 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoodNewsEveryone: A Corpus of News Headlines Annotated with Emotions, Semantic Roles, and Reader Perception
Paper and Code
Dec 19, 2019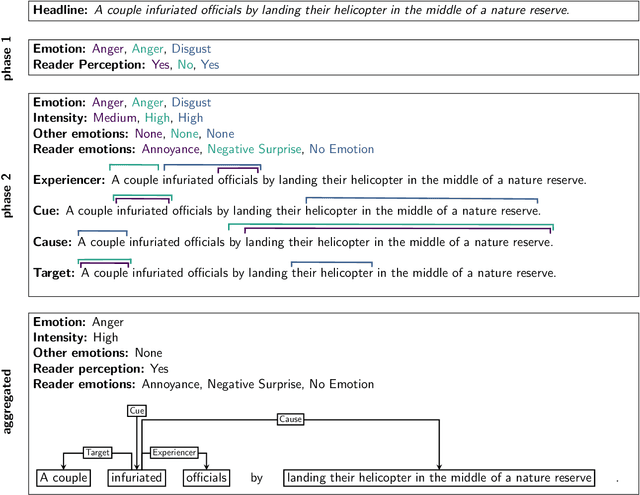
