 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlumber: Diagnosing and Removing Performance Bottlenecks in Machine Learning Data Pipelines
Paper and Code
Nov 07, 2021
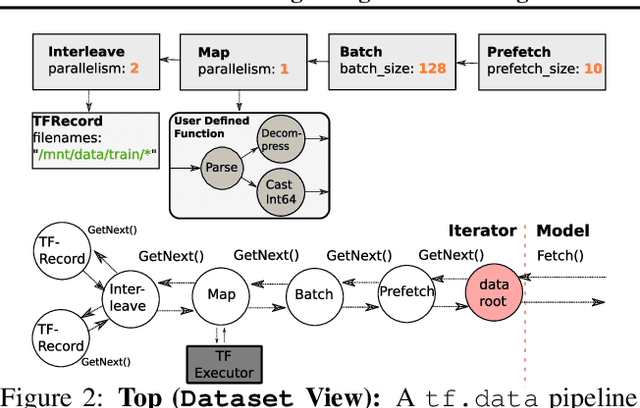
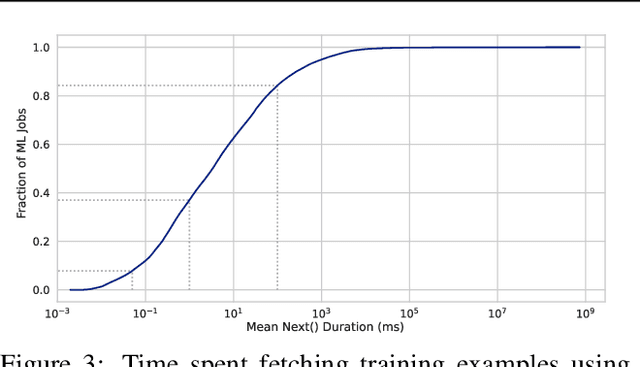
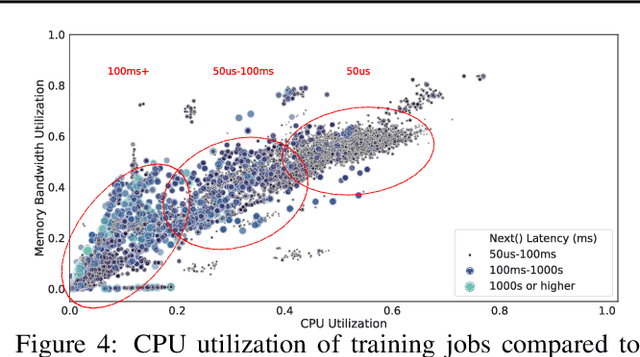
Input pipelines, which ingest and transform input data, are an essential part of training Machine Learning (ML) models. However, it is challenging to implement efficient input pipelines, as it requires reasoning about parallelism, asynchrony, and variability in fine-grained profiling information. Our analysis of over 2 million ML jobs in Google datacenters reveals that a significant fraction of model training jobs could benefit from faster input data pipelines. At the same time, our analysis reveals that most jobs do not saturate host hardware, pointing in the direction of software-based bottlenecks. Motivated by these findings, we propose Plumber, a tool for finding bottlenecks in ML input pipelines. Plumber uses an extensible and interprettable operational analysis analytical model to automatically tune parallelism, prefetching, and caching under host resource constraints. Across five representative ML pipelines, Plumber obtains speedups of up to 46x for misconfigured pipelines. By automating caching, Plumber obtains end-to-end speedups of over 40% compared to state-of-the-art tuners.