 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePO-EMO: Conceptualization, Annotation, and Modeling of Aesthetic Emotions in German and English Poetry
Mar 17, 2020
Most approaches to emotion analysis regarding social media, literature, news, and other domains focus exclusively on basic emotion categories as defined by Ekman or Plutchik. However, art (such as literature) enables engagement in a broader range of more complex and subtle emotions that have been shown to also include mixed emotional responses. We consider emotions as they are elicited in the reader, rather than what is expressed in the text or intended by the author. Thus, we conceptualize a set of aesthetic emotions that are predictive of aesthetic appreciation in the reader, and allow the annotation of multiple labels per line to capture mixed emotions within context. We evaluate this novel setting in an annotation experiment both with carefully trained experts and via crowdsourcing. Our annotation with experts leads to an acceptable agreement of kappa=.70, resulting in a consistent dataset for future large scale analysis. Finally, we conduct first emotion classification experiments based on BERT, showing that identifying aesthetic emotions is challenging in our data, with up to .52 F1-micro on the German subset. Data and resources are available at https://github.com/tnhaider/poetry-emotion
* Emotion, Aesthetic Emotions, Literature, Poetry, Annotation, Corpora, Emotion Recognition, Multi-Label
GoodNewsEveryone: A Corpus of News Headlines Annotated with Emotions, Semantic Roles, and Reader Perception
Dec 19, 2019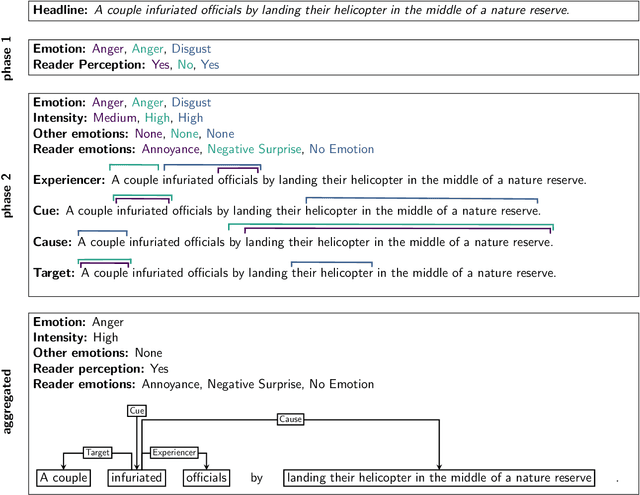
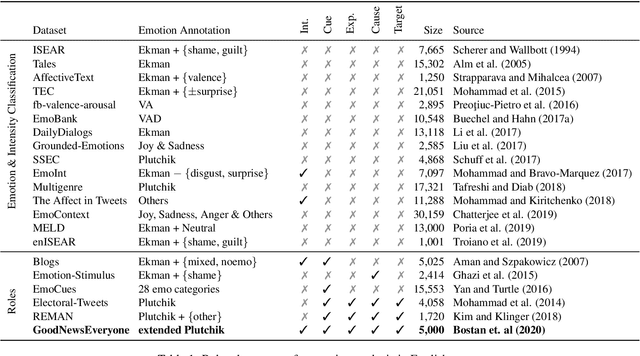
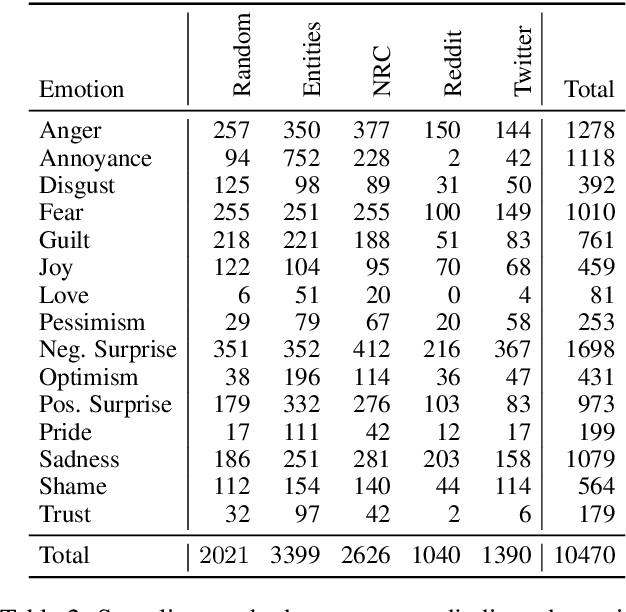
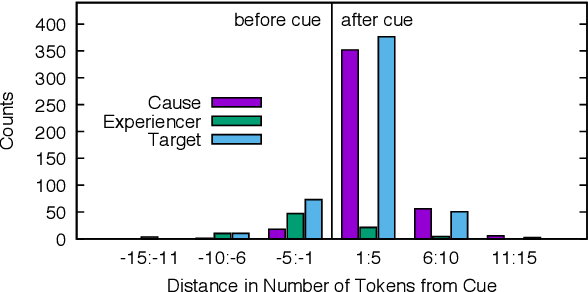
Most research on emotion analysis from text focuses on the task of emotion classification or emotion intensity regression. Fewer works address emotions as structured phenomena, which can be explained by the lack of relevant datasets and methods. We fill this gap by releasing a dataset of 5000 English news headlines annotated via crowdsourcing with their dominant emotions, emotion experiencers and textual cues, emotion causes and targets, as well as the reader's perception and emotion of the headline. We propose a multiphase annotation procedure which leads to high quality annotations on such a task via crowdsourcing. Finally, we develop a baseline for the task of automatic prediction of structures and discuss results. The corpus we release enables further research on emotion classification, emotion intensity prediction, emotion cause detection, and supports further qualitative studies.
