 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Section Recognition in Obituaries
Feb 28, 2020


Obituaries contain information about people's values across times and cultures, which makes them a useful resource for exploring cultural history. They are typically structured similarly, with sections corresponding to Personal Information, Biographical Sketch, Characteristics, Family, Gratitude, Tribute, Funeral Information and Other aspects of the person. To make this information available for further studies, we propose a statistical model which recognizes these sections. To achieve that, we collect a corpus of 20058 English obituaries from TheDaily Item, Remembering.CA and The London Free Press. The evaluation of our annotation guidelines with three annotators on 1008 obituaries shows a substantial agreement of Fleiss k = 0.87. Formulated as an automatic segmentation task, a convolutional neural network outperforms bag-of-words and embedding-based BiLSTMs and BiLSTM-CRFs with a micro F1 = 0.81.
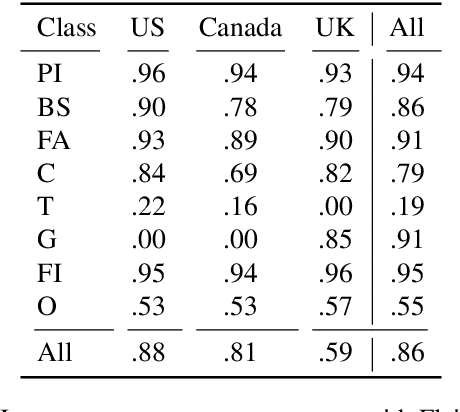
GoodNewsEveryone: A Corpus of News Headlines Annotated with Emotions, Semantic Roles, and Reader Perception
Dec 19, 2019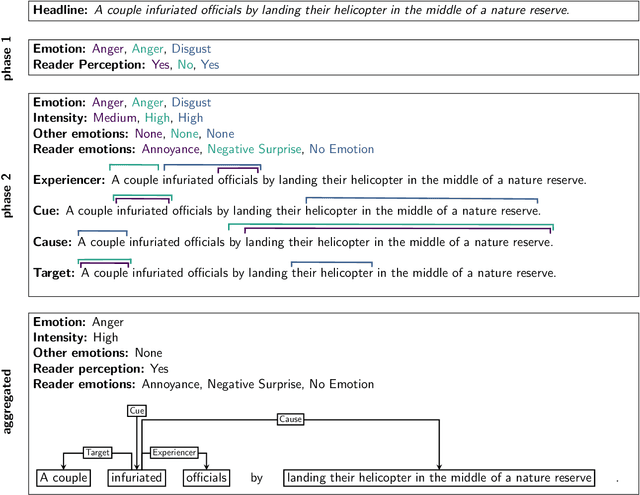
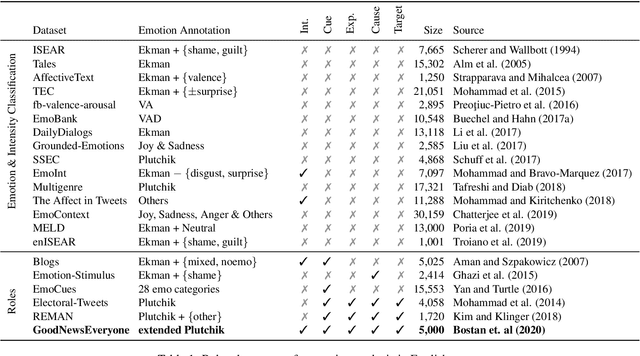
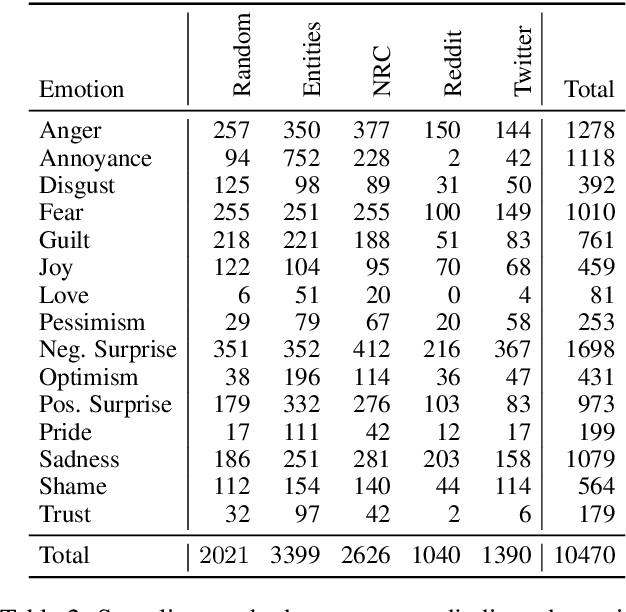
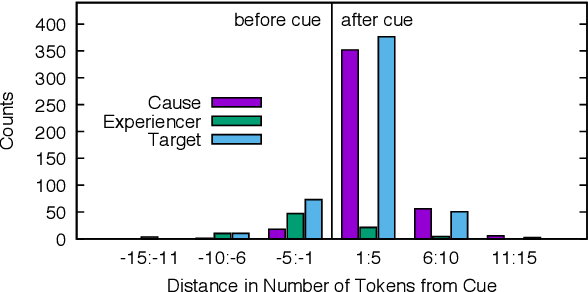
Most research on emotion analysis from text focuses on the task of emotion classification or emotion intensity regression. Fewer works address emotions as structured phenomena, which can be explained by the lack of relevant datasets and methods. We fill this gap by releasing a dataset of 5000 English news headlines annotated via crowdsourcing with their dominant emotions, emotion experiencers and textual cues, emotion causes and targets, as well as the reader's perception and emotion of the headline. We propose a multiphase annotation procedure which leads to high quality annotations on such a task via crowdsourcing. Finally, we develop a baseline for the task of automatic prediction of structures and discuss results. The corpus we release enables further research on emotion classification, emotion intensity prediction, emotion cause detection, and supports further qualitative studies.
Exploring Fine-Tuned Embeddings that Model Intensifiers for Emotion Analysis
Apr 05, 2019



Adjective phrases like "a little bit surprised", "completely shocked", or "not stunned at all" are not handled properly by currently published state-of-the-art emotion classification and intensity prediction systems which use pre-dominantly non-contextualized word embeddings as input. Based on this finding, we analyze differences between embeddings used by these systems in regard to their capability of handling such cases. Furthermore, we argue that intensifiers in context of emotion words need special treatment, as is established for sentiment polarity classification, but not for more fine-grained emotion prediction. To resolve this issue, we analyze different aspects of a post-processing pipeline which enriches the word representations of such phrases. This includes expansion of semantic spaces at the phrase level and sub-word level followed by retrofitting to emotion lexica. We evaluate the impact of these steps with A La Carte and Bag-of-Substrings extensions based on pretrained GloVe, Word2vec, and fastText embeddings against a crowd-sourced corpus of intensity annotations for tweets containing our focus phrases. We show that the fastText-based models do not gain from handling these specific phrases under inspection. For Word2vec embeddings, we show that our post-processing pipeline improves the results by up to 8% on a novel dataset densely populated with intensifiers.