 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCategorical Emotions or Appraisals - Which Emotion Model Explains Argument Convincingness Better?
Nov 18, 2025The convincingness of an argument does not only depend on its structure (logos), the person who makes the argument (ethos), but also on the emotion that it causes in the recipient (pathos). While the overall intensity and categorical values of emotions in arguments have received considerable attention in the research community, we argue that the emotion an argument evokes in a recipient is subjective. It depends on the recipient's goals, standards, prior knowledge, and stance. Appraisal theories lend themselves as a link between the subjective cognitive assessment of events and emotions. They have been used in event-centric emotion analysis, but their suitability for assessing argument convincingness remains unexplored. In this paper, we evaluate whether appraisal theories are suitable for emotion analysis in arguments by considering subjective cognitive evaluations of the importance and impact of an argument on its receiver. Based on the annotations in the recently published ContArgA corpus, we perform zero-shot prompting experiments to evaluate the importance of gold-annotated and predicted emotions and appraisals for the assessment of the subjective convincingness labels. We find that, while categorical emotion information does improve convincingness prediction, the improvement is more pronounced with appraisals. This work presents the first systematic comparison between emotion models for convincingness prediction, demonstrating the advantage of appraisals, providing insights for theoretical and practical applications in computational argumentation.
Are Humans as Brittle as Large Language Models?
Sep 09, 2025The output of large language models (LLM) is unstable, due to both non-determinism of the decoding process as well as to prompt brittleness. While the intrinsic non-determinism of LLM generation may mimic existing uncertainty in human annotations through distributional shifts in outputs, it is largely assumed, yet unexplored, that the prompt brittleness effect is unique to LLMs. This raises the question: do human annotators show similar sensitivity to instruction changes? If so, should prompt brittleness in LLMs be considered problematic? One may alternatively hypothesize that prompt brittleness correctly reflects human annotation variances. To fill this research gap, we systematically compare the effects of prompt modifications on LLMs and identical instruction modifications for human annotators, focusing on the question of whether humans are similarly sensitive to prompt perturbations. To study this, we prompt both humans and LLMs for a set of text classification tasks conditioned on prompt variations. Our findings indicate that both humans and LLMs exhibit increased brittleness in response to specific types of prompt modifications, particularly those involving the substitution of alternative label sets or label formats. However, the distribution of human judgments is less affected by typographical errors and reversed label order than that of LLMs.
Shaping Event Backstories to Estimate Potential Emotion Contexts
Aug 13, 2025Emotion analysis is an inherently ambiguous task. Previous work studied annotator properties to explain disagreement, but this overlooks the possibility that ambiguity may stem from missing information about the context of events. In this paper, we propose a novel approach that adds reasonable contexts to event descriptions, which may better explain a particular situation. Our goal is to understand whether these enriched contexts enable human annotators to annotate emotions more reliably. We disambiguate a target event description by automatically generating multiple event chains conditioned on differing emotions. By combining techniques from short story generation in various settings, we achieve coherent narratives that result in a specialized dataset for the first comprehensive and systematic examination of contextualized emotion analysis. Through automatic and human evaluation, we find that contextual narratives enhance the interpretation of specific emotions and support annotators in producing more consistent annotations.
Donate or Create? Comparing Data Collection Strategies for Emotion-labeled Multimodal Social Media Posts
May 30, 2025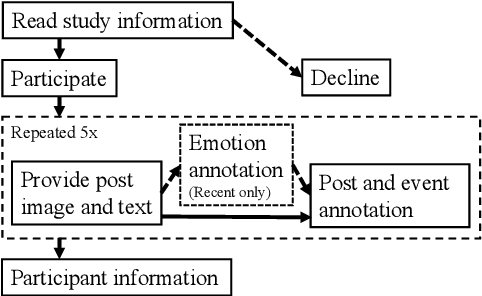
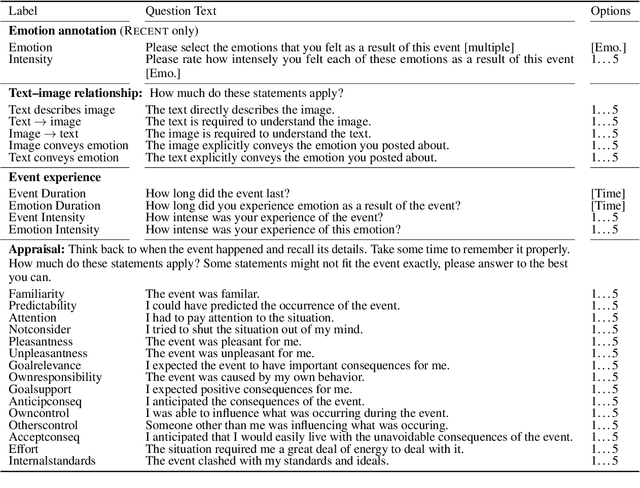
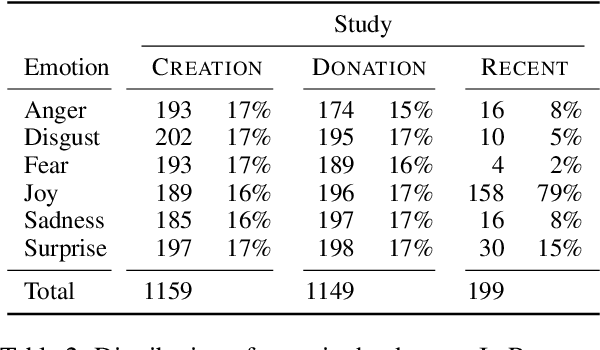
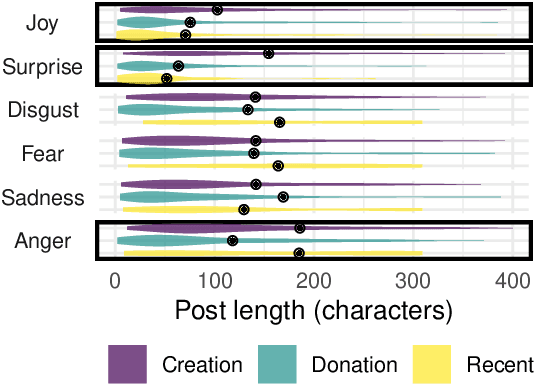
