 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Expectation Detection in Language: A Case Study on Treatment Expectations in Reddit
Feb 17, 2026Patients' expectations towards their treatment have a substantial effect on the treatments' success. While primarily studied in clinical settings, online patient platforms like medical subreddits may hold complementary insights: treatment expectations that patients feel unnecessary or uncomfortable to share elsewhere. Despite this, no studies examine what type of expectations users discuss online and how they express them. Presumably this is because expectations have not been studied in natural language processing (NLP) before. Therefore, we introduce the task of Expectation Detection, arguing that expectations are relevant for many applications, including opinion mining and product design. Subsequently, we present a case study for the medical domain, where expectations are particularly crucial to extract. We contribute RedHOTExpect, a corpus of Reddit posts (4.5K posts) to study expectations in this context. We use a large language model (LLM) to silver-label the data and validate its quality manually (label accuracy ~78%). Based on this, we analyze which linguistic patterns characterize expectations and explore what patients expect and why. We find that optimism and proactive framing are more pronounced in posts about physical or treatment-related illnesses compared to mental-health contexts, and that in our dataset, patients mostly discuss benefits rather than negative outcomes. The RedHOTExpect corpus can be obtained from https://www.ims.uni-stuttgart.de/data/RedHOTExpect
What if Deception Cannot be Detected? A Cross-Linguistic Study on the Limits of Deception Detection from Text
May 19, 2025Can deception be detected solely from written text? Cues of deceptive communication are inherently subtle, even more so in text-only communication. Yet, prior studies have reported considerable success in automatic deception detection. We hypothesize that such findings are largely driven by artifacts introduced during data collection and do not generalize beyond specific datasets. We revisit this assumption by introducing a belief-based deception framework, which defines deception as a misalignment between an author's claims and true beliefs, irrespective of factual accuracy, allowing deception cues to be studied in isolation. Based on this framework, we construct three corpora, collectively referred to as DeFaBel, including a German-language corpus of deceptive and non-deceptive arguments and a multilingual version in German and English, each collected under varying conditions to account for belief change and enable cross-linguistic analysis. Using these corpora, we evaluate commonly reported linguistic cues of deception. Across all three DeFaBel variants, these cues show negligible, statistically insignificant correlations with deception labels, contrary to prior work that treats such cues as reliable indicators. We further benchmark against other English deception datasets following similar data collection protocols. While some show statistically significant correlations, effect sizes remain low and, critically, the set of predictive cues is inconsistent across datasets. We also evaluate deception detection using feature-based models, pretrained language models, and instruction-tuned large language models. While some models perform well on established deception datasets, they consistently perform near chance on DeFaBel. Our findings challenge the assumption that deception can be reliably inferred from linguistic cues and call for rethinking how deception is studied and modeled in NLP.
Which Demographics do LLMs Default to During Annotation?
