improvement of 26.9% in geometry and 38.6% in semantic.
Quasi-genetic algorithms and continuation Newton methods with deflation techniques for global optimization problems
Jul 29, 2021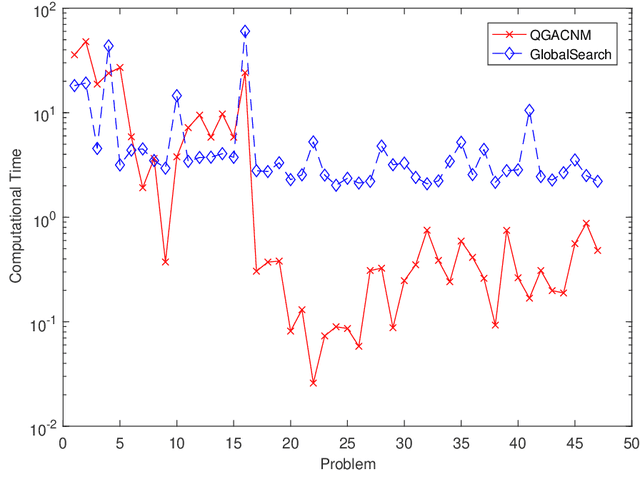
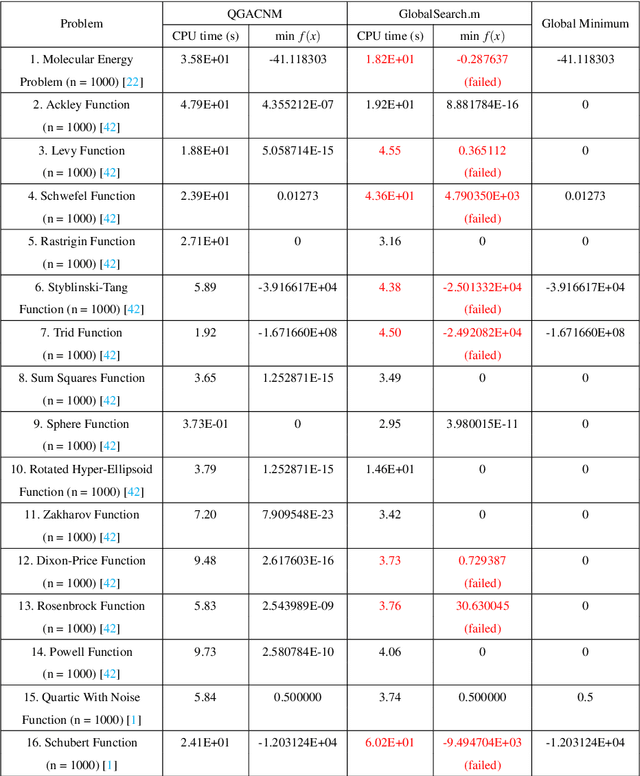
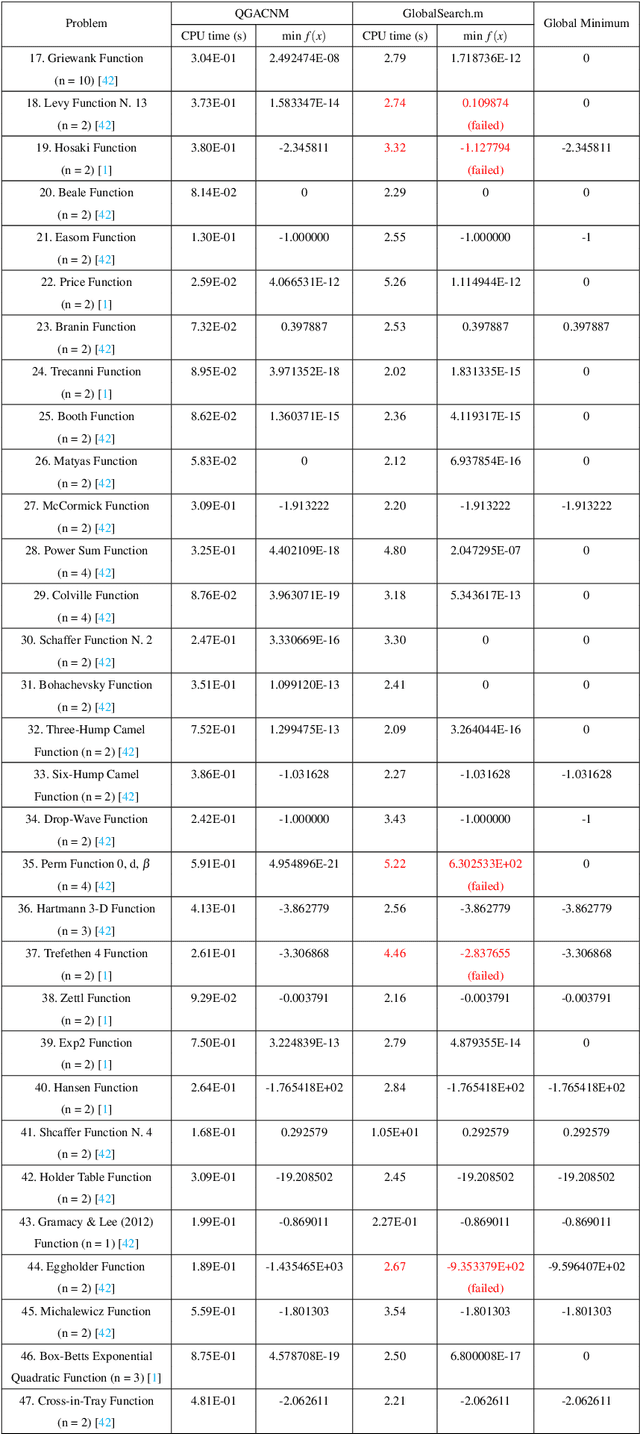
The global minimum point of an optimization problem is of interest in engineering fields and it is difficult to be found, especially for a nonconvex optimization problem. In this article, we consider a quasi-genetic algorithm and the continuation Newton method for this problem. Firstly, we use the continuation Newton method with the deflation technique to find critical points of the objective function as many as possible. Then, we use those critical points as the initial evolutionary seeds of the quasi-genetic algorithm. After evolving into several generations such as twenty generations, we obtain a suboptimal point of the optimization problem. Finally, we use this suboptimal point as the initial point of the continuation Newton method to obtain the critical point of the original objective function, and output the minimizer between this final critical point and the suboptimal point of the quasi-genetic algorithm as the global minimum point of the original optimization problem. Numerical results show that the proposed method is quite reliable to find the global optimal point of the unconstrained optimization problem, compared to the multi-start method (the built-in subroutine GlobalSearch.m of the MATLAB R2020a environment).
Weak target detection with multi-bit quantization in colocated MIMO radar
Jun 07, 2021