Accurate modeling of subjective phenomena such as emotion expression requires data annotated with authors' intentions. Commonly such data is collected by asking study participants to donate and label genuine content produced in the real world, or create content fitting particular labels during the study. Asking participants to create content is often simpler to implement and presents fewer risks to participant privacy than data donation. However, it is unclear if and how study-created content may differ from genuine content, and how differences may impact models. We collect study-created and genuine multimodal social media posts labeled for emotion and compare them on several dimensions, including model performance. We find that compared to genuine posts, study-created posts are longer, rely more on their text and less on their images for emotion expression, and focus more on emotion-prototypical events. The samples of participants willing to donate versus create posts are demographically different. Study-created data is valuable to train models that generalize well to genuine data, but realistic effectiveness estimates require genuine data.
What if Deception Cannot be Detected? A Cross-Linguistic Study on the Limits of Deception Detection from Text
May 19, 2025Can deception be detected solely from written text? Cues of deceptive communication are inherently subtle, even more so in text-only communication. Yet, prior studies have reported considerable success in automatic deception detection. We hypothesize that such findings are largely driven by artifacts introduced during data collection and do not generalize beyond specific datasets. We revisit this assumption by introducing a belief-based deception framework, which defines deception as a misalignment between an author's claims and true beliefs, irrespective of factual accuracy, allowing deception cues to be studied in isolation. Based on this framework, we construct three corpora, collectively referred to as DeFaBel, including a German-language corpus of deceptive and non-deceptive arguments and a multilingual version in German and English, each collected under varying conditions to account for belief change and enable cross-linguistic analysis. Using these corpora, we evaluate commonly reported linguistic cues of deception. Across all three DeFaBel variants, these cues show negligible, statistically insignificant correlations with deception labels, contrary to prior work that treats such cues as reliable indicators. We further benchmark against other English deception datasets following similar data collection protocols. While some show statistically significant correlations, effect sizes remain low and, critically, the set of predictive cues is inconsistent across datasets. We also evaluate deception detection using feature-based models, pretrained language models, and instruction-tuned large language models. While some models perform well on established deception datasets, they consistently perform near chance on DeFaBel. Our findings challenge the assumption that deception can be reliably inferred from linguistic cues and call for rethinking how deception is studied and modeled in NLP.
LLM-based Affective Text Generation Quality Based on Different Quantization Values
Jan 31, 2025Large language models exhibit a remarkable capacity in language generation and comprehension. These advances enable AI systems to produce more human-like and emotionally engaging text. However, these models rely on a large number of parameters, requiring significant computational resources for training and inference. In some scenarios, accessing these resources can be challenging (e.g., budget or hardware limitations). Techniques like reducing precision bits can make models more memory-efficient, reducing the computational resources needed, at the cost of reduced accuracy. This paper addresses the trade-off between different quantization values, GPU RAM utilization, and text quality in affective text generation (e.g., "I really enjoy running in the snow-covered forest"). To evaluate, we use an emotion classifier and ten seed prompts to generate affective text. We test three setups of precision bits (8, 16, and 32) across five open-weight language models from two different families. Our findings demonstrate that bit reductions lead to memory savings, achieving a reduction of 76%. However, this optimization comes with a trade-off, leading to a decrease of up to 10 pp in F1 score for larger models and an increase of 10 pp for smaller models, along with roughly double the inference time. In terms of text quality, larger models at lower quantization levels generally outperform smaller, higher-precision models -- while requiring similar memory.