Oct 11, 2024

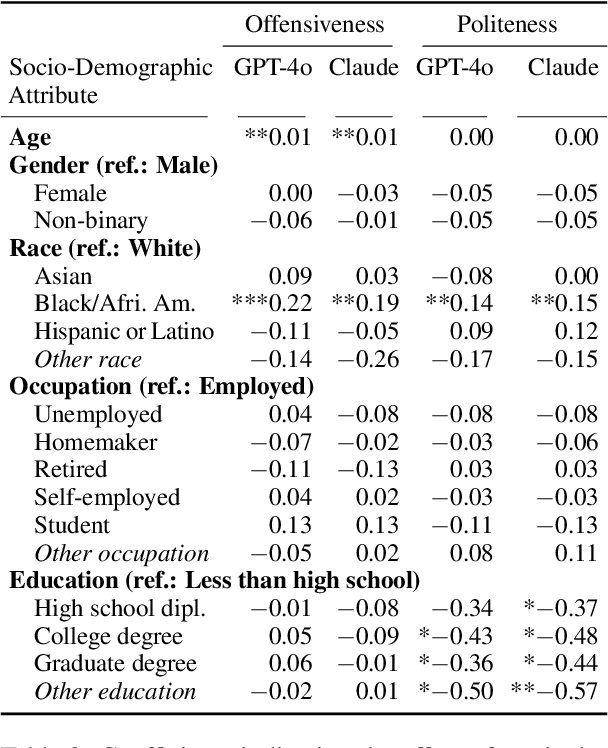
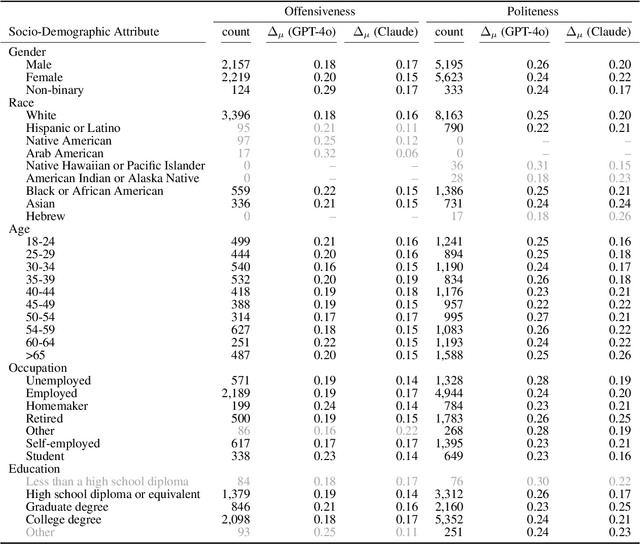
Demographics and cultural background of annotators influence the labels they assign in text annotation -- for instance, an elderly woman might find it offensive to read a message addressed to a "bro", but a male teenager might find it appropriate. It is therefore important to acknowledge label variations to not under-represent members of a society. Two research directions developed out of this observation in the context of using large language models (LLM) for data annotations, namely (1) studying biases and inherent knowledge of LLMs and (2) injecting diversity in the output by manipulating the prompt with demographic information. We combine these two strands of research and ask the question to which demographics an LLM resorts to when no demographics is given. To answer this question, we evaluate which attributes of human annotators LLMs inherently mimic. Furthermore, we compare non-demographic conditioned prompts and placebo-conditioned prompts (e.g., "you are an annotator who lives in house number 5") to demographics-conditioned prompts ("You are a 45 year old man and an expert on politeness annotation. How do you rate {instance}"). We study these questions for politeness and offensiveness annotations on the POPQUORN data set, a corpus created in a controlled manner to investigate human label variations based on demographics which has not been used for LLM-based analyses so far. We observe notable influences related to gender, race, and age in demographic prompting, which contrasts with previous studies that found no such effects.
How Entangled is Factuality and Deception in German?
Sep 30, 2024



The statement "The earth is flat" is factually inaccurate, but if someone truly believes and argues in its favor, it is not deceptive. Research on deception detection and fact checking often conflates factual accuracy with the truthfulness of statements. This assumption makes it difficult to (a) study subtle distinctions and interactions between the two and (b) gauge their effects on downstream tasks. The belief-based deception framework disentangles these properties by defining texts as deceptive when there is a mismatch between what people say and what they truly believe. In this study, we assess if presumed patterns of deception generalize to German language texts. We test the effectiveness of computational models in detecting deception using an established corpus of belief-based argumentation. Finally, we gauge the impact of deception on the downstream task of fact checking and explore if this property confounds verification models. Surprisingly, our analysis finds no correlation with established cues of deception. Previous work claimed that computational models can outperform humans in deception detection accuracy, however, our experiments show that both traditional and state-of-the-art models struggle with the task, performing no better than random guessing. For fact checking, we find that Natural Language Inference-based verification performs worse on non-factual and deceptive content, while prompting Large Language Models for the same task is less sensitive to these properties.
