 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-based Personality Profiling: Reinforcement Learning for Relevance Filtering
Sep 06, 2024
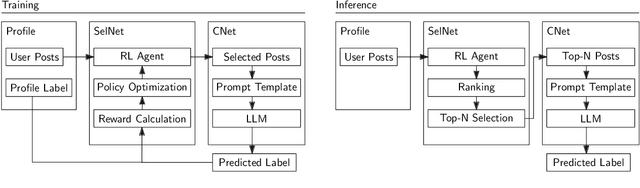

Author profiling is the task of inferring characteristics about individuals by analyzing content they share. Supervised machine learning still dominates automatic systems that perform this task, despite the popularity of prompting large language models to address natural language understanding tasks. One reason is that the classification instances consist of large amounts of posts, potentially a whole user profile, which may exceed the input length of Transformers. Even if a model can use a large context window, the entirety of posts makes the application of API-accessed black box systems costly and slow, next to issues which come with such "needle-in-the-haystack" tasks. To mitigate this limitation, we propose a new method for author profiling which aims at distinguishing relevant from irrelevant content first, followed by the actual user profiling only with relevant data. To circumvent the need for relevance-annotated data, we optimize this relevance filter via reinforcement learning with a reward function that utilizes the zero-shot capabilities of large language models. We evaluate our method for Big Five personality trait prediction on two Twitter corpora. On publicly available real-world data with a skewed label distribution, our method shows similar efficacy to using all posts in a user profile, but with a substantially shorter context. An evaluation on a version of these data balanced with artificial posts shows that the filtering to relevant posts leads to a significantly improved accuracy of the predictions.
Emotion-Aware, Emotion-Agnostic, or Automatic: Corpus Creation Strategies to Obtain Cognitive Event Appraisal Annotations
Feb 25, 2021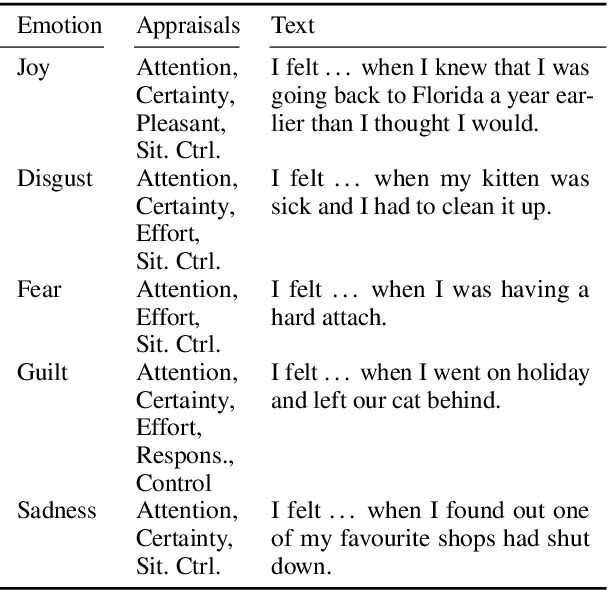


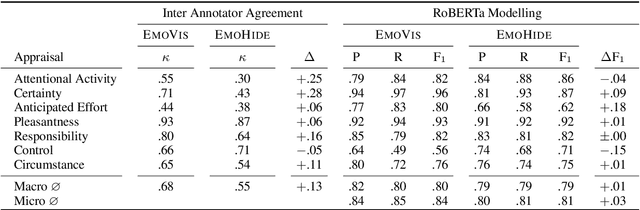
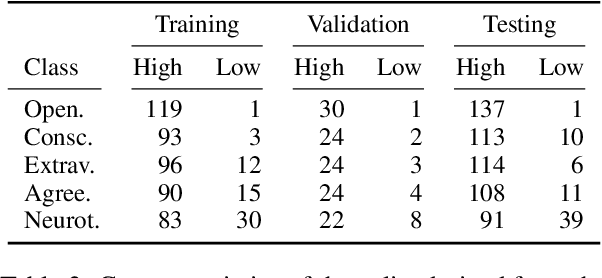
Appraisal theories explain how the cognitive evaluation of an event leads to a particular emotion. In contrast to theories of basic emotions or affect (valence/arousal), this theory has not received a lot of attention in natural language processing. Yet, in psychology it has been proven powerful: Smith and Ellsworth (1985) showed that the appraisal dimensions attention, certainty, anticipated effort, pleasantness, responsibility/control and situational control discriminate between (at least) 15 emotion classes. We study different annotation strategies for these dimensions, based on the event-focused enISEAR corpus (Troiano et al., 2019). We analyze two manual annotation settings: (1) showing the text to annotate while masking the experienced emotion label; (2) revealing the emotion associated with the text. Setting 2 enables the annotators to develop a more realistic intuition of the described event, while Setting 1 is a more standard annotation procedure, purely relying on text. We evaluate these strategies in two ways: by measuring inter-annotator agreement and by fine-tuning RoBERTa to predict appraisal variables. Our results show that knowledge of the emotion increases annotators' reliability. Further, we evaluate a purely automatic rule-based labeling strategy (inferring appraisal from annotated emotion classes). Training on automatically assigned labels leads to a competitive performance of our classifier, even when tested on manual annotations. This is an indicator that it might be possible to automatically create appraisal corpora for every domain for which emotion corpora already exist.