Fearful Falcons and Angry Llamas: Emotion Category Annotations of Arguments by Humans and LLMs
Dec 20, 2024
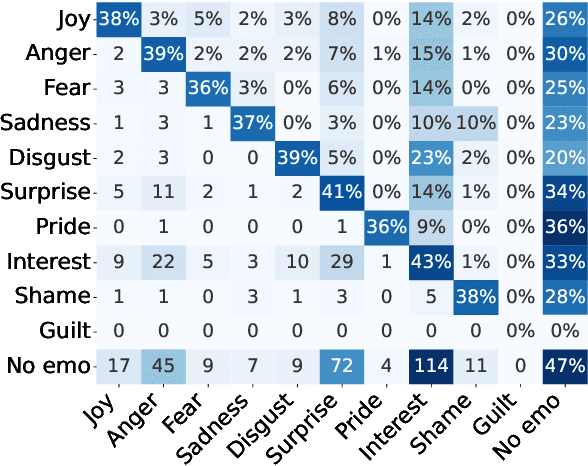

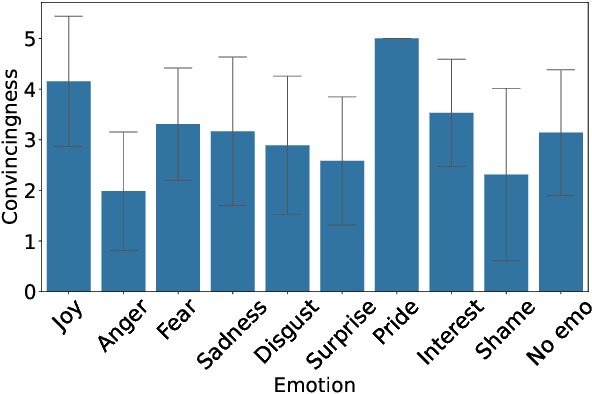
Arguments evoke emotions, influencing the effect of the argument itself. Not only the emotional intensity but also the category influence the argument's effects, for instance, the willingness to adapt stances. While binary emotionality has been studied in arguments, there is no work on discrete emotion categories (e.g., "Anger") in such data. To fill this gap, we crowdsource subjective annotations of emotion categories in a German argument corpus and evaluate automatic LLM-based labeling methods. Specifically, we compare three prompting strategies (zero-shot, one-shot, chain-of-thought) on three large instruction-tuned language models (Falcon-7b-instruct, Llama-3.1-8B-instruct, GPT-4o-mini). We further vary the definition of the output space to be binary (is there emotionality in the argument?), closed-domain (which emotion from a given label set is in the argument?), or open-domain (which emotion is in the argument?). We find that emotion categories enhance the prediction of emotionality in arguments, emphasizing the need for discrete emotion annotations in arguments. Across all prompt settings and models, automatic predictions show a high recall but low precision for predicting anger and fear, indicating a strong bias toward negative emotions.
iPrOp: Interactive Prompt Optimization for Large Language Models with a Human in the Loop
Dec 17, 2024



Prompt engineering has made significant contributions to the era of large language models, yet its effectiveness depends on the skills of a prompt author. Automatic prompt optimization can support the prompt development process, but requires annotated data. This paper introduces $\textit{iPrOp}$, a novel Interactive Prompt Optimization system, to bridge manual prompt engineering and automatic prompt optimization. With human intervention in the optimization loop, $\textit{iPrOp}$ offers users the flexibility to assess evolving prompts. We present users with prompt variations, selected instances, large language model predictions accompanied by corresponding explanations, and performance metrics derived from a subset of the training data. This approach empowers users to choose and further refine the provided prompts based on their individual preferences and needs. This system not only assists non-technical domain experts in generating optimal prompts tailored to their specific tasks or domains, but also enables to study the intrinsic parameters that influence the performance of prompt optimization. Our evaluation shows that our system has the capability to generate improved prompts, leading to enhanced task performance.
MOPO: Multi-Objective Prompt Optimization for Affective Text Generation
Dec 17, 2024How emotions are expressed depends on the context and domain. On X (formerly Twitter), for instance, an author might simply use the hashtag #anger, while in a news headline, emotions are typically written in a more polite, indirect manner. To enable conditional text generation models to create emotionally connotated texts that fit a domain, users need to have access to a parameter that allows them to choose the appropriate way to express an emotion. To achieve this, we introduce MOPO, a Multi-Objective Prompt Optimization methodology. MOPO optimizes prompts according to multiple objectives (which correspond here to the output probabilities assigned by emotion classifiers trained for different domains). In contrast to single objective optimization, MOPO outputs a set of prompts, each with a different weighting of the multiple objectives. Users can then choose the most appropriate prompt for their context. We evaluate MOPO using three objectives, determined by various domain-specific emotion classifiers. MOPO improves performance by up to 15 pp across all objectives with a minimal loss (1-2 pp) for any single objective compared to single-objective optimization. These minor performance losses are offset by a broader generalization across multiple objectives - which is not possible with single-objective optimization. Additionally, MOPO reduces computational requirements by simultaneously optimizing for multiple objectives, eliminating separate optimization procedures for each objective.
