 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDimensional Modeling of Emotions in Text with Appraisal Theories: Corpus Creation, Annotation Reliability, and Prediction
Jun 13, 2022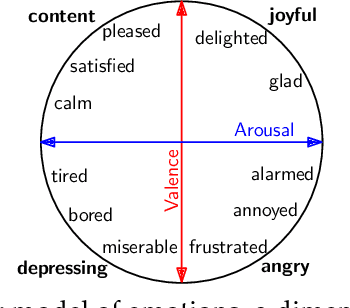

The most prominent tasks in emotion analysis are to assign emotions to texts and to understand how emotions manifest in language. An important observation for natural language processing is that emotions can be communicated implicitly by referring to events alone, appealing to an empathetic, intersubjective understanding of events, even without explicitly mentioning an emotion name. In psychology, the class of emotion theories known as appraisal theories aims at explaining the link between events and emotions. Appraisals can be formalized as variables that measure a cognitive evaluation by people living through an event that they consider relevant. They include the assessment if an event is novel, if the person considers themselves to be responsible, if it is in line with the own goals, and many others. Such appraisals explain which emotions are developed based on an event, e.g., that a novel situation can induce surprise or one with uncertain consequences could evoke fear. We analyze the suitability of appraisal theories for emotion analysis in text with the goal of understanding if appraisal concepts can reliably be reconstructed by annotators, if they can be predicted by text classifiers, and if appraisal concepts help to identify emotion categories. To achieve that, we compile a corpus by asking people to textually describe events that triggered particular emotions and to disclose their appraisals. Then, we ask readers to reconstruct emotions and appraisals from the text. This setup allows us to measure if emotions and appraisals can be recovered purely from text and provides a human baseline to judge model's performance measures. Our comparison of text classification methods to human annotators shows that both can reliably detect emotions and appraisals with similar performance. We further show that appraisal concepts improve the categorization of emotions in text.
x-enVENT: A Corpus of Event Descriptions with Experiencer-specific Emotion and Appraisal Annotations
Apr 08, 2022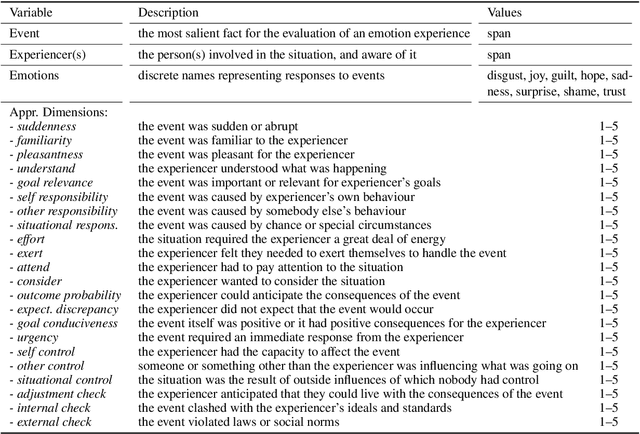
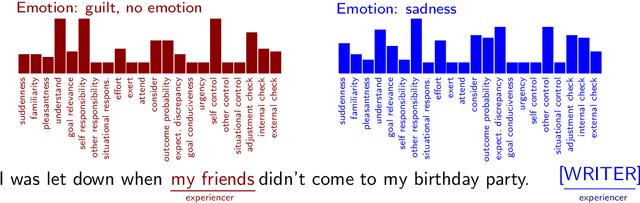

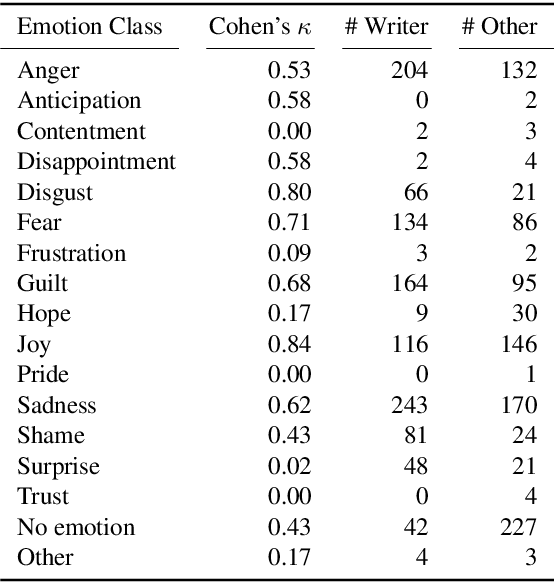
