 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDimensional Modeling of Emotions in Text with Appraisal Theories: Corpus Creation, Annotation Reliability, and Prediction
Jun 13, 2022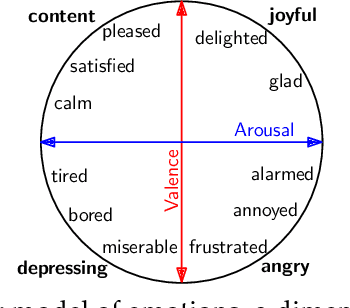
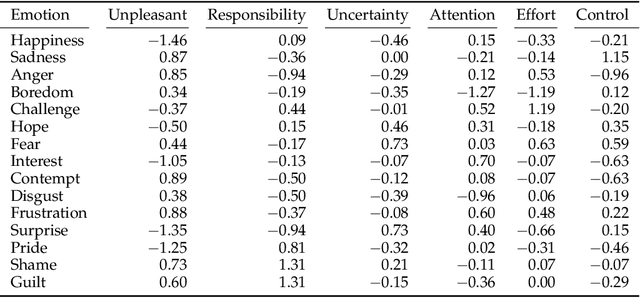

The most prominent tasks in emotion analysis are to assign emotions to texts and to understand how emotions manifest in language. An important observation for natural language processing is that emotions can be communicated implicitly by referring to events alone, appealing to an empathetic, intersubjective understanding of events, even without explicitly mentioning an emotion name. In psychology, the class of emotion theories known as appraisal theories aims at explaining the link between events and emotions. Appraisals can be formalized as variables that measure a cognitive evaluation by people living through an event that they consider relevant. They include the assessment if an event is novel, if the person considers themselves to be responsible, if it is in line with the own goals, and many others. Such appraisals explain which emotions are developed based on an event, e.g., that a novel situation can induce surprise or one with uncertain consequences could evoke fear. We analyze the suitability of appraisal theories for emotion analysis in text with the goal of understanding if appraisal concepts can reliably be reconstructed by annotators, if they can be predicted by text classifiers, and if appraisal concepts help to identify emotion categories. To achieve that, we compile a corpus by asking people to textually describe events that triggered particular emotions and to disclose their appraisals. Then, we ask readers to reconstruct emotions and appraisals from the text. This setup allows us to measure if emotions and appraisals can be recovered purely from text and provides a human baseline to judge model's performance measures. Our comparison of text classification methods to human annotators shows that both can reliably detect emotions and appraisals with similar performance. We further show that appraisal concepts improve the categorization of emotions in text.
x-enVENT: A Corpus of Event Descriptions with Experiencer-specific Emotion and Appraisal Annotations
Apr 08, 2022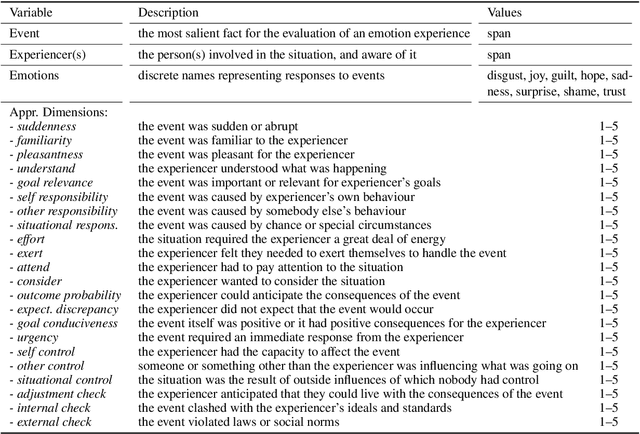
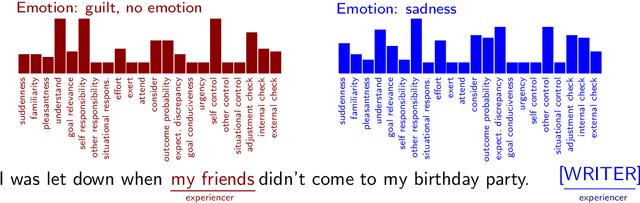

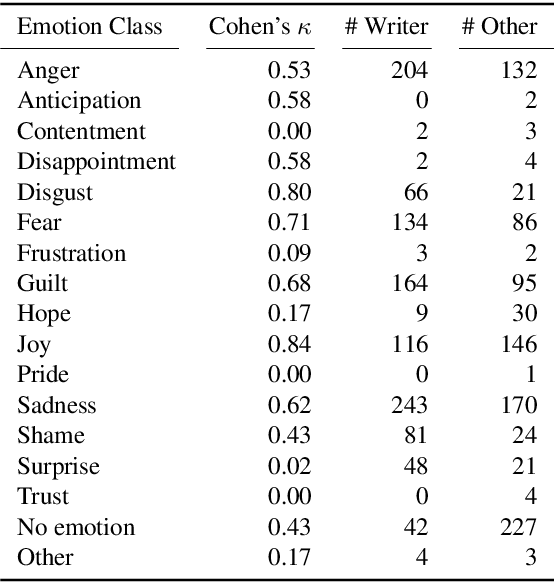
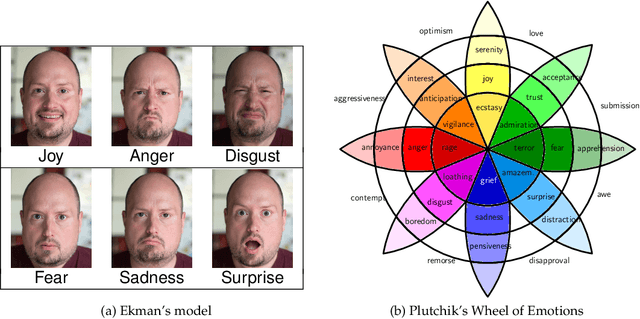