Self-Adaptive Paraphrasing and Preference Learning for Improved Claim Verifiability
Dec 16, 2024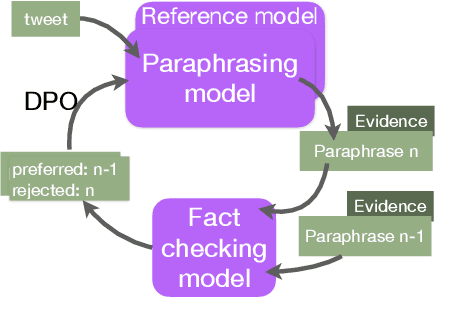
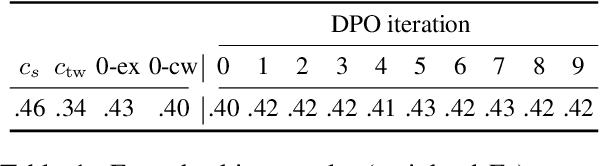
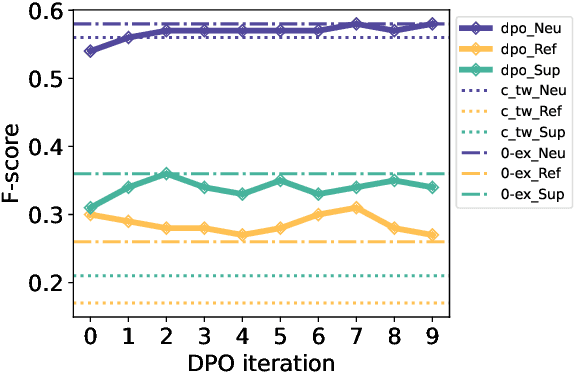
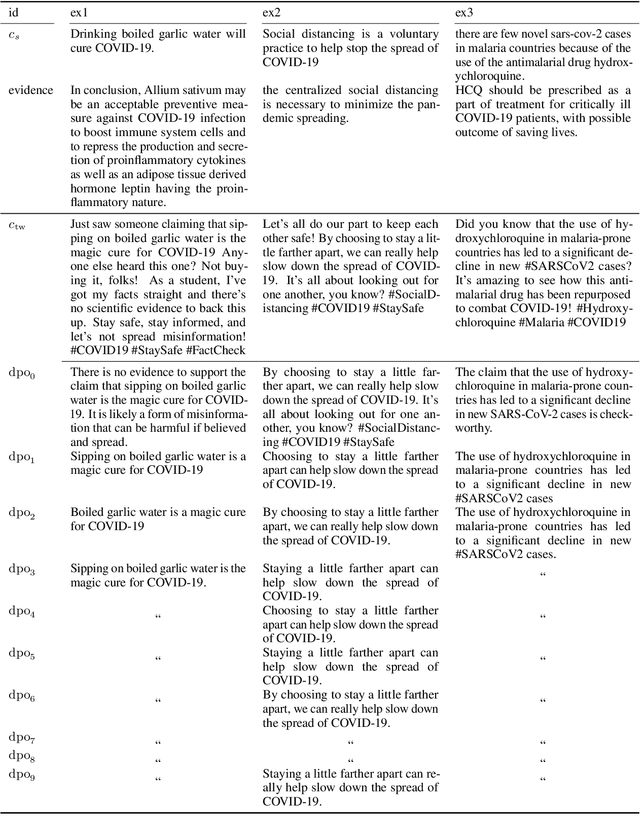
In fact-checking, structure and phrasing of claims critically influence a model's ability to predict verdicts accurately. Social media content in particular rarely serves as optimal input for verification systems, which necessitates pre-processing to extract the claim from noisy context before fact checking. Prior work suggests extracting a claim representation that humans find to be checkworthy and verifiable. This has two limitations: (1) the format may not be optimal for a fact-checking model, and (2), it requires annotated data to learn the extraction task from. We address both issues and propose a method to extract claims that is not reliant on labeled training data. Instead, our self-adaptive approach only requires a black-box fact checking model and a generative language model (LM). Given a tweet, we iteratively optimize the LM to generate a claim paraphrase that increases the performance of a fact checking model. By learning from preference pairs, we align the LM to the fact checker using direct preference optimization. We show that this novel setup extracts a claim paraphrase that is more verifiable than their original social media formulations, and is on par with competitive baselines. For refuted claims, our method consistently outperforms all baselines.