 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplicit Evidence Grounding via Structured Inline Citation Generation
Jun 05, 2026As AI systems become more widely adopted, the demand for factual and faithful generation grows. Properly attributing information through citations becomes, therefore, crucial. This work introduces FullCite, a framework that, in contrast to most previous works, generates structured inline citations linking each claim to both its source document and supporting evidence. FullCite proposes three strategies to inline citation generation: prompt-based generation, constrained decoding over a citation grammar, and posthoc span alignment. Using three question answering benchmarks, namely, ASQA, BioASQ, and ExpertQA, we assess citation quality and faithfulness along three dimensions: document-level correctness, evidence span identification, and claim-citation faithfulness. Our evaluation shows that while LLMs are generally effective at identifying relevant documents, they struggle to identify the precise supporting spans within them. This gap suggests that achieving faithful attributed QA will require research to place greater emphasis on precise evidence span identification.
Towards Expectation Detection in Language: A Case Study on Treatment Expectations in Reddit
Feb 17, 2026Patients' expectations towards their treatment have a substantial effect on the treatments' success. While primarily studied in clinical settings, online patient platforms like medical subreddits may hold complementary insights: treatment expectations that patients feel unnecessary or uncomfortable to share elsewhere. Despite this, no studies examine what type of expectations users discuss online and how they express them. Presumably this is because expectations have not been studied in natural language processing (NLP) before. Therefore, we introduce the task of Expectation Detection, arguing that expectations are relevant for many applications, including opinion mining and product design. Subsequently, we present a case study for the medical domain, where expectations are particularly crucial to extract. We contribute RedHOTExpect, a corpus of Reddit posts (4.5K posts) to study expectations in this context. We use a large language model (LLM) to silver-label the data and validate its quality manually (label accuracy ~78%). Based on this, we analyze which linguistic patterns characterize expectations and explore what patients expect and why. We find that optimism and proactive framing are more pronounced in posts about physical or treatment-related illnesses compared to mental-health contexts, and that in our dataset, patients mostly discuss benefits rather than negative outcomes. The RedHOTExpect corpus can be obtained from https://www.ims.uni-stuttgart.de/data/RedHOTExpect
