 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStress Testing Factual Consistency Metrics for Long-Document Summarization
Nov 10, 2025Evaluating the factual consistency of abstractive text summarization remains a significant challenge, particularly for long documents, where conventional metrics struggle with input length limitations and long-range dependencies. In this work, we systematically evaluate the reliability of six widely used reference-free factuality metrics, originally proposed for short-form summarization, in the long-document setting. We probe metric robustness through seven factuality-preserving perturbations applied to summaries, namely paraphrasing, simplification, synonym replacement, logically equivalent negations, vocabulary reduction, compression, and source text insertion, and further analyze their sensitivity to retrieval context and claim information density. Across three long-form benchmark datasets spanning science fiction, legal, and scientific domains, our results reveal that existing short-form metrics produce inconsistent scores for semantically equivalent summaries and exhibit declining reliability for information-dense claims whose content is semantically similar to many parts of the source document. While expanding the retrieval context improves stability in some domains, no metric consistently maintains factual alignment under long-context conditions. Finally, our results highlight concrete directions for improving factuality evaluation, including multi-span reasoning, context-aware calibration, and training on meaning-preserving variations to enhance robustness in long-form summarization. We release all code, perturbed data, and scripts required to reproduce our results at https://github.com/zainmujahid/metricEval-longSum.
Unstructured Evidence Attribution for Long Context Query Focused Summarization
Feb 20, 2025Large language models (LLMs) are capable of generating coherent summaries from very long contexts given a user query. Extracting and properly citing evidence spans could help improve the transparency and reliability of these summaries. At the same time, LLMs suffer from positional biases in terms of which information they understand and attend to, which could affect evidence citation. Whereas previous work has focused on evidence citation with predefined levels of granularity (e.g. sentence, paragraph, document, etc.), we propose the task of long-context query focused summarization with unstructured evidence citation. We show how existing systems struggle to generate and properly cite unstructured evidence from their context, and that evidence tends to be "lost-in-the-middle". To help mitigate this, we create the Summaries with Unstructured Evidence Text dataset (SUnsET), a synthetic dataset generated using a novel domain-agnostic pipeline which can be used as supervision to adapt LLMs to this task. We demonstrate across 5 LLMs of different sizes and 4 datasets with varying document types and lengths that LLMs adapted with SUnsET data generate more relevant and factually consistent evidence than their base models, extract evidence from more diverse locations in their context, and can generate more relevant and consistent summaries.
Collecting Cost-Effective, High-Quality Truthfulness Assessments with LLM Summarized Evidence
Jan 30, 2025



