 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneTransporter: Optimal Transport-Guided Compositional Latent Diffusion for Single-Image Structured 3D Scene Generation
Feb 26, 2026We introduce SceneTransporter, an end-to-end framework for structured 3D scene generation from a single image. While existing methods generate part-level 3D objects, they often fail to organize these parts into distinct instances in open-world scenes. Through a debiased clustering probe, we reveal a critical insight: this failure stems from the lack of structural constraints within the model's internal assignment mechanism. Based on this finding, we reframe the task of structured 3D scene generation as a global correlation assignment problem. To solve this, SceneTransporter formulates and solves an entropic Optimal Transport (OT) objective within the denoising loop of the compositional DiT model. This formulation imposes two powerful structural constraints. First, the resulting transport plan gates cross-attention to enforce an exclusive, one-to-one routing of image patches to part-level 3D latents, preventing entanglement. Second, the competitive nature of the transport encourages the grouping of similar patches, a process that is further regularized by an edge-based cost, to form coherent objects and prevent fragmentation. Extensive experiments show that SceneTransporter outperforms existing methods on open-world scene generation, significantly improving instance-level coherence and geometric fidelity. Code and models will be publicly available at https://2019epwl.github.io/SceneTransporter/.
Text Semantics to Flexible Design: A Residential Layout Generation Method Based on Stable Diffusion Model
Jan 16, 2025Flexibility in the AI-based residential layout design remains a significant challenge, as traditional methods like rule-based heuristics and graph-based generation often lack flexibility and require substantial design knowledge from users. To address these limitations, we propose a cross-modal design approach based on the Stable Diffusion model for generating flexible residential layouts. The method offers multiple input types for learning objectives, allowing users to specify both boundaries and layouts. It incorporates natural language as design constraints and introduces ControlNet to enable stable layout generation through two distinct pathways. We also present a scheme that encapsulates design expertise within a knowledge graph and translates it into natural language, providing an interpretable representation of design knowledge. This comprehensibility and diversity of input options enable professionals and non-professionals to directly express design requirements, enhancing flexibility and controllability. Finally, experiments verify the flexibility of the proposed methods under multimodal constraints better than state-of-the-art models, even when specific semantic information about room areas or connections is incomplete.
Automated Image-Based Identification and Consistent Classification of Fire Patterns with Quantitative Shape Analysis and Spatial Location Identification
Oct 30, 2024



Fire patterns, consisting of fire effects that offer insights into fire behavior and origin, are traditionally classified based on investigators' visual observations, leading to subjective interpretations. This study proposes a framework for quantitative fire pattern classification to support fire investigators, aiming for consistency and accuracy. The framework integrates four components. First, it leverages human-computer interaction to extract fire patterns from surfaces, combining investigator expertise with computational analysis. Second, it employs an aspect ratio-based random forest model to classify fire pattern shapes. Third, fire scene point cloud segmentation enables precise identification of fire-affected areas and the mapping of 2D fire patterns to 3D scenes. Lastly, spatial relationships between fire patterns and indoor elements support an interpretation of the fire scene. These components provide a method for fire pattern analysis that synthesizes qualitative and quantitative data. The framework's classification results achieve 93% precision on synthetic data and 83% on real fire patterns.
Isotropic3D: Image-to-3D Generation Based on a Single CLIP Embedding
Mar 15, 2024Encouraged by the growing availability of pre-trained 2D diffusion models, image-to-3D generation by leveraging Score Distillation Sampling (SDS) is making remarkable progress. Most existing methods combine novel-view lifting from 2D diffusion models which usually take the reference image as a condition while applying hard L2 image supervision at the reference view. Yet heavily adhering to the image is prone to corrupting the inductive knowledge of the 2D diffusion model leading to flat or distorted 3D generation frequently. In this work, we reexamine image-to-3D in a novel perspective and present Isotropic3D, an image-to-3D generation pipeline that takes only an image CLIP embedding as input. Isotropic3D allows the optimization to be isotropic w.r.t. the azimuth angle by solely resting on the SDS loss. The core of our framework lies in a two-stage diffusion model fine-tuning. Firstly, we fine-tune a text-to-3D diffusion model by substituting its text encoder with an image encoder, by which the model preliminarily acquires image-to-image capabilities. Secondly, we perform fine-tuning using our Explicit Multi-view Attention (EMA) which combines noisy multi-view images with the noise-free reference image as an explicit condition. CLIP embedding is sent to the diffusion model throughout the whole process while reference images are discarded once after fine-tuning. As a result, with a single image CLIP embedding, Isotropic3D is capable of generating multi-view mutually consistent images and also a 3D model with more symmetrical and neat content, well-proportioned geometry, rich colored texture, and less distortion compared with existing image-to-3D methods while still preserving the similarity to the reference image to a large extent. The project page is available at https://isotropic3d.github.io/. The code and models are available at https://github.com/pkunliu/Isotropic3D.
AnimatableDreamer: Text-Guided Non-rigid 3D Model Generation and Reconstruction with Canonical Score Distillation
Dec 20, 2023
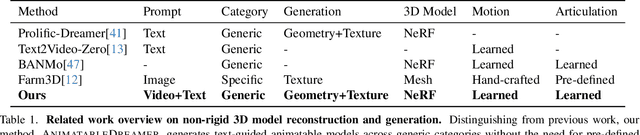


Text-to-3D model adaptations have advanced static 3D model quality, but sequential 3D model generation, particularly for animatable objects with large motions, is still scarce. Our work proposes AnimatableDreamer, a text-to-4D generation framework capable of generating diverse categories of non-rigid objects while adhering to the object motions extracted from a monocular video. At its core, AnimatableDreamer is equipped with our novel optimization design dubbed Canonical Score Distillation (CSD), which simplifies the generation dimension from 4D to 3D by denoising over different frames in the time-varying camera spaces while conducting the distillation process in a unique canonical space shared per video. Concretely, CSD ensures that score gradients back-propagate to the canonical space through differentiable warping, hence guaranteeing the time-consistent generation and maintaining morphological plausibility across different poses. By lifting the 3D generator to 4D with warping functions, AnimatableDreamer offers a novel perspective on non-rigid 3D model generation and reconstruction. Besides, with inductive knowledge from a multi-view consistent diffusion model, CSD regularizes reconstruction from novel views, thus cyclically enhancing the generation process. Extensive experiments demonstrate the capability of our method in generating high-flexibility text-guided 3D models from the monocular video, while also showing improved reconstruction performance over typical non-rigid reconstruction methods. Project page https://AnimatableDreamer.github.io.