Emotion classification is often formulated as the task to categorize texts into a predefined set of emotion classes. So far, this task has been the recognition of the emotion of writers and readers, as well as that of entities mentioned in the text. We argue that a classification setup for emotion analysis should be performed in an integrated manner, including the different semantic roles that participate in an emotion episode. Based on appraisal theories in psychology, which treat emotions as reactions to events, we compile an English corpus of written event descriptions. The descriptions depict emotion-eliciting circumstances, and they contain mentions of people who responded emotionally. We annotate all experiencers, including the original author, with the emotions they likely felt. In addition, we link them to the event they found salient (which can be different for different experiencers in a text) by annotating event properties, or appraisals (e.g., the perceived event undesirability, the uncertainty of its outcome). Our analysis reveals patterns in the co-occurrence of people's emotions in interaction. Hence, this richly-annotated resource provides useful data to study emotions and event evaluations from the perspective of different roles, and it enables the development of experiencer-specific emotion and appraisal classification systems.
"splink" is happy and "phrouth" is scary: Emotion Intensity Analysis for Nonsense Words
Apr 05, 2022
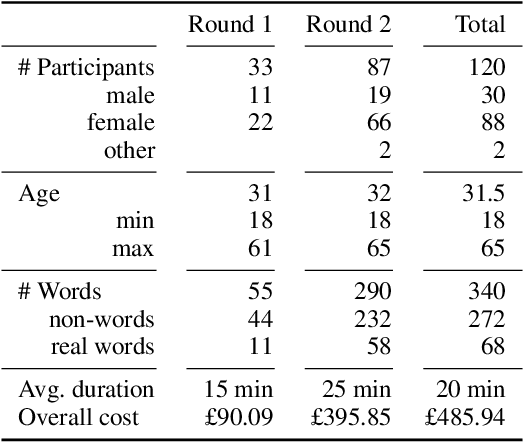
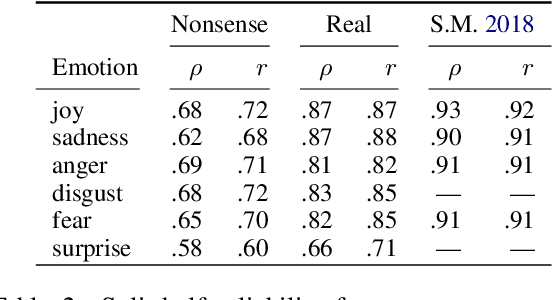
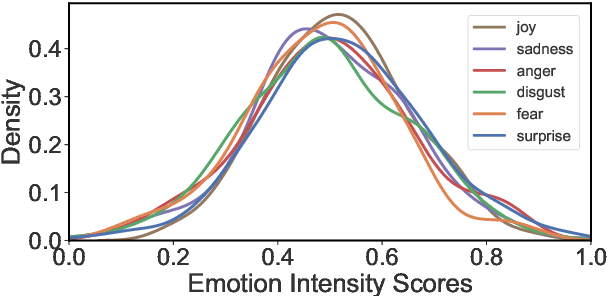
People associate affective meanings to words - "death" is scary and sad while "party" is connotated with surprise and joy. This raises the question if the association is purely a product of the learned affective imports inherent to semantic meanings, or is also an effect of other features of words, e.g., morphological and phonological patterns. We approach this question with an annotation-based analysis leveraging nonsense words. Specifically, we conduct a best-worst scaling crowdsourcing study in which participants assign intensity scores for joy, sadness, anger, disgust, fear, and surprise to 272 non-sense words and, for comparison of the results to previous work, to 68 real words. Based on this resource, we develop character-level and phonology-based intensity regressors. We evaluate them on both nonsense words and real words (making use of the NRC emotion intensity lexicon of 7493 words), across six emotion categories. The analysis of our data reveals that some phonetic patterns show clear differences between emotion intensities. For instance, s as a first phoneme contributes to joy, sh to surprise, p as last phoneme more to disgust than to anger and fear. In the modelling experiments, a regressor trained on real words from the NRC emotion intensity lexicon shows a higher performance (r = 0.17) than regressors that aim at learning the emotion connotation purely from nonsense words. We conclude that humans do associate affective meaning to words based on surface patterns, but also based on similarities to existing words ("juy" to "joy", or "flike" to "like").