Self-Adaptive Paraphrasing and Preference Learning for Improved Claim Verifiability
Dec 16, 2024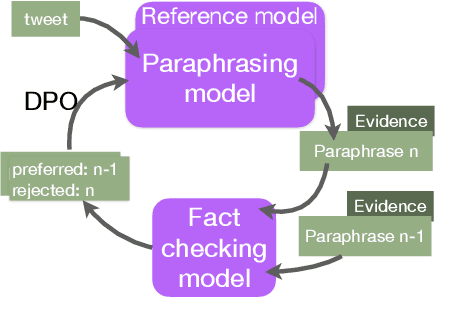
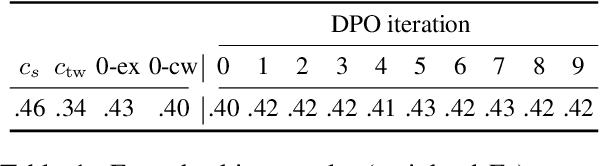
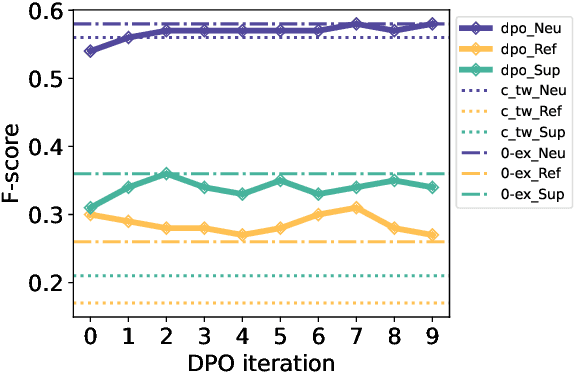
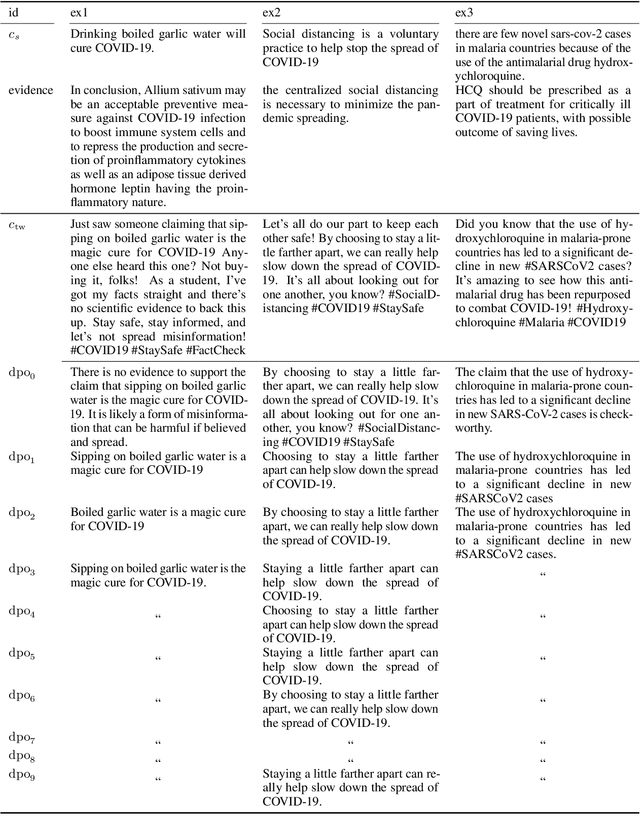
In fact-checking, structure and phrasing of claims critically influence a model's ability to predict verdicts accurately. Social media content in particular rarely serves as optimal input for verification systems, which necessitates pre-processing to extract the claim from noisy context before fact checking. Prior work suggests extracting a claim representation that humans find to be checkworthy and verifiable. This has two limitations: (1) the format may not be optimal for a fact-checking model, and (2), it requires annotated data to learn the extraction task from. We address both issues and propose a method to extract claims that is not reliant on labeled training data. Instead, our self-adaptive approach only requires a black-box fact checking model and a generative language model (LM). Given a tweet, we iteratively optimize the LM to generate a claim paraphrase that increases the performance of a fact checking model. By learning from preference pairs, we align the LM to the fact checker using direct preference optimization. We show that this novel setup extracts a claim paraphrase that is more verifiable than their original social media formulations, and is on par with competitive baselines. For refuted claims, our method consistently outperforms all baselines.
Which Demographics do LLMs Default to During Annotation?
Oct 11, 2024

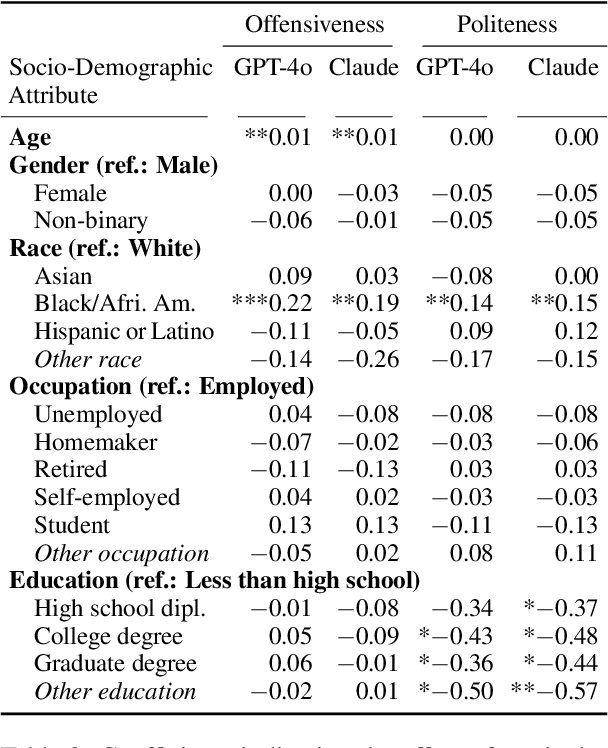
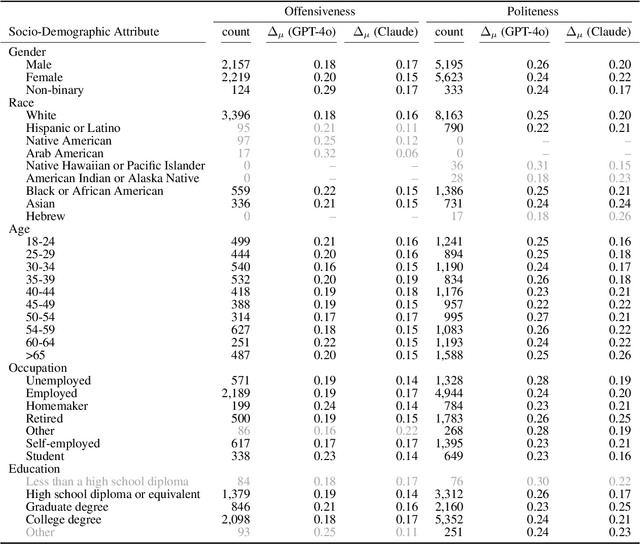
Demographics and cultural background of annotators influence the labels they assign in text annotation -- for instance, an elderly woman might find it offensive to read a message addressed to a "bro", but a male teenager might find it appropriate. It is therefore important to acknowledge label variations to not under-represent members of a society. Two research directions developed out of this observation in the context of using large language models (LLM) for data annotations, namely (1) studying biases and inherent knowledge of LLMs and (2) injecting diversity in the output by