Can Factual Statements be Deceptive? The DeFaBel Corpus of Belief-based Deception
Mar 15, 2024



If a person firmly believes in a non-factual statement, such as "The Earth is flat", and argues in its favor, there is no inherent intention to deceive. As the argumentation stems from genuine belief, it may be unlikely to exhibit the linguistic properties associated with deception or lying. This interplay of factuality, personal belief, and intent to deceive remains an understudied area. Disentangling the influence of these variables in argumentation is crucial to gain a better understanding of the linguistic properties attributed to each of them. To study the relation between deception and factuality, based on belief, we present the DeFaBel corpus, a crowd-sourced resource of belief-based deception. To create this corpus, we devise a study in which participants are instructed to write arguments supporting statements like "eating watermelon seeds can cause indigestion", regardless of its factual accuracy or their personal beliefs about the statement. In addition to the generation task, we ask them to disclose their belief about the statement. The collected instances are labelled as deceptive if the arguments are in contradiction to the participants' personal beliefs. Each instance in the corpus is thus annotated (or implicitly labelled) with personal beliefs of the author, factuality of the statement, and the intended deceptiveness. The DeFaBel corpus contains 1031 texts in German, out of which 643 are deceptive and 388 are non-deceptive. It is the first publicly available corpus for studying deception in German. In our analysis, we find that people are more confident in the persuasiveness of their arguments when the statement is aligned with their belief, but surprisingly less confident when they are generating arguments in favor of facts. The DeFaBel corpus can be obtained from https://www.ims.uni-stuttgart.de/data/defabel
UNIDECOR: A Unified Deception Corpus for Cross-Corpus Deception Detection
Jun 07, 2023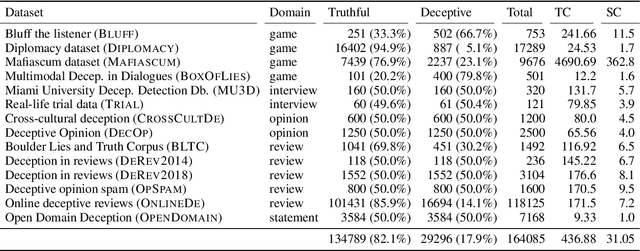
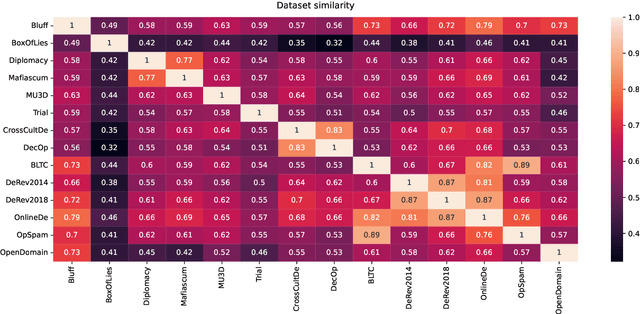
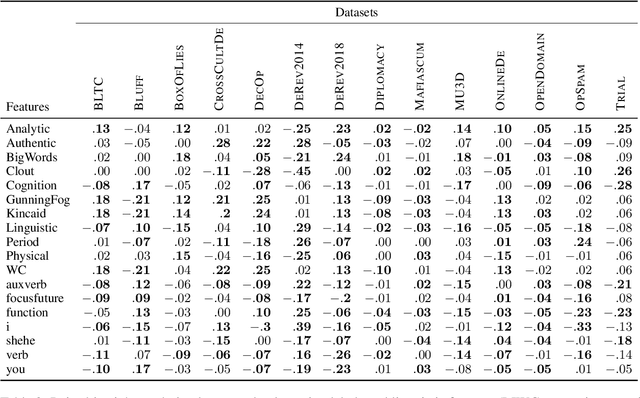
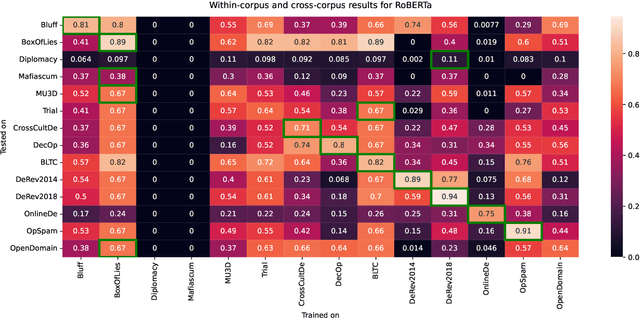
Verbal deception has been studied in psychology, forensics, and computational linguistics for a variety of reasons, like understanding behaviour patterns, identifying false testimonies, and detecting deception in online communication. Varying motivations across research fields lead to differences in the domain choices to study and in the conceptualization of deception, making it hard to compare models and build robust deception detection systems for a given language. With this paper, we improve this situation by surveying available English deception datasets which include domains like social media reviews, court testimonials, opinion statements on specific topics, and deceptive dialogues from online strategy games. We consolidate these datasets into a single unified corpus. Based on this resource, we conduct a correlation analysis of linguistic cues of deception across datasets to understand the differences and perform cross-corpus modeling experiments which show that a cross-domain generalization is challenging to achieve. The unified deception corpus (UNIDECOR) can be obtained from https://www.ims.uni-stuttgart.de/data/unidecor.