From Theories on Styles to their Transfer in Text: Bridging the Gap with a Hierarchical Survey
Nov 10, 2021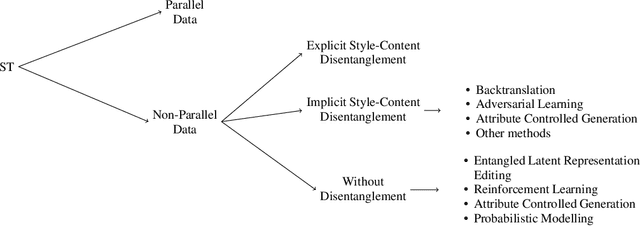

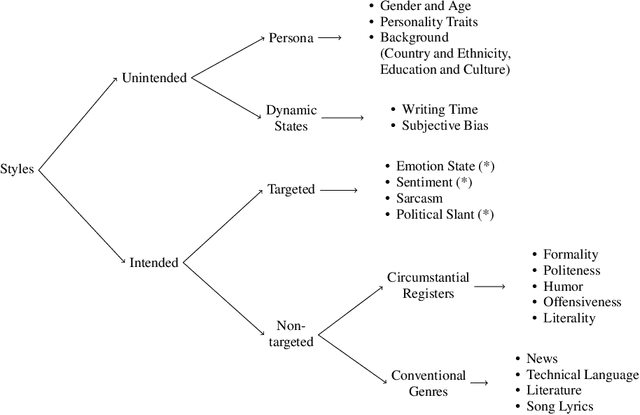

Humans are naturally endowed with the ability to write in a particular style. They can, for instance, rephrase a formal letter in an informal way, convey a literal message with the use of figures of speech, edit a novel mimicking the style of some well-known authors. Automating this form of creativity constitutes the goal of style transfer. As a natural language generation task, style transfer aims at re-writing existing texts, and specifically, it creates paraphrases that exhibit some desired stylistic attributes. From a practical perspective, it envisions beneficial applications, like chat-bots that modulate their communicative style to appear empathetic, or systems that automatically simplify technical articles for a non-expert audience. Style transfer has been dedicated several style-aware paraphrasing methods. A handful of surveys give a methodological overview of the field, but they do not support researchers to focus on specific styles. With this paper, we aim at providing a comprehensive discussion of the styles that have received attention in the transfer task. We organize them into a hierarchy, highlighting the challenges for the definition of each of them, and pointing out gaps in the current research landscape. The hierarchy comprises two main groups. One encompasses styles that people modulate arbitrarily, along the lines of registers and genres. The other group corresponds to unintentionally expressed styles, due to an author's personal characteristics. Hence, our review shows how the groups relate to one another, and where specific styles, including some that have never been explored, belong in the hierarchy. Moreover, we summarize the methods employed for different stylistic families, hinting researchers towards those that would be the most fitting for future research.
