 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Training on Multi-Instance GPUs
Paper and Code
Sep 13, 2022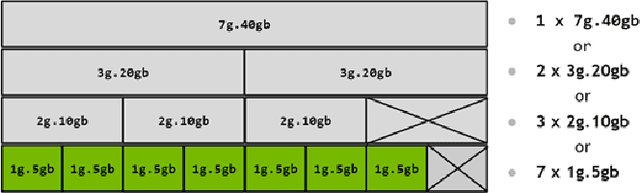
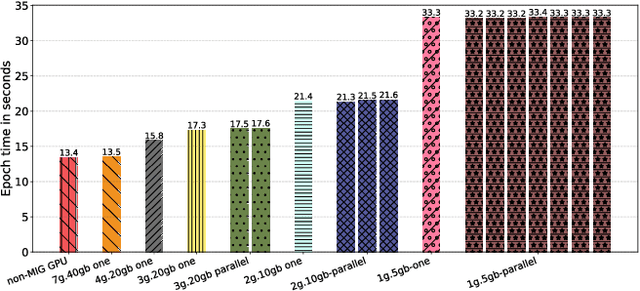
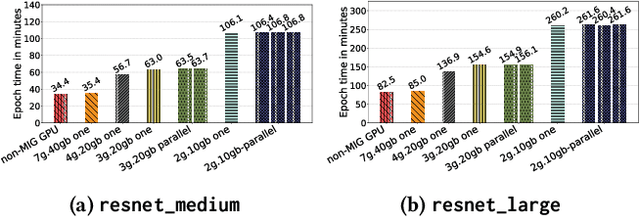
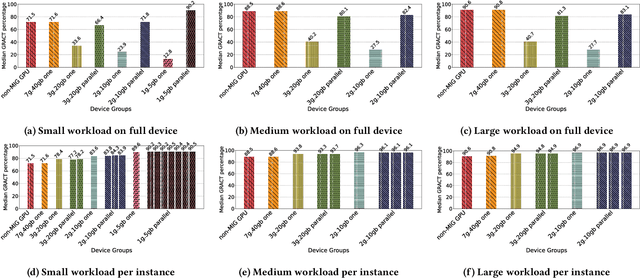
Deep learning training is an expensive process that extensively uses GPUs, but not all model training saturates the modern powerful GPUs. Multi-Instance GPU (MIG) is a new technology introduced by NVIDIA that can partition a GPU to better fit workloads that don't require all the memory and compute resources of a full GPU. In this paper, we examine the performance of a MIG-enabled A100 GPU under deep learning workloads of three sizes focusing on image recognition training with ResNet models. We investigate the behavior of these workloads when running in isolation on a variety of MIG instances allowed by the GPU in addition to running them in parallel on homogeneous instances co-located on the same GPU. Our results demonstrate that employing MIG can significantly improve the utilization of the GPU when the workload is too small to utilize the whole GPU in isolation. By training multiple small models in parallel, more work can be performed by the GPU per unit of time, despite the increase in time-per-epoch, leading to $\sim$3 times the throughput. In contrast, for medium and large-sized workloads, which already utilize the whole GPU well on their own, MIG only provides marginal performance improvements. Nevertheless, we observe that training models in parallel using separate MIG partitions does not exhibit interference underlining the value of having a functionality like MIG on modern GPUs.