Emotion classification is often formulated as the task to categorize texts into a predefined set of emotion classes. So far, this task has been the recognition of the emotion of writers and readers, as well as that of entities mentioned in the text. We argue that a classification setup for emotion analysis should be performed in an integrated manner, including the different semantic roles that participate in an emotion episode. Based on appraisal theories in psychology, which treat emotions as reactions to events, we compile an English corpus of written event descriptions. The descriptions depict emotion-eliciting circumstances, and they contain mentions of people who responded emotionally. We annotate all experiencers, including the original author, with the emotions they likely felt. In addition, we link them to the event they found salient (which can be different for different experiencers in a text) by annotating event properties, or appraisals (e.g., the perceived event undesirability, the uncertainty of its outcome). Our analysis reveals patterns in the co-occurrence of people's emotions in interaction. Hence, this richly-annotated resource provides useful data to study emotions and event evaluations from the perspective of different roles, and it enables the development of experiencer-specific emotion and appraisal classification systems.
Emotion Stimulus Detection in German News Headlines
Jul 28, 2021
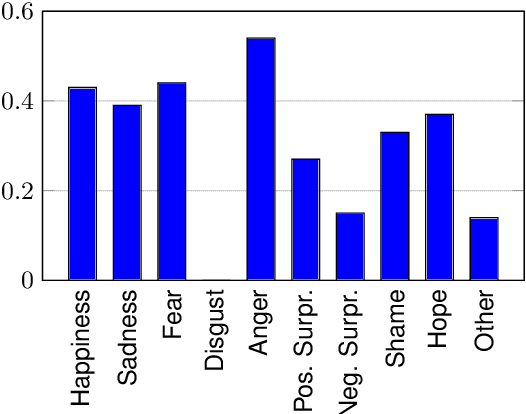
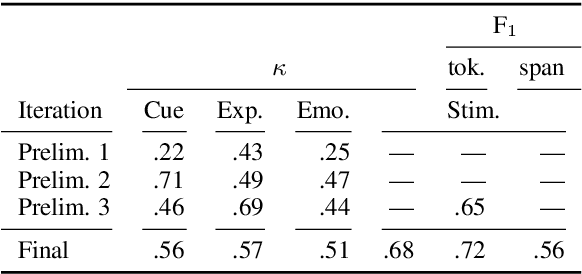
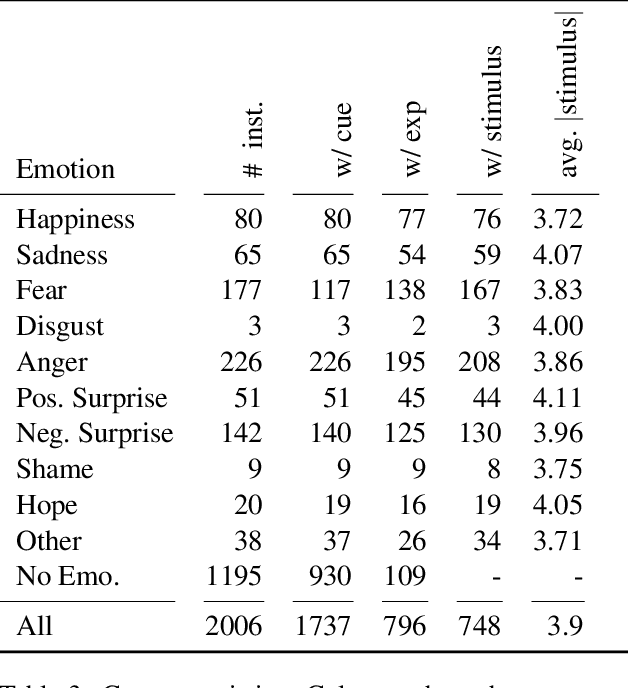
Emotion stimulus extraction is a fine-grained subtask of emotion analysis that focuses on identifying the description of the cause behind an emotion expression from a text passage (e.g., in the sentence "I am happy that I passed my exam" the phrase "passed my exam" corresponds to the stimulus.). Previous work mainly focused on Mandarin and English, with no resources or models for German. We fill this research gap by developing a corpus of 2006 German news headlines annotated with emotions and 811 instances with annotations of stimulus phrases. Given that such corpus creation efforts are time-consuming and expensive, we additionally work on an approach for projecting the existing English GoodNewsEveryone (GNE) corpus to a machine-translated German version. We compare the performance of a conditional random field (CRF) model (trained monolingually on German and cross-lingually via projection) with a multilingual XLM-RoBERTa (XLM-R) model. Our results show that training with the German corpus achieves higher F1 scores than projection. Experiments with XLM-R outperform their respective CRF counterparts.