Emotion Ratings: How Intensity, Annotation Confidence and Agreements are Entangled
Mar 02, 2021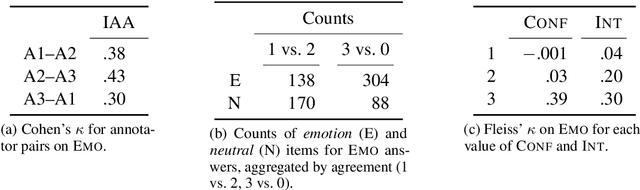
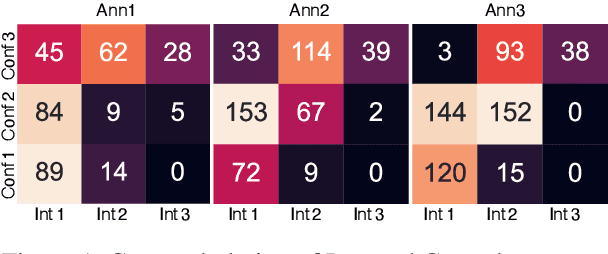

When humans judge the affective content of texts, they also implicitly assess the correctness of such judgment, that is, their confidence. We hypothesize that people's (in)confidence that they performed well in an annotation task leads to (dis)agreements among each other. If this is true, confidence may serve as a diagnostic tool for systematic differences in annotations. To probe our assumption, we conduct a study on a subset of the Corpus of Contemporary American English, in which we ask raters to distinguish neutral sentences from emotion-bearing ones, while scoring the confidence of their answers. Confidence turns out to approximate inter-annotator disagreements. Further, we find that confidence is correlated to emotion intensity: perceiving stronger affect in text prompts annotators to more certain classification performances. This insight is relevant for modelling studies of intensity, as it opens the question wether automatic regressors or classifiers actually predict intensity, or rather human's self-perceived confidence.
Emotion-Aware, Emotion-Agnostic, or Automatic: Corpus Creation Strategies to Obtain Cognitive Event Appraisal Annotations
Feb 25, 2021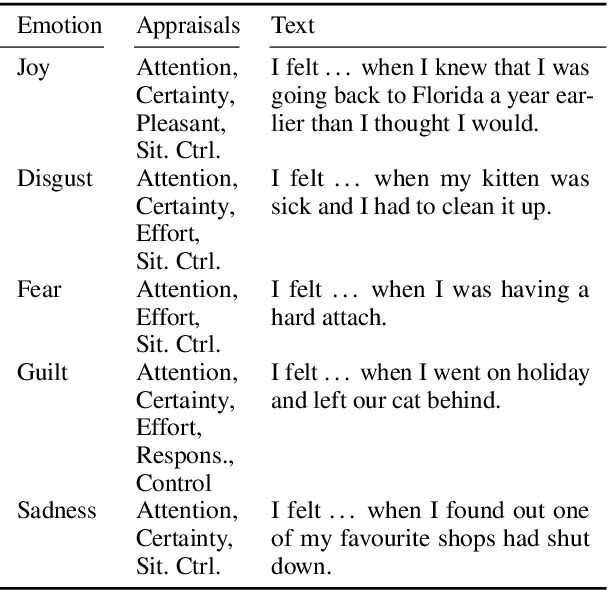


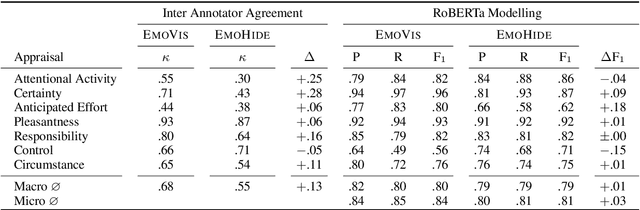
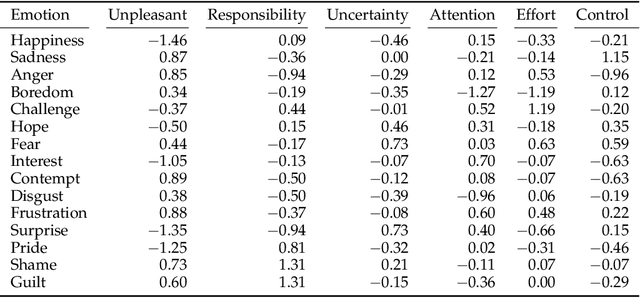
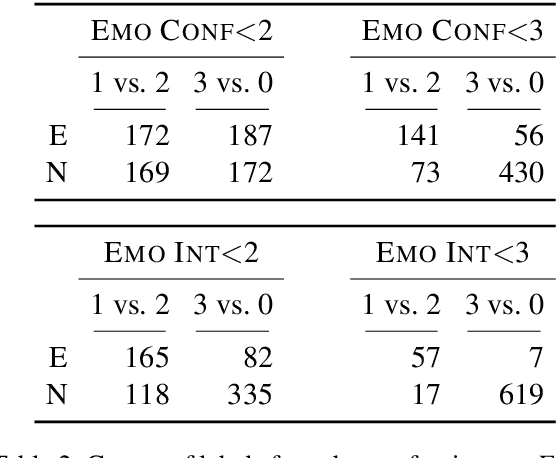
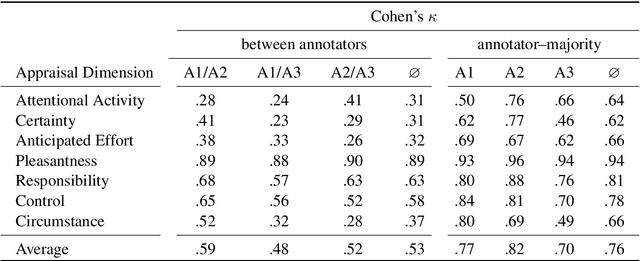
Appraisal theories explain how the cognitive evaluation of an event leads to a particular emotion. In contrast to theories of basic emotions or affect (valence/arousal), this theory has not received a lot of attention in natural language processing. Yet, in psychology it has been proven powerful: Smith and Ellsworth (1985) showed that the appraisal dimensions attention, certainty, anticipated effort, pleasantness, responsibility/control and situational control discriminate between (at least) 15 emotion classes. We study different annotation strategies for these dimensions, based on the event-focused enISEAR corpus (Troiano et al., 2019). We analyze two manual annotation settings: (1) showing the text to annotate while masking the experienced emotion label; (2) revealing the emotion associated with the text. Setting 2 enables the