From Theories on Styles to their Transfer in Text: Bridging the Gap with a Hierarchical Survey
Nov 10, 2021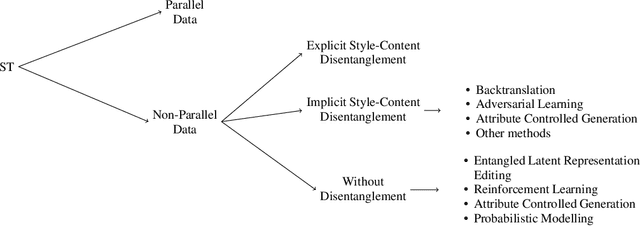

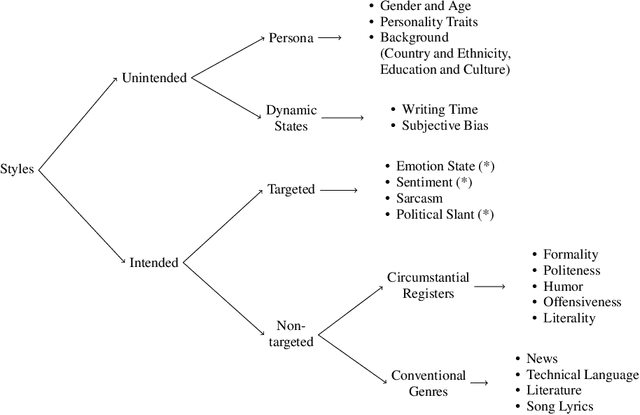

Humans are naturally endowed with the ability to write in a particular style. They can, for instance, rephrase a formal letter in an informal way, convey a literal message with the use of figures of speech, edit a novel mimicking the style of some well-known authors. Automating this form of creativity constitutes the goal of style transfer. As a natural language generation task, style transfer aims at re-writing existing texts, and specifically, it creates paraphrases that exhibit some desired stylistic attributes. From a practical perspective, it envisions beneficial applications, like chat-bots that modulate their communicative style to appear empathetic, or systems that automatically simplify technical articles for a non-expert audience. Style transfer has been dedicated several style-aware paraphrasing methods. A handful of surveys give a methodological overview of the field, but they do not support researchers to focus on specific styles. With this paper, we aim at providing a comprehensive discussion of the styles that have received attention in the transfer task. We organize them into a hierarchy, highlighting the challenges for the definition of each of them, and pointing out gaps in the current research landscape. The hierarchy comprises two main groups. One encompasses styles that people modulate arbitrarily, along the lines of registers and genres. The other group corresponds to unintentionally expressed styles, due to an author's personal characteristics. Hence, our review shows how the groups relate to one another, and where specific styles, including some that have never been explored, belong in the hierarchy. Moreover, we summarize the methods employed for different stylistic families, hinting researchers towards those that would be the most fitting for future research.