With the degradation of guardrails against mis- and disinformation online, it is more critical than ever to be able to effectively combat it. In this paper, we explore the efficiency and effectiveness of using crowd-sourced truthfulness assessments based on condensed, large language model (LLM) generated summaries of online sources. We compare the use of generated summaries to the use of original web pages in an A/B testing setting, where we employ a large and diverse pool of crowd-workers to perform the truthfulness assessment. We evaluate the quality of assessments, the efficiency with which assessments are performed, and the behavior and engagement of participants. Our results demonstrate that the Summary modality, which relies on summarized evidence, offers no significant change in assessment accuracy over the Standard modality, while significantly increasing the speed with which assessments are performed. Workers using summarized evidence produce a significantly higher number of assessments in the same time frame, reducing the cost needed to acquire truthfulness assessments. Additionally, the Summary modality maximizes both the inter-annotator agreements as well as the reliance on and perceived usefulness of evidence, demonstrating the utility of summarized evidence without sacrificing the quality of assessments.
Real or Robotic? Assessing Whether LLMs Accurately Simulate Qualities of Human Responses in Dialogue
Sep 16, 2024Studying and building datasets for dialogue tasks is both expensive and time-consuming due to the need to recruit, train, and collect data from study participants. In response, much recent work has sought to use large language models (LLMs) to simulate both human-human and human-LLM interactions, as they have been shown to generate convincingly human-like text in many settings. However, to what extent do LLM-based simulations \textit{actually} reflect human dialogues? In this work, we answer this question by generating a large-scale dataset of 100,000 paired LLM-LLM and human-LLM dialogues from the WildChat dataset and quantifying how well the LLM simulations align with their human counterparts. Overall, we find relatively low alignment between simulations and human interactions, demonstrating a systematic divergence along the multiple textual properties, including style and content. Further, in comparisons of English, Chinese, and Russian dialogues, we find that models perform similarly. Our results suggest that LLMs generally perform better when the human themself writes in a way that is more similar to the LLM's own style.
Revealing Fine-Grained Values and Opinions in Large Language Models
Jun 27, 2024Uncovering latent values and opinions in large language models (LLMs) can help identify biases and mitigate potential harm. Recently, this has been approached by presenting LLMs with survey questions and quantifying their stances towards morally and politically charged statements. However, the stances generated by LLMs can vary greatly depending on how they are prompted, and there are many ways to argue for or against a given position. In this work, we propose to address this by analysing a large and robust dataset of 156k LLM responses to the 62 propositions of the Political Compass Test (PCT) generated by 6 LLMs using 420 prompt variations. We perform coarse-grained analysis of their generated stances and fine-grained analysis of the plain text justifications for those stances. For fine-grained analysis, we propose to identify tropes in the responses: semantically similar phrases that are recurrent and consistent across different prompts, revealing patterns in the text that a given LLM is prone to produce. We find that demographic features added to prompts significantly affect outcomes on the PCT, reflecting bias, as well as disparities between the results of tests when eliciting closed-form vs. open domain responses. Additionally, patterns in the plain text rationales via tropes show that similar justifications are repeatedly generated across models and prompts even with disparate stances.
BMRS: Bayesian Model Reduction for Structured Pruning
Jun 03, 2024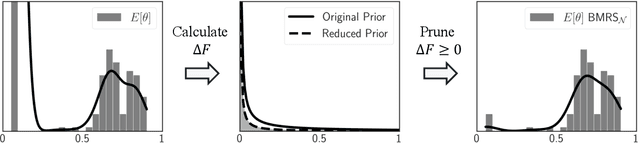



Modern neural networks are often massively overparameterized leading to high compute costs during training and at inference. One effective method to improve both the compute and energy efficiency of neural networks while maintaining good performance is structured pruning, where full network structures (e.g. neurons or convolutional filters) that have limited impact on the model output are removed. In this work, we propose Bayesian Model Reduction for Structured pruning (BMRS), a fully end-to-end Bayesian method of structured pruning. BMRS is based on two recent methods: Bayesian structured pruning with multiplicative noise, and Bayesian model reduction (BMR), a method which allows efficient comparison of Bayesian models under a change in prior. We present two realizations of BMRS derived from different priors which yield different structured pruning characteristics: 1) BMRS_N with the truncated log-normal prior, which offers reliable compression rates and accuracy without the need for tuning any thresholds and 2) BMRS_U with the truncated log-uniform prior that can achieve more aggressive compression based on the boundaries of truncation. Overall, we find that BMRS offers a theoretically grounded approach to structured pruning of neural networks yielding both high compression rates and accuracy. Experiments on multiple datasets and neural networks of varying complexity showed that the two BMRS methods offer a competitive performance-efficiency trade-off compared to other pruning methods.
Understanding Fine-grained Distortions in Reports of Scientific Findings
Feb 19, 2024



Distorted science communication harms individuals and society as it can lead to unhealthy behavior change and decrease trust in scientific institutions. Given the rapidly increasing volume of science communication in recent years, a fine-grained understanding of how findings from scientific publications are reported to the general public, and methods to detect distortions from the original work automatically, are crucial. Prior work focused on individual aspects of distortions or worked with unpaired data. In this work, we make three foundational contributions towards addressing this problem: (1) annotating 1,600 instances of scientific findings from academic papers paired with corresponding findings as reported in news articles and tweets wrt. four characteristics: causality, certainty, generality and sensationalism; (2) establishing baselines for automatically detecting these characteristics; and (3) analyzing the prevalence of changes in these characteristics in both human-annotated and large-scale unlabeled data. Our results show that scientific findings frequently undergo subtle distortions when reported. Tweets distort findings more often than science news reports. Detecting fine-grained distortions automatically poses a challenging task. In our experiments, fine-tuned task-specific models consistently outperform few-shot LLM prompting.
Efficiency is Not Enough: A Critical Perspective of Environmentally Sustainable AI
Sep 05, 2023