An Analysis of Emotion Communication Channels in Fan Fiction: Towards Emotional Storytelling
Jun 06, 2019


Centrality of emotion for the stories told by humans is underpinned by numerous studies in literature and psychology. The research in automatic storytelling has recently turned towards emotional storytelling, in which characters' emotions play an important role in the plot development. However, these studies mainly use emotion to generate propositional statements in the form "A feels affection towards B" or "A confronts B". At the same time, emotional behavior does not boil down to such propositional descriptions, as humans display complex and highly variable patterns in communicating their emotions, both verbally and non-verbally. In this paper, we analyze how emotions are expressed non-verbally in a corpus of fan fiction short stories. Our analysis shows that stories written by humans convey character emotions along various non-verbal channels. We find that some non-verbal channels, such as facial expressions and voice characteristics of the characters, are more strongly associated with joy, while gestures and body postures are more likely to occur with trust. Based on our analysis, we argue that automatic storytelling systems should take variability of emotion into account when generating descriptions of characters' emotions.
Frowning Frodo, Wincing Leia, and a Seriously Great Friendship: Learning to Classify Emotional Relationships of Fictional Characters
Apr 01, 2019
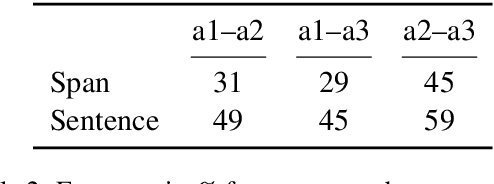
The development of a fictional plot is centered around characters who closely interact with each other forming dynamic social networks. In literature analysis, such networks have mostly been analyzed without particular relation types or focusing on roles which the characters take with respect to each other. We argue that an important aspect for the analysis of stories and their development is the emotion between characters. In this paper, we combine these aspects into a unified framework to classify emotional relationships of fictional characters. We formalize it as a new task and describe the annotation of a corpus, based on fan-fiction short stories. The extraction pipeline which we propose consists of character identification (which we treat as given by an oracle here) and the relation classification. For the latter, we provide results using several approaches previously proposed for relation identification with neural methods. The best result of 0.45 F1 is achieved with a GRU with character position indicators on the task of predicting undirected emotion relations in the associated social network graph.
