 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Softmax for Uncertainty Approximation in Text Classification
Oct 25, 2022


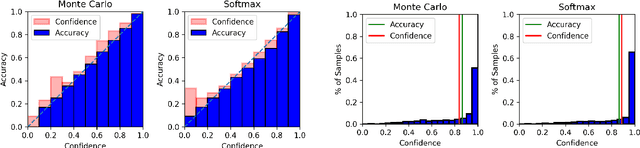
Uncertainty approximation in text classification is an important area with applications in domain adaptation and interpretability. The most widely used uncertainty approximation method is Monte Carlo Dropout, which is computationally expensive as it requires multiple forward passes through the model. A cheaper alternative is to simply use a softmax to estimate model uncertainty. However, prior work has indicated that the softmax can generate overconfident uncertainty estimates and can thus be tricked into producing incorrect predictions. In this paper, we perform a thorough empirical analysis of both methods on five datasets with two base neural architectures in order to reveal insight into the trade-offs between the two. We compare the methods' uncertainty approximations and downstream text classification performance, while weighing their performance against their computational complexity as a cost-benefit analysis, by measuring runtime (cost) and the downstream performance (benefit). We find that, while Monte Carlo produces the best uncertainty approximations, using a simple softmax leads to competitive uncertainty estimation for text classification at a much lower computational cost, suggesting that softmax can in fact be a sufficient uncertainty estimate when computational resources are a concern.
Longitudinal Citation Prediction using Temporal Graph Neural Networks
Dec 10, 2020
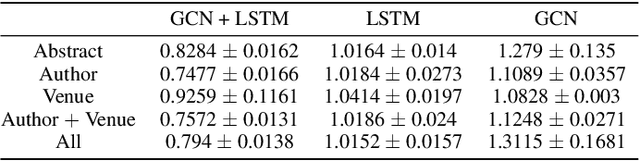
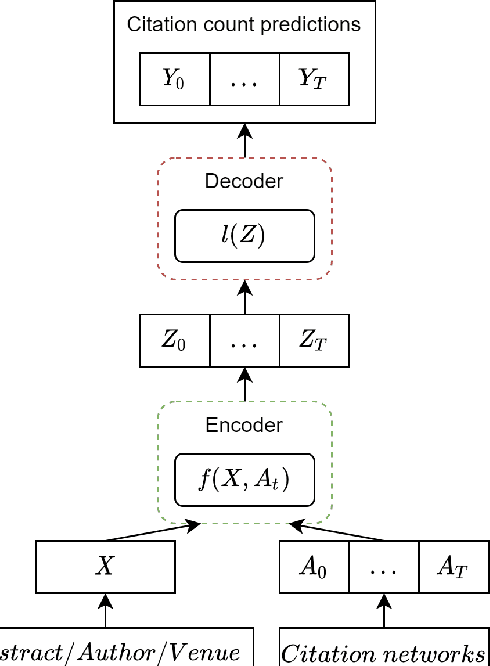
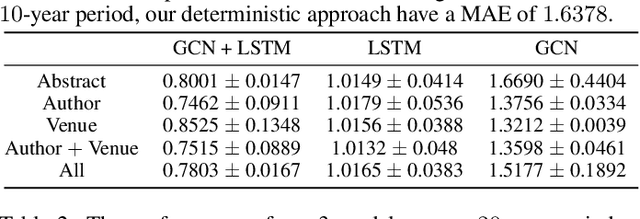
Citation count prediction is the task of predicting the number of citations a paper has gained after a period of time. Prior work viewed this as a static prediction task. As papers and their citations evolve over time, considering the dynamics of the number of citations a paper will receive would seem logical. Here, we introduce the task of sequence citation prediction, where the goal is to accurately predict the trajectory of the number of citations a scholarly work receives over time. We propose to view papers as a structured network of citations, allowing us to use topological information as a learning signal. Additionally, we learn how this dynamic citation network changes over time and the impact of paper meta-data such as authors, venues and abstracts. To approach the introduced task, we derive a dynamic citation network from Semantic Scholar which spans over 42 years. We present a model which exploits topological and temporal information using graph convolution networks paired with sequence prediction, and compare it against multiple baselines, testing the importance of topological and temporal information and analyzing model performance. Our experiments show that leveraging both the temporal and topological information greatly increases the performance of predicting citation counts over time.
Learning from graphs with structural variation
Jun 29, 2018
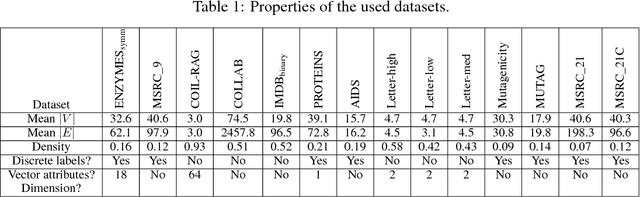
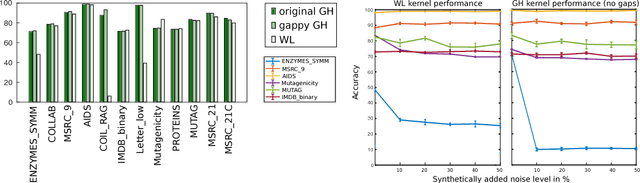
We study the effect of structural variation in graph data on the predictive performance of graph kernels. To this end, we introduce a novel, noise-robust adaptation of the GraphHopper kernel and validate it on benchmark data, obtaining modestly improved predictive performance on a range of datasets. Next, we investigate the performance of the state-of-the-art Weisfeiler-Lehman graph kernel under increasing synthetic structural errors and find that the effect of introducing errors depends strongly on the dataset.