Artificial Intelligence (AI) is currently spearheaded by machine learning (ML) methods such as deep learning (DL) which have accelerated progress on many tasks thought to be out of reach of AI. These ML methods can often be compute hungry, energy intensive, and result in significant carbon emissions, a known driver of anthropogenic climate change. Additionally, the platforms on which ML systems run are associated with environmental impacts including and beyond carbon emissions. The solution lionized by both industry and the ML community to improve the environmental sustainability of ML is to increase the efficiency with which ML systems operate in terms of both compute and energy consumption. In this perspective, we argue that efficiency alone is not enough to make ML as a technology environmentally sustainable. We do so by presenting three high level discrepancies between the effect of efficiency on the environmental sustainability of ML when considering the many variables which it interacts with. In doing so, we comprehensively demonstrate, at multiple levels of granularity both technical and non-technical reasons, why efficiency is not enough to fully remedy the environmental impacts of ML. Based on this, we present and argue for systems thinking as a viable path towards improving the environmental sustainability of ML holistically.
Multi-View Knowledge Distillation from Crowd Annotations for Out-of-Domain Generalization
Dec 19, 2022



Selecting an effective training signal for tasks in natural language processing is difficult: collecting expert annotations is expensive, and crowd-sourced annotations may not be reliable. At the same time, recent work in machine learning has demonstrated that learning from soft-labels acquired from crowd annotations can be effective, especially when there is distribution shift in the test set. However, the best method for acquiring these soft labels is inconsistent across tasks. This paper proposes new methods for acquiring soft-labels from crowd-annotations by aggregating the distributions produced by existing methods. In particular, we propose to find a distribution over classes by learning from multiple-views of crowd annotations via temperature scaling and finding the Jensen-Shannon centroid of their distributions. We demonstrate that using these aggregation methods leads to best or near-best performance across four NLP tasks on out-of-domain test sets, mitigating fluctuations in performance when using the constituent methods on their own. Additionally, these methods result in best or near-best uncertainty estimation across tasks. We argue that aggregating different views of crowd-annotations as soft-labels is an effective way to ensure performance which is as good or better than the best individual view, which is useful given the inconsistency in performance of the individual methods.
Revisiting Softmax for Uncertainty Approximation in Text Classification
Oct 25, 2022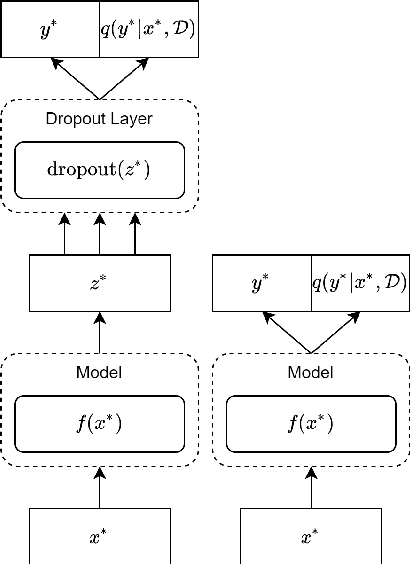


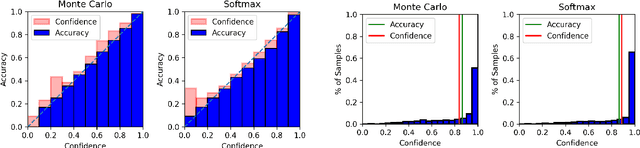
Uncertainty approximation in text classification is an important area with applications in domain adaptation and interpretability. The most widely used uncertainty approximation method is Monte Carlo Dropout, which is computationally expensive as it requires multiple forward passes through the model. A cheaper alternative is to simply use a softmax to estimate model uncertainty. However, prior work has indicated that the softmax can generate overconfident uncertainty estimates and can thus be tricked into producing incorrect predictions. In this paper, we perform a thorough empirical analysis of both methods on five datasets with two base neural architectures in order to reveal insight into the trade-offs between the two. We compare the methods' uncertainty approximations and downstream text classification performance, while weighing their performance against their computational complexity as a cost-benefit analysis, by measuring runtime (cost) and the downstream performance (benefit). We find that, while Monte Carlo produces the best uncertainty approximations, using a simple softmax leads to competitive uncertainty estimation for text classification at a much lower computational cost, suggesting that softmax can in fact be a sufficient uncertainty estimate when computational resources are a concern.