A Survey on Sentiment and Emotion Analysis for Computational Literary Studies
Aug 09, 2018
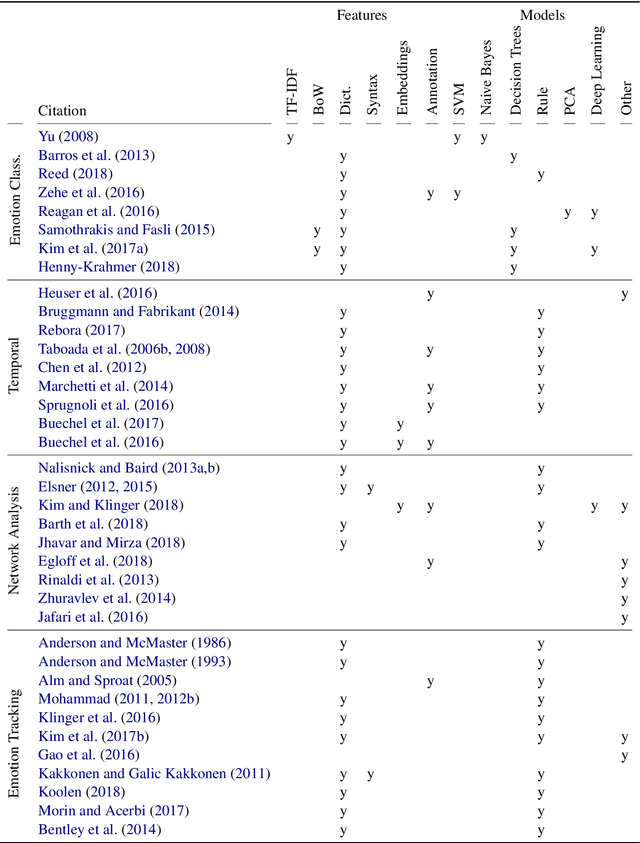
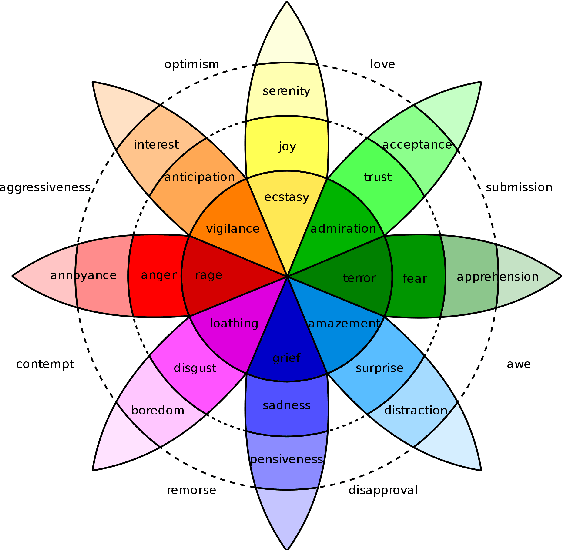
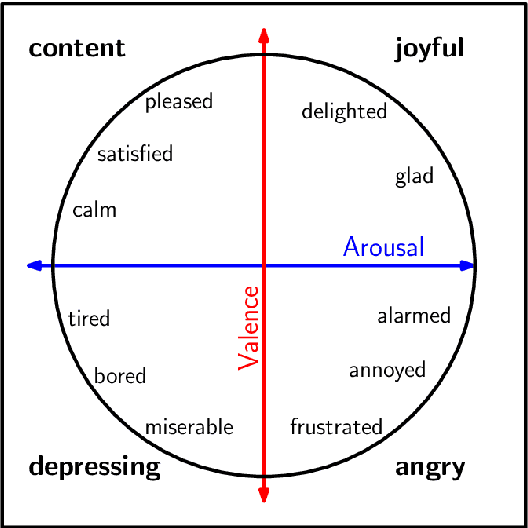
Emotions have often been a crucial part of compelling narratives: literature tells about people with goals, desires, passions, and intentions. In the past, classical literary studies usually scrutinized the affective dimension of literature within the framework of hermeneutics. However, with emergence of the research field known as Digital Humanities (DH) some studies of emotions in literary context have taken a computational turn. Given the fact that DH is still being formed as a science, this direction of research can be rendered relatively new. At the same time, the research in sentiment analysis started in computational linguistic almost two decades ago and is nowadays an established field that has dedicated workshops and tracks in the main computational linguistics conferences. This leads us to the question of what are the commonalities and discrepancies between sentiment analysis research in computational linguistics and digital humanities? In this survey, we offer an overview of the existing body of research on sentiment and emotion analysis as applied to literature. We precede the main part of the survey with a short introduction to natural language processing and machine learning, psychological models of emotions, and provide an overview of existing approaches to sentiment and emotion analysis in computational linguistics. The papers presented in this survey are either coming directly from DH or computational linguistics venues and are limited to sentiment and emotion analysis as applied to literary text.