annotators to develop a more realistic intuition of the described event, while Setting 1 is a more standard annotation procedure, purely relying on text. We evaluate these strategies in two ways: by measuring inter-annotator agreement and by fine-tuning RoBERTa to predict appraisal variables. Our results show that knowledge of the emotion increases annotators' reliability. Further, we evaluate a purely automatic rule-based labeling strategy (inferring appraisal from annotated emotion classes). Training on automatically assigned labels leads to a competitive performance of our classifier, even when tested on manual annotations. This is an indicator that it might be possible to automatically create appraisal corpora for every domain for which emotion corpora already exist.
Challenges in Emotion Style Transfer: An Exploration with a Lexical Substitution Pipeline
May 15, 2020


We propose the task of emotion style transfer, which is particularly challenging, as emotions (here: anger, disgust, fear, joy, sadness, surprise) are on the fence between content and style. To understand the particular difficulties of this task, we design a transparent emotion style transfer pipeline based on three steps: (1) select the words that are promising to be substituted to change the emotion (with a brute-force approach and selection based on the attention mechanism of an emotion classifier), (2) find sets of words as candidates for substituting the words (based on lexical and distributional semantics), and (3) select the most promising combination of substitutions with an objective function which consists of components for content (based on BERT sentence embeddings), emotion (based on an emotion classifier), and fluency (based on a neural language model). This comparably straight-forward setup enables us to explore the task and understand in what cases lexical substitution can vary the emotional load of texts, how changes in content and style interact and if they are at odds. We further evaluate our pipeline quantitatively in an automated and an annotation study based on Tweets and find, indeed, that simultaneous adjustments of content and emotion are conflicting objectives: as we show in a qualitative analysis motivated by Scherer's emotion component model, this is particularly the case for implicit emotion expressions based on cognitive appraisal or descriptions of bodily reactions.