SNF: Filter Pruning via Searching the Proper Number of Filters
Dec 14, 2021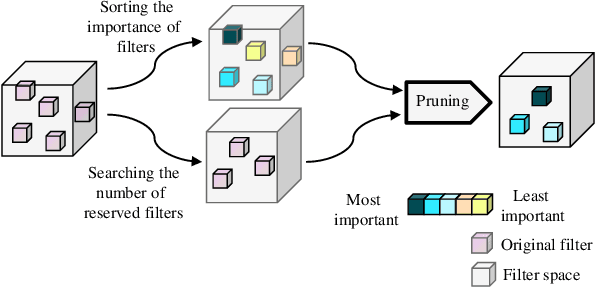
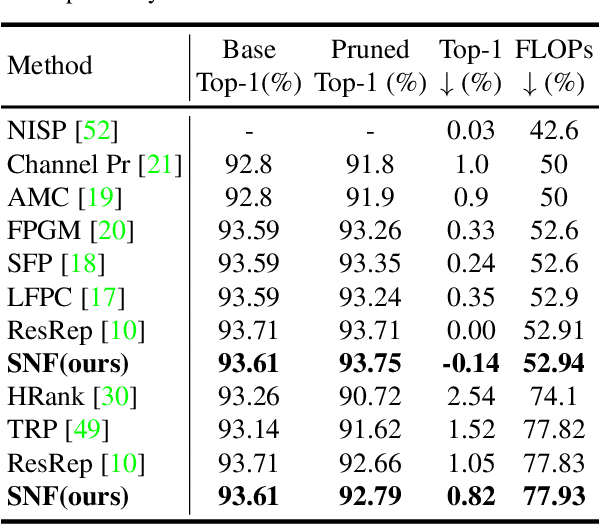
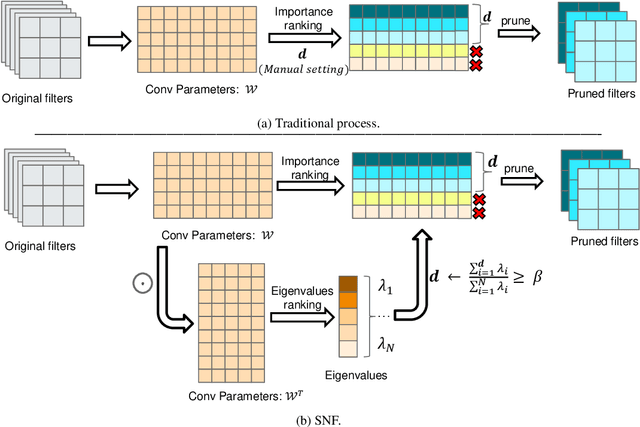
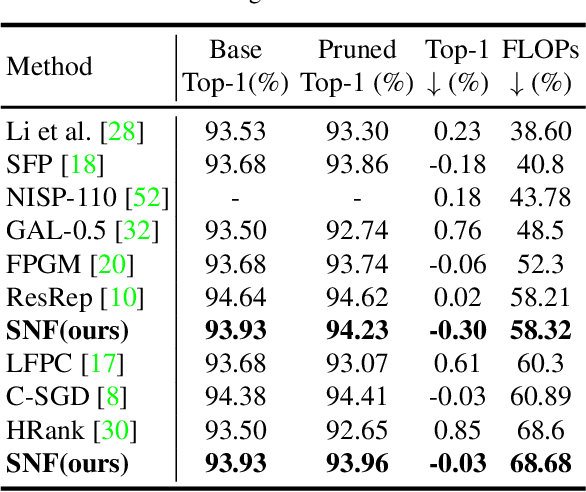
Convolutional Neural Network (CNN) has an amount of parameter redundancy, filter pruning aims to remove the redundant filters and provides the possibility for the application of CNN on terminal devices. However, previous works pay more attention to designing evaluation criteria of filter importance and then prune less important filters with a fixed pruning rate or a fixed number to reduce convolutional neural networks' redundancy. It does not consider how many filters to reserve for each layer is the most reasonable choice. From this perspective, we propose a new filter pruning method by searching the proper number of filters (SNF). SNF is dedicated to searching for the most reasonable number of reserved filters for each layer and then pruning filters with specific criteria. It can tailor the most suitable network structure at different FLOPs. Filter pruning with our method leads to the state-of-the-art (SOTA) accuracy on CIFAR-10 and achieves competitive performance on ImageNet ILSVRC-2012.SNF based on the ResNet-56 network achieves an increase of 0.14% in Top-1 accuracy at 52.94% FLOPs reduction on CIFAR-10. Pruning ResNet-110 on CIFAR-10 also improves the Top-1 accuracy of 0.03% when reducing 68.68% FLOPs. For ImageNet, we set the pruning rates as 52.10% FLOPs, and the Top-1 accuracy only has a drop of 0.74%. The codes can be available at https://github.com/pk-l/SNF.