manipulating the prompt with demographic information. We combine these two strands of research and ask the question to which demographics an LLM resorts to when no demographics is given. To answer this question, we evaluate which attributes of human annotators LLMs inherently mimic. Furthermore, we compare non-demographic conditioned prompts and placebo-conditioned prompts (e.g., "you are an annotator who lives in house number 5") to demographics-conditioned prompts ("You are a 45 year old man and an expert on politeness annotation. How do you rate {instance}"). We study these questions for politeness and offensiveness annotations on the POPQUORN data set, a corpus created in a controlled manner to investigate human label variations based on demographics which has not been used for LLM-based analyses so far. We observe notable influences related to gender, race, and age in demographic prompting, which contrasts with previous studies that found no such effects.
How Entangled is Factuality and Deception in German?
Sep 30, 2024



The statement "The earth is flat" is factually inaccurate, but if someone truly believes and argues in its favor, it is not deceptive. Research on deception detection and fact checking often conflates factual accuracy with the truthfulness of statements. This assumption makes it difficult to (a) study subtle distinctions and interactions between the two and (b) gauge their effects on downstream tasks. The belief-based deception framework disentangles these properties by defining texts as deceptive when there is a mismatch between what people say and what they truly believe. In this study, we assess if presumed patterns of deception generalize to German language texts. We test the effectiveness of computational models in detecting deception using an established corpus of belief-based argumentation. Finally, we gauge the impact of deception on the downstream task of fact checking and explore if this property confounds verification models. Surprisingly, our analysis finds no correlation with established cues of deception. Previous work claimed that computational models can outperform humans in deception detection accuracy, however, our experiments show that both traditional and state-of-the-art models struggle with the task, performing no better than random guessing. For fact checking, we find that Natural Language Inference-based verification performs worse on non-factual and deceptive content, while prompting Large Language Models for the same task is less sensitive to these properties.
