 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoVERT: A Corpus of Fact-checked Biomedical COVID-19 Tweets
Paper and Code

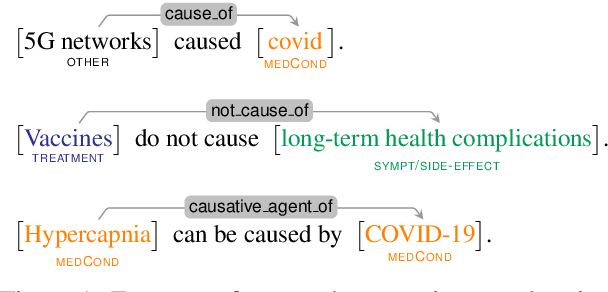

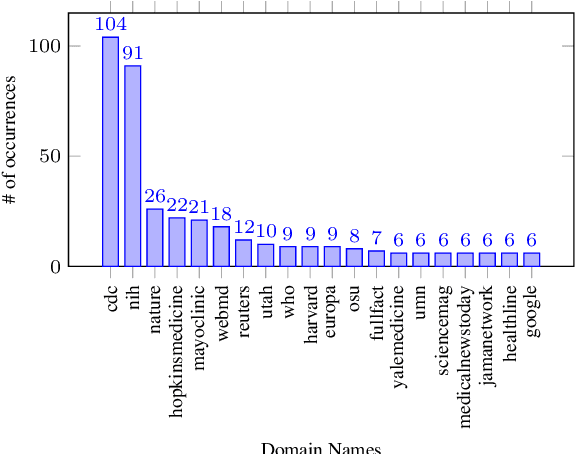
Over the course of the COVID-19 pandemic, large volumes of biomedical information concerning this new disease have been published on social media. Some of this information can pose a real danger to people's health, particularly when false information is shared, for instance recommendations on how to treat diseases without professional medical advice. Therefore, automatic fact-checking resources and systems developed specifically for the medical domain are crucial. While existing fact-checking resources cover COVID-19-related information in news or quantify the amount of misinformation in tweets, there is no dataset providing fact-checked COVID-19-related Twitter posts with detailed annotations for biomedical entities, relations and relevant evidence. We contribute CoVERT, a fact-checked corpus of tweets with a focus on the domain of biomedicine and COVID-19-related (mis)information. The corpus consists of 300 tweets, each annotated with medical named entities and relations. We employ a novel crowdsourcing methodology to annotate all tweets with fact-checking labels and supporting evidence, which crowdworkers search for online. This methodology results in moderate inter-annotator agreement. Furthermore, we use the retrieved evidence extracts as part of a fact-checking pipeline, finding that the real-world evidence is more useful than the knowledge indirectly available in pretrained language models.