Appraisal Theories for Emotion Classification in Text
Apr 07, 2020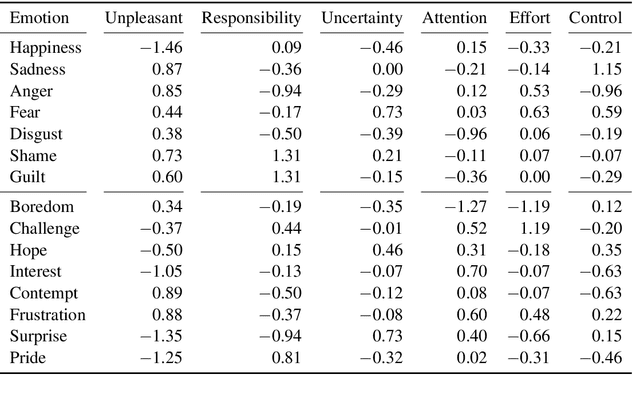
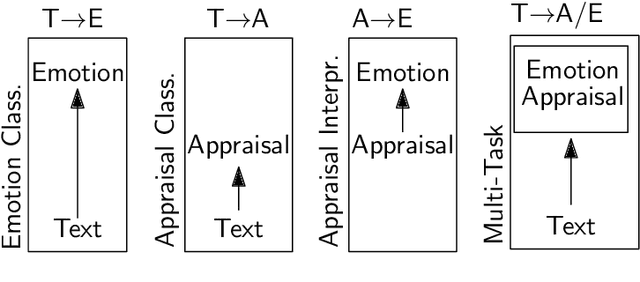
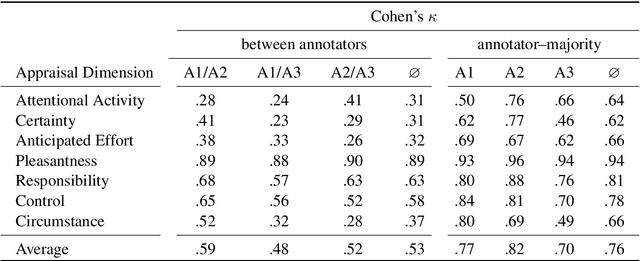
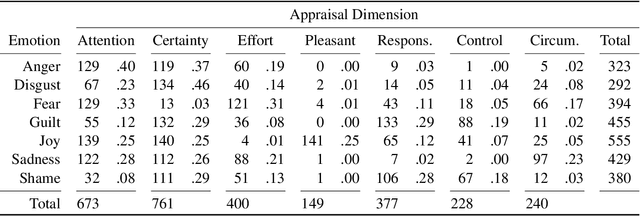
Automatic emotion categorization has been predominantly formulated as text classification in which textual units are assigned to an emotion from a predefined inventory, for instance following the fundamental emotion classes proposed by Paul Ekman (fear, joy, anger, disgust, sadness, surprise) or Robert Plutchik (adding trust, anticipation). This approach ignores existing psychological theories to some degree, which provide explanations regarding the perception of events (for instance, that somebody experiences fear when they discover a snake because of the appraisal as being an unpleasant and non-controllable situation), even without having access to explicit reports what an experiencer of an emotion is feeling (for instance expressing this with the words "I am afraid."). Automatic classification approaches therefore need to learn properties of events as latent variables (for instance that the uncertainty and effort associated with discovering the snake leads to fear). With this paper, we propose to make such interpretations of events explicit, following theories of cognitive appraisal of events and show their potential for emotion classification when being encoded in classification models. Our results show that high quality appraisal dimension assignments in event descriptions lead to an improvement in the classification of discrete emotion categories.