Can Factual Statements be Deceptive? The DeFaBel Corpus of Belief-based Deception
Mar 15, 2024



If a person firmly believes in a non-factual statement, such as "The Earth is flat", and argues in its favor, there is no inherent intention to deceive. As the argumentation stems from genuine belief, it may be unlikely to exhibit the linguistic properties associated with deception or lying. This interplay of factuality, personal belief, and intent to deceive remains an understudied area. Disentangling the influence of these variables in argumentation is crucial to gain a better understanding of the linguistic properties attributed to each of them. To study the relation between deception and factuality, based on belief, we present the DeFaBel corpus, a crowd-sourced resource of belief-based deception. To create this corpus, we devise a study in which participants are instructed to write arguments supporting statements like "eating watermelon seeds can cause indigestion", regardless of its factual accuracy or their personal beliefs about the statement. In addition to the generation task, we ask them to disclose their belief about the statement. The collected instances are labelled as deceptive if the arguments are in contradiction to the participants' personal beliefs. Each instance in the corpus is thus annotated (or implicitly labelled) with personal beliefs of the author, factuality of the statement, and the intended deceptiveness. The DeFaBel corpus contains 1031 texts in German, out of which 643 are deceptive and 388 are non-deceptive. It is the first publicly available corpus for studying deception in German. In our analysis, we find that people are more confident in the persuasiveness of their arguments when the statement is aligned with their belief, but surprisingly less confident when they are generating arguments in favor of facts. The DeFaBel corpus can be obtained from https://www.ims.uni-stuttgart.de/data/defabel
Understanding Fine-grained Distortions in Reports of Scientific Findings
Feb 19, 2024



Distorted science communication harms individuals and society as it can lead to unhealthy behavior change and decrease trust in scientific institutions. Given the rapidly increasing volume of science communication in recent years, a fine-grained understanding of how findings from scientific publications are reported to the general public, and methods to detect distortions from the original work automatically, are crucial. Prior work focused on individual aspects of distortions or worked with unpaired data. In this work, we make three foundational contributions towards addressing this problem: (1) annotating 1,600 instances of scientific findings from academic papers paired with corresponding findings as reported in news articles and tweets wrt. four characteristics: causality, certainty, generality and sensationalism; (2) establishing baselines for automatically detecting these characteristics; and (3) analyzing the prevalence of changes in these characteristics in both human-annotated and large-scale unlabeled data. Our results show that scientific findings frequently undergo subtle distortions when reported. Tweets distort findings more often than science news reports. Detecting fine-grained distortions automatically poses a challenging task. In our experiments, fine-tuned task-specific models consistently outperform few-shot LLM prompting.
What Makes Medical Claims (Un)Verifiable? Analyzing Entity and Relation Properties for Fact Verification
Feb 02, 2024Biomedical claim verification fails if no evidence can be discovered. In these cases, the fact-checking verdict remains unknown and the claim is unverifiable. To improve upon this, we have to understand if there are any claim properties that impact its verifiability. In this work we assume that entities and relations define the core variables in a biomedical claim's anatomy and analyze if their properties help us to differentiate verifiable from unverifiable claims. In a study with trained annotation experts we prompt them to find evidence for biomedical claims, and observe how they refine search queries for their evidence search. This leads to the first corpus for scientific fact verification annotated with subject-relation-object triplets, evidence documents, and fact-checking verdicts (the BEAR-Fact corpus). We find (1) that discovering evidence for negated claims (e.g., X-does-not-cause-Y) is particularly challenging. Further, we see that annotators process queries mostly by adding constraints to the search and by normalizing entities to canonical names. (2) We compare our in-house annotations with a small crowdsourcing setting where we employ medical experts and laypeople. We find that domain expertise does not have a substantial effect on the reliability of annotations. Finally, (3), we demonstrate that it is possible to reliably estimate the success of evidence retrieval purely from the claim text~(.82\F), whereas identifying unverifiable claims proves more challenging (.27\F). The dataset is available at http://www.ims.uni-stuttgart.de/data/bioclaim.