Appraisal Theories for Emotion Classification in Text
Apr 07, 2020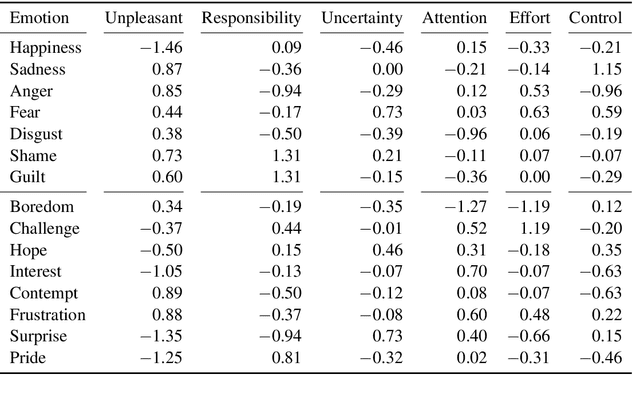
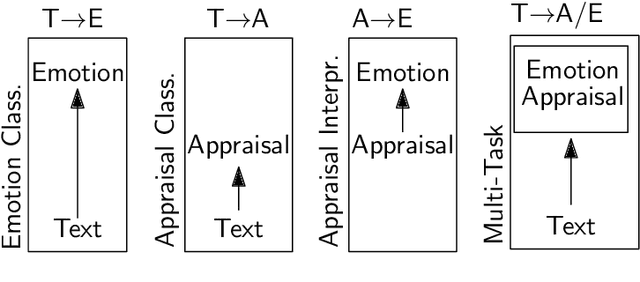
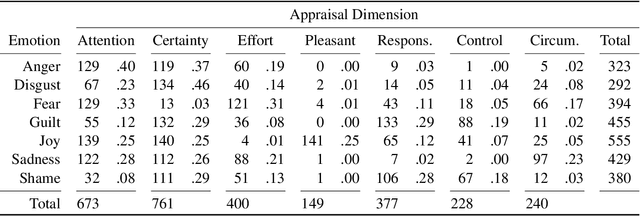
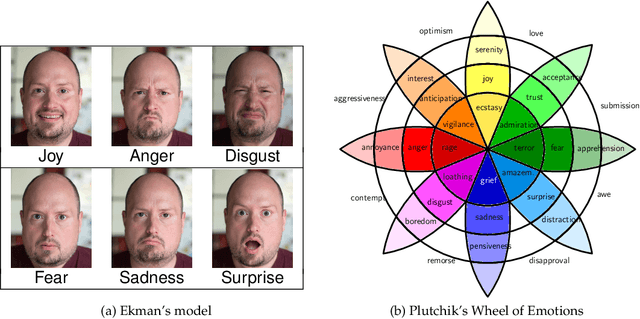
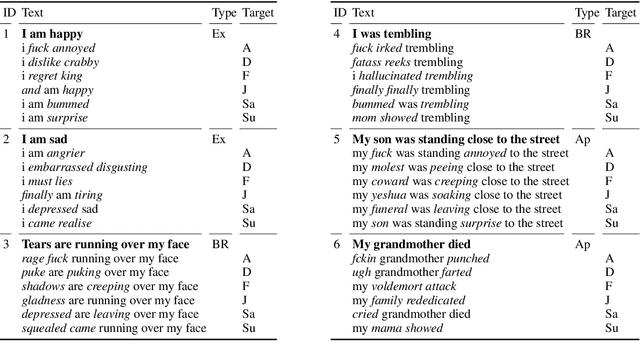
Automatic emotion categorization has been predominantly formulated as text classification in which textual units are assigned to an emotion from a predefined inventory, for instance following the fundamental emotion classes proposed by Paul Ekman (fear, joy, anger, disgust, sadness, surprise) or Robert Plutchik (adding trust, anticipation). This approach ignores existing psychological theories to some degree, which provide explanations regarding the perception of events (for instance, that somebody experiences fear when they discover a snake because of the appraisal as being an unpleasant and non-controllable situation), even without having access to explicit reports what an experiencer of an emotion is feeling (for instance expressing this with the words "I am afraid."). Automatic classification approaches therefore need to learn properties of events as latent variables (for instance that the uncertainty and effort associated with discovering the snake leads to fear). With this paper, we propose to make such interpretations of events explicit, following theories of cognitive appraisal of events and show their potential for emotion classification when being encoded in classification models. Our results show that high quality appraisal dimension assignments in event descriptions lead to an improvement in the classification of discrete emotion categories.
