 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Softmax for Uncertainty Approximation in Text Classification
Paper and Code
Oct 25, 2022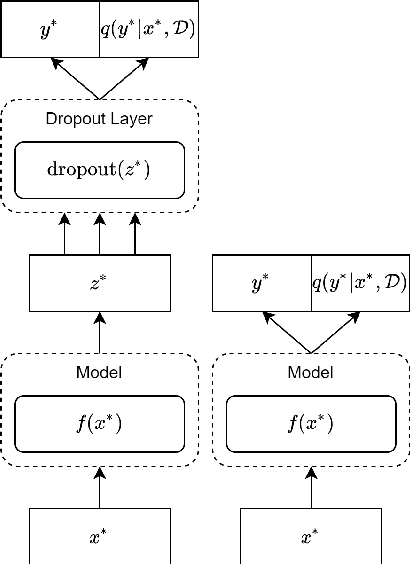


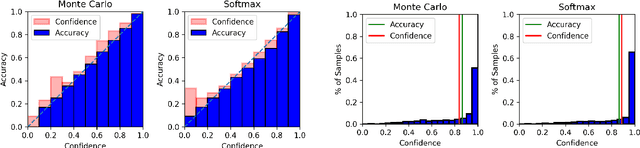
Uncertainty approximation in text classification is an important area with applications in domain adaptation and interpretability. The most widely used uncertainty approximation method is Monte Carlo Dropout, which is computationally expensive as it requires multiple forward passes through the model. A cheaper alternative is to simply use a softmax to estimate model uncertainty. However, prior work has indicated that the softmax can generate overconfident uncertainty estimates and can thus be tricked into producing incorrect predictions. In this paper, we perform a thorough empirical analysis of both methods on five datasets with two base neural architectures in order to reveal insight into the trade-offs between the two. We compare the methods' uncertainty approximations and downstream text classification performance, while weighing their performance against their computational complexity as a cost-benefit analysis, by measuring runtime (cost) and the downstream performance (benefit). We find that, while Monte Carlo produces the best uncertainty approximations, using a simple softmax leads to competitive uncertainty estimation for text classification at a much lower computational cost, suggesting that softmax can in fact be a sufficient uncertainty estimate when computational resources are a concern.