An Entity-based Claim Extraction Pipeline for Real-world Biomedical Fact-checking
Apr 11, 2023



Existing fact-checking models for biomedical claims are typically trained on synthetic or well-worded data and hardly transfer to social media content. This mismatch can be mitigated by adapting the social media input to mimic the focused nature of common training claims. To do so, Wuehrl & Klinger (2022) propose to extract concise claims based on medical entities in the text. However, their study has two limitations: First, it relies on gold-annotated entities. Therefore, its feasibility for a real-world application cannot be assessed since this requires detecting relevant entities automatically. Second, they represent claim entities with the original tokens. This constitutes a terminology mismatch which potentially limits the fact-checking performance. To understand both challenges, we propose a claim extraction pipeline for medical tweets that incorporates named entity recognition and terminology normalization via entity linking. We show that automatic NER does lead to a performance drop in comparison to using gold annotations but the fact-checking performance still improves considerably over inputting the unchanged tweets. Normalizing entities to their canonical forms does, however, not improve the performance.
Entity-based Claim Representation Improves Fact-Checking of Medical Content in Tweets
Sep 16, 2022
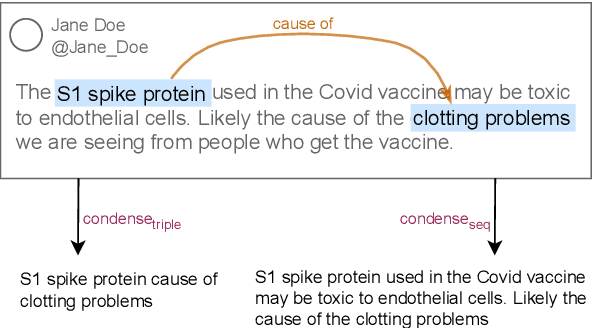
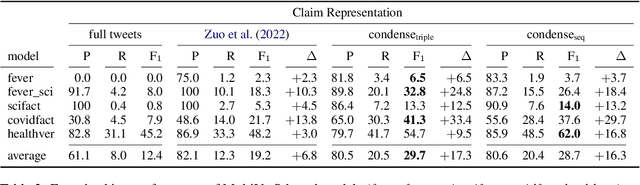
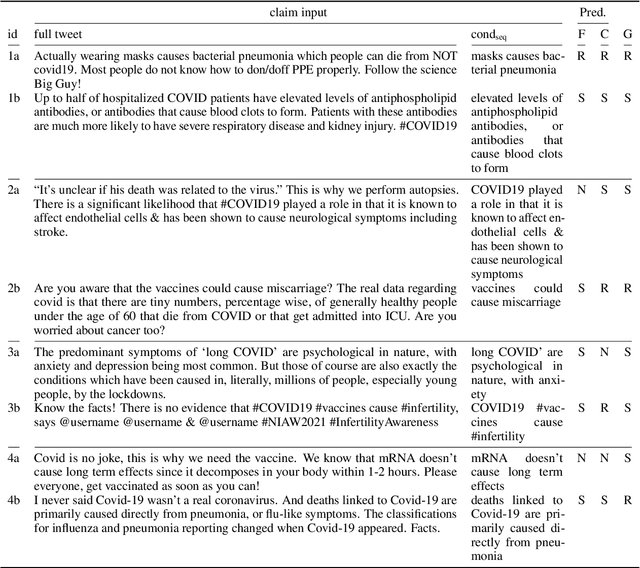
False medical information on social media poses harm to people's health. While the need for biomedical fact-checking has been recognized in recent years, user-generated medical content has received comparably little attention. At the same time, models for other text genres might not be reusable, because the claims they have been trained with are substantially different. For instance, claims in the SciFact dataset are short and focused: "Side effects associated with antidepressants increases risk of stroke". In contrast, social media holds naturally-occurring claims, often embedded in additional context: "`If you take antidepressants like SSRIs, you could be at risk of a condition called serotonin syndrome' Serotonin syndrome nearly killed me in 2010. Had symptoms of stroke and seizure." This showcases the mismatch between real-world medical claims and the input that existing fact-checking systems expect. To make user-generated content checkable by existing models, we propose to reformulate the social-media input in such a way that the resulting claim mimics the claim characteristics in established datasets. To accomplish this, our method condenses the claim with the help of relational entity information and either compiles the claim out of an entity-relation-entity triple or extracts the shortest phrase that contains these elements. We show that the reformulated input improves the performance of various fact-checking models as opposed to checking the tweet text in its entirety.