We consider the weak target detection problem with unknown parameter in colocated multiple-input multiple-output (MIMO) radar. To cope with the sheer amount of data for large-size systems, a multi-bit quantizer is utilized in the sampling process. As a low-complexity alternative to classic generalized likelihood ratio test (GLRT) for quantized data, we propose the multi-bit detector on Rao test with a closed-form test statistic, whose theoretical asymptotic distribution is provided to generalize the actual detection performance. Besides, we refine the design of quantizer by optimized quantization thresholds, which are obtained resorting to the popular particle swarm optimization algorithmthe (PSOA). The simulation is conducted to demonstrate the performance variations of detectors based on unquantized and quantized data. The numerical results corroborate our theoretical analyses and show that the performance with 3-bit quantization approaches the case without quantization.
Efficient Scene Text Detection with Textual Attention Tower
Jan 30, 2020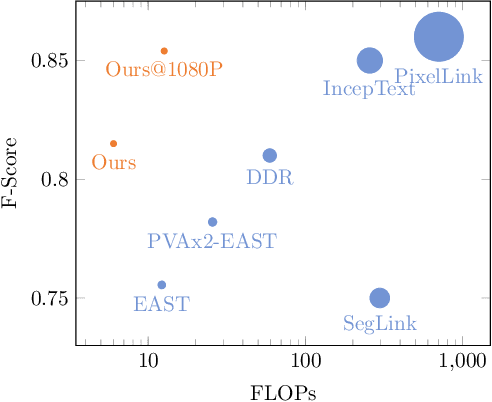
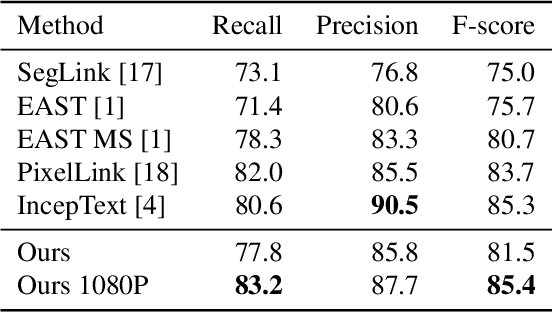


Scene text detection has received attention for years and achieved an impressive performance across various benchmarks. In this work, we propose an efficient and accurate approach to detect multioriented text in scene images. The proposed feature fusion mechanism allows us to use a shallower network to reduce the computational complexity. A self-attention mechanism is adopted to suppress false positive detections. Experiments on public benchmarks including ICDAR 2013, ICDAR 2015 and MSRA-TD500 show that our proposed approach can achieve better or comparable performances with fewer parameters and less computational cost.
