 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat if Deception Cannot be Detected? A Cross-Linguistic Study on the Limits of Deception Detection from Text
May 19, 2025Can deception be detected solely from written text? Cues of deceptive communication are inherently subtle, even more so in text-only communication. Yet, prior studies have reported considerable success in automatic deception detection. We hypothesize that such findings are largely driven by artifacts introduced during data collection and do not generalize beyond specific datasets. We revisit this assumption by introducing a belief-based deception framework, which defines deception as a misalignment between an author's claims and true beliefs, irrespective of factual accuracy, allowing deception cues to be studied in isolation. Based on this framework, we construct three corpora, collectively referred to as DeFaBel, including a German-language corpus of deceptive and non-deceptive arguments and a multilingual version in German and English, each collected under varying conditions to account for belief change and enable cross-linguistic analysis. Using these corpora, we evaluate commonly reported linguistic cues of deception. Across all three DeFaBel variants, these cues show negligible, statistically insignificant correlations with deception labels, contrary to prior work that treats such cues as reliable indicators. We further benchmark against other English deception datasets following similar data collection protocols. While some show statistically significant correlations, effect sizes remain low and, critically, the set of predictive cues is inconsistent across datasets. We also evaluate deception detection using feature-based models, pretrained language models, and instruction-tuned large language models. While some models perform well on established deception datasets, they consistently perform near chance on DeFaBel. Our findings challenge the assumption that deception can be reliably inferred from linguistic cues and call for rethinking how deception is studied and modeled in NLP.
Items from Psychometric Tests as Training Data for Personality Profiling Models of Twitter Users
Apr 08, 2022
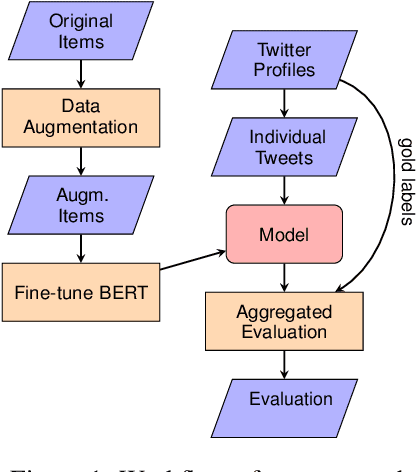

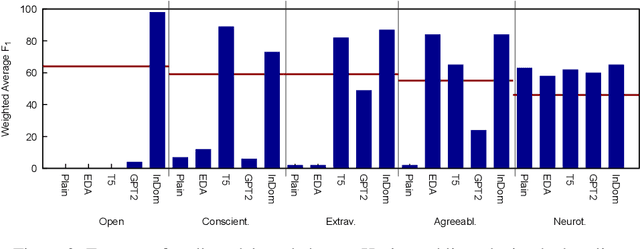
Machine-learned models for author profiling in social media often rely on data acquired via self-reporting-based psychometric tests (questionnaires) filled out by social media users. This is an expensive but accurate data collection strategy. Another, less costly alternative, which leads to potentially more noisy and biased data, is to rely on labels inferred from publicly available information in the profiles of the users, for instance self-reported diagnoses or test results. In this paper, we explore a third strategy, namely to directly use a corpus of items from validated psychometric tests as training data. Items from psychometric tests often consist of sentences from an I-perspective (e.g., "I make friends easily."). Such corpora of test items constitute 'small data', but their availability for many concepts is a rich resource. We investigate this approach for personality profiling, and evaluate BERT classifiers fine-tuned on such psychometric test items for the big five personality traits (openness, conscientiousness, extraversion, agreeableness, neuroticism) and analyze various augmentation strategies regarding their potential to address the challenges coming with such a small corpus. Our evaluation on a publicly available Twitter corpus shows a comparable performance to in-domain training for 4/5 personality traits with T5-based data augmentation.
Appraisal Theories for Emotion Classification in Text
Apr 07, 2020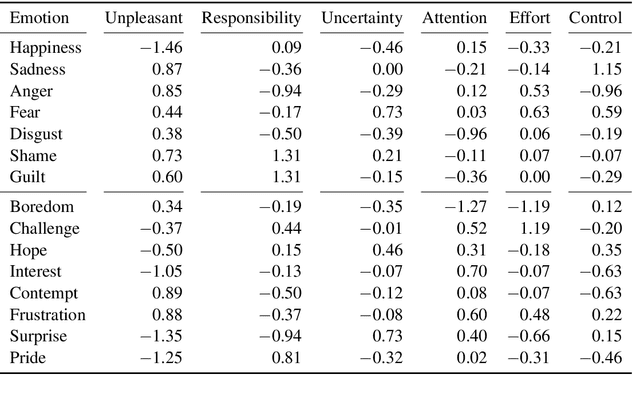
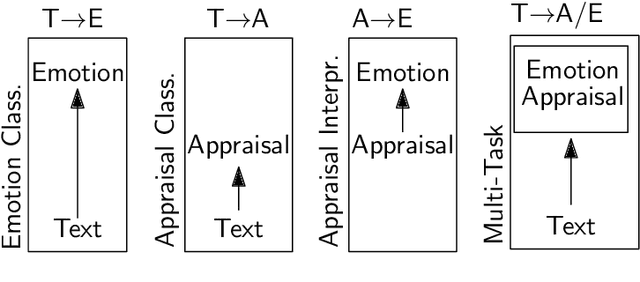
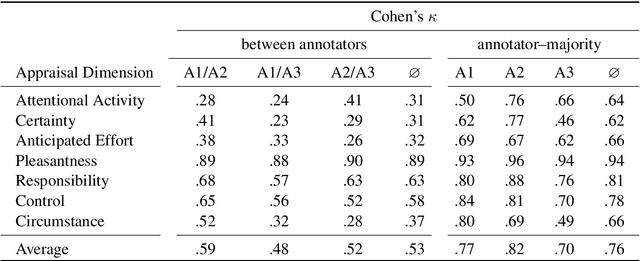
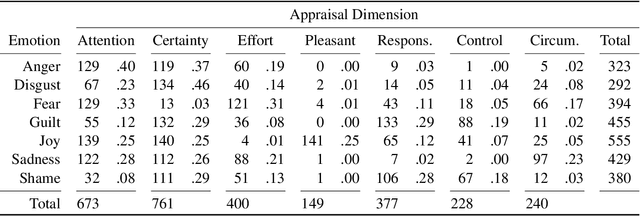
Automatic emotion categorization has been predominantly formulated as text classification in which textual units are assigned to an emotion from a predefined inventory, for instance following the fundamental emotion classes proposed by Paul Ekman (fear, joy, anger, disgust, sadness, surprise) or Robert Plutchik (adding trust, anticipation). This approach ignores existing psychological theories to some degree, which provide explanations regarding the perception of events (for instance, that somebody experiences fear when they discover a snake because of the appraisal as being an unpleasant and non-controllable situation), even without having access to explicit reports what an experiencer of an emotion is feeling (for instance expressing this with the words "I am afraid."). Automatic classification approaches therefore need to learn properties of events as latent variables (for instance that the uncertainty and effort associated with discovering the snake leads to fear). With this paper, we propose to make such interpretations of events explicit, following theories of cognitive appraisal of events and show their potential for emotion classification when being encoded in classification models. Our results show that high quality appraisal dimension assignments in event descriptions lead to an improvement in the classification of discrete emotion categories.