Crowdsourcing and Validating Event-focused Emotion Corpora for German and English
May 31, 2019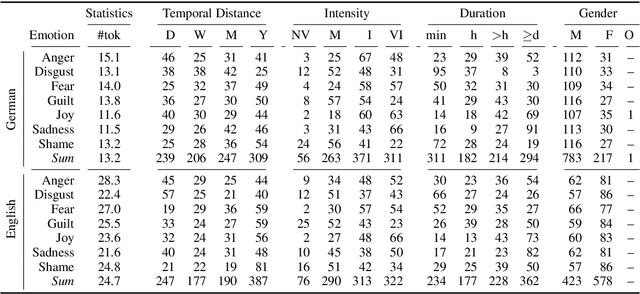
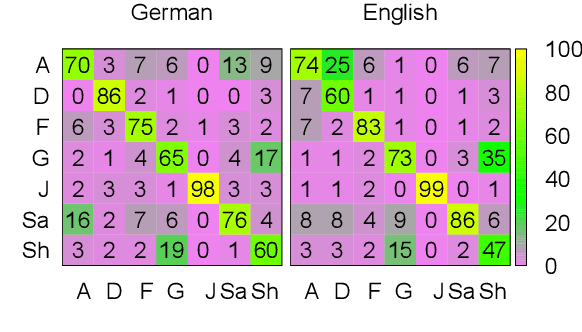
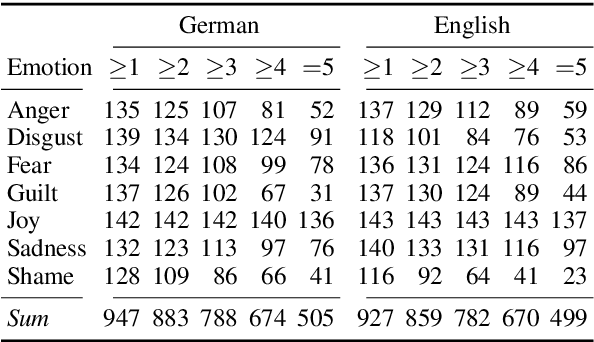
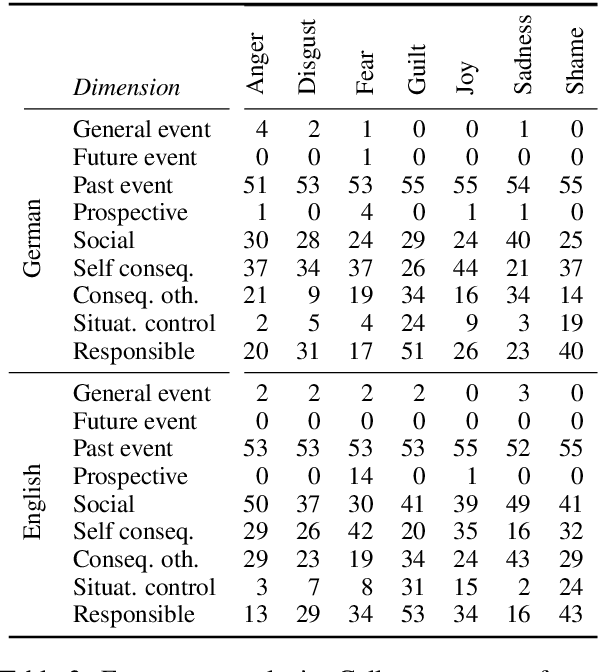
Sentiment analysis has a range of corpora available across multiple languages. For emotion analysis, the situation is more limited, which hinders potential research on cross-lingual modeling and the development of predictive models for other languages. In this paper, we fill this gap for German by constructing deISEAR, a corpus designed in analogy to the well-established English ISEAR emotion dataset. Motivated by Scherer's appraisal theory, we implement a crowdsourcing experiment which consists of two steps. In step 1, participants create descriptions of emotional events for a given emotion. In step 2, five annotators assess the emotion expressed by the texts. We show that transferring an emotion classification model from the original English ISEAR to the German crowdsourced deISEAR via machine translation does not, on average, cause a performance drop.