Simultaneous Block-Sparse Signal Recovery Using Pattern-Coupled Sparse Bayesian Learning
Nov 06, 2017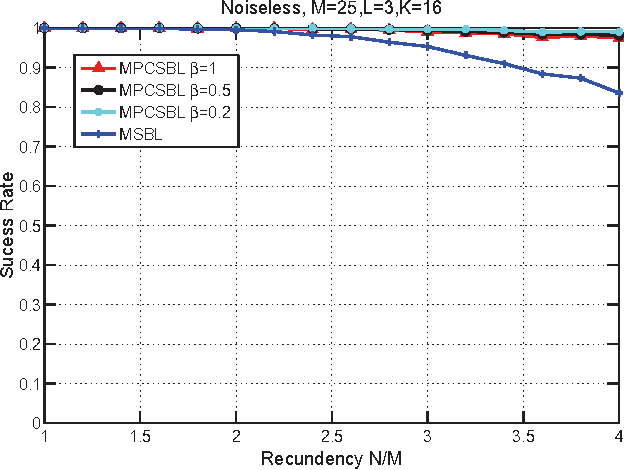
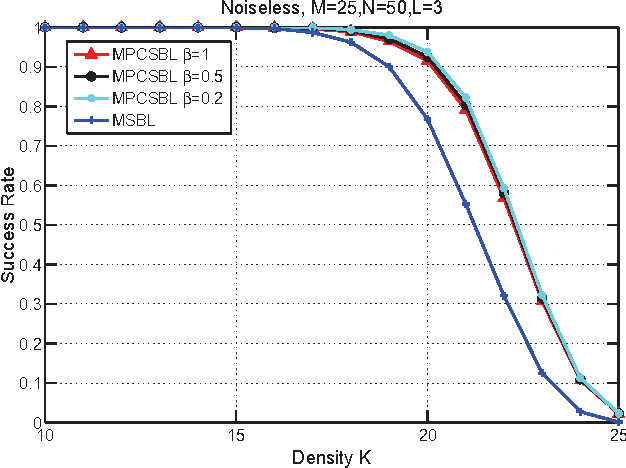
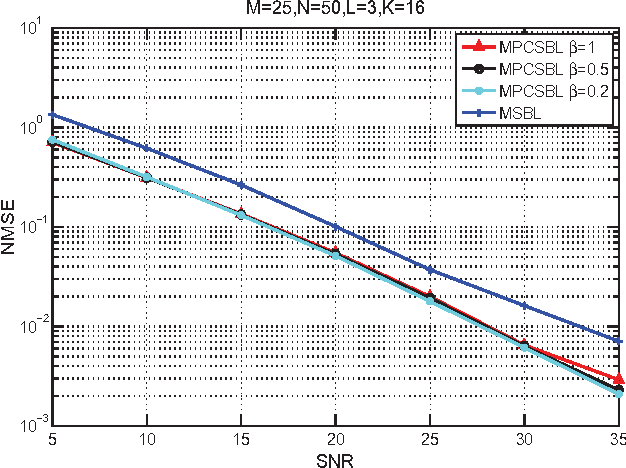
In this paper, we consider the block-sparse signals recovery problem in the context of multiple measurement vectors (MMV) with common row sparsity patterns. We develop a new method for recovery of common row sparsity MMV signals, where a pattern-coupled hierarchical Gaussian prior model is introduced to characterize both the block-sparsity of the coefficients and the statistical dependency between neighboring coefficients of the common row sparsity MMV signals. Unlike many other methods, the proposed method is able to automatically capture the block sparse structure of the unknown signal. Our method is developed using an expectation-maximization (EM) framework. Simulation results show that our proposed method offers competitive performance in recovering block-sparse common row sparsity pattern MMV signals.