 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"splink" is happy and "phrouth" is scary: Emotion Intensity Analysis for Nonsense Words
Apr 05, 2022
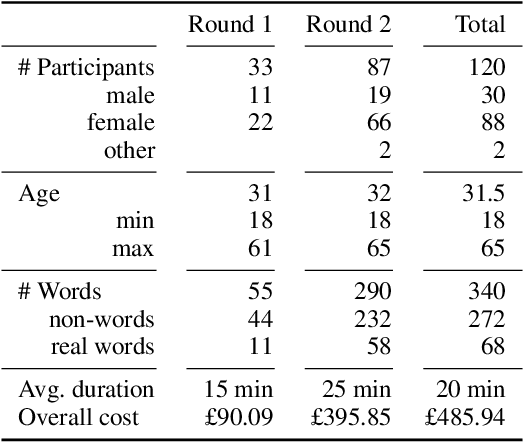
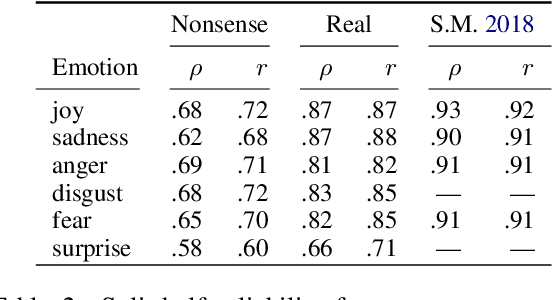
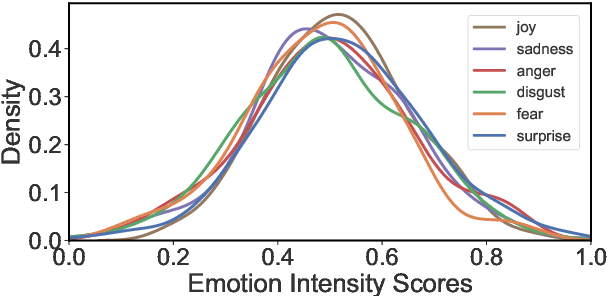
People associate affective meanings to words - "death" is scary and sad while "party" is connotated with surprise and joy. This raises the question if the association is purely a product of the learned affective imports inherent to semantic meanings, or is also an effect of other features of words, e.g., morphological and phonological patterns. We approach this question with an annotation-based analysis leveraging nonsense words. Specifically, we conduct a best-worst scaling crowdsourcing study in which participants assign intensity scores for joy, sadness, anger, disgust, fear, and surprise to 272 non-sense words and, for comparison of the results to previous work, to 68 real words. Based on this resource, we develop character-level and phonology-based intensity regressors. We evaluate them on both nonsense words and real words (making use of the NRC emotion intensity lexicon of 7493 words), across six emotion categories. The analysis of our data reveals that some phonetic patterns show clear differences between emotion intensities. For instance, s as a first phoneme contributes to joy, sh to surprise, p as last phoneme more to disgust than to anger and fear. In the modelling experiments, a regressor trained on real words from the NRC emotion intensity lexicon shows a higher performance (r = 0.17) than regressors that aim at learning the emotion connotation purely from nonsense words. We conclude that humans do associate affective meaning to words based on surface patterns, but also based on similarities to existing words ("juy" to "joy", or "flike" to "like").
Automatic Section Recognition in Obituaries
Feb 28, 2020


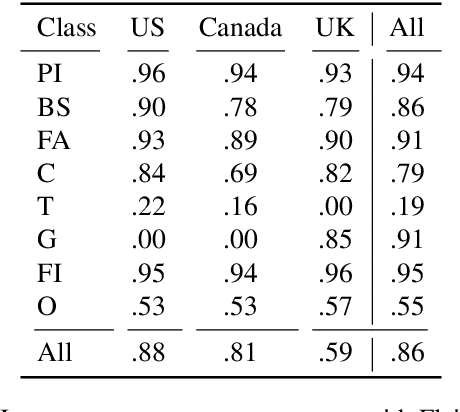
Obituaries contain information about people's values across times and cultures, which makes them a useful resource for exploring cultural history. They are typically structured similarly, with sections corresponding to Personal Information, Biographical Sketch, Characteristics, Family, Gratitude, Tribute, Funeral Information and Other aspects of the person. To make this information available for further studies, we propose a statistical model which recognizes these sections. To achieve that, we collect a corpus of 20058 English obituaries from TheDaily Item, Remembering.CA and The London Free Press. The evaluation of our annotation guidelines with three annotators on 1008 obituaries shows a substantial agreement of Fleiss k = 0.87. Formulated as an automatic segmentation task, a convolutional neural network outperforms bag-of-words and embedding-based BiLSTMs and BiLSTM-CRFs with a micro F1 = 0.81.