Token Sequence Labeling vs. Clause Classification for English Emotion Stimulus Detection
Nov 09, 2020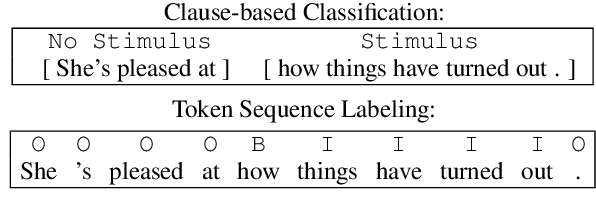

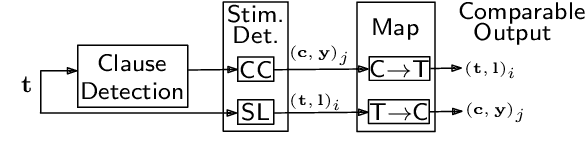
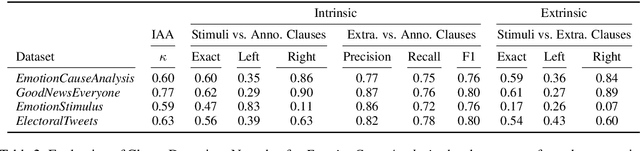
Emotion stimulus detection is the task of finding the cause of an emotion in a textual description, similar to target or aspect detection for sentiment analysis. Previous work approached this in three ways, namely (1) as text classification into an inventory of predefined possible stimuli ("Is the stimulus category A or B?"), (2) as sequence labeling of tokens ("Which tokens describe the stimulus?"), and (3) as clause classification ("Does this clause contain the emotion stimulus?"). So far, setting (3) has been evaluated broadly on Mandarin and (2) on English, but no comparison has been performed. Therefore, we aim to answer whether clause classification or sequence labeling is better suited for emotion stimulus detection in English. To accomplish that, we propose an integrated framework which enables us to evaluate the two different approaches comparably, implement models inspired by state-of-the-art approaches in Mandarin, and test them on four English data sets from different domains. Our results show that sequence labeling is superior on three out of four datasets, in both clause-based and sequence-based evaluation. The only case in which clause classification performs better is one data set with a high density of clause annotations. Our error analysis further confirms quantitatively and qualitatively that clauses are not the appropriate stimulus unit in English.
Experiencers, Stimuli, or Targets: Which Semantic Roles Enable Machine Learning to Infer the Emotions?
Nov 04, 2020
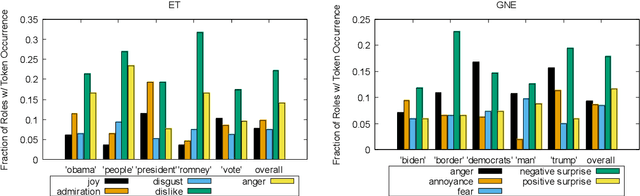

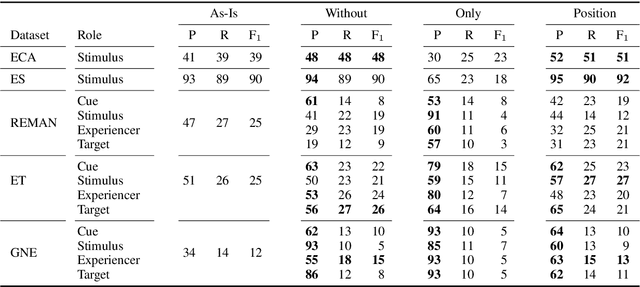
Emotion recognition is predominantly formulated as text classification in which textual units are assigned to an emotion from a predefined inventory (e.g., fear, joy, anger, disgust, sadness, surprise, trust, anticipation). More recently, semantic role labeling approaches have been developed to extract structures from the text to answer questions like: "who is described to feel the emotion?" (experiencer), "what causes this emotion?" (stimulus), and at which entity is it directed?" (target). Though it has been shown that jointly modeling stimulus and emotion category prediction is beneficial for both subtasks, it remains unclear which of these semantic roles enables a classifier to infer the emotion. Is it the experiencer, because the identity of a person is biased towards a particular emotion (X is always happy)? Is it a particular target (everybody loves X) or a stimulus (doing X makes everybody sad)? We answer these questions by training emotion classification models on five available datasets annotated with at least one semantic role by masking the fillers of these roles in the text in a controlled manner and find that across multiple corpora, stimuli and targets carry emotion information, while the experiencer might be considered a confounder. Further, we analyze if informing the model about the position of the role improves the classification decision. Particularly on literature corpora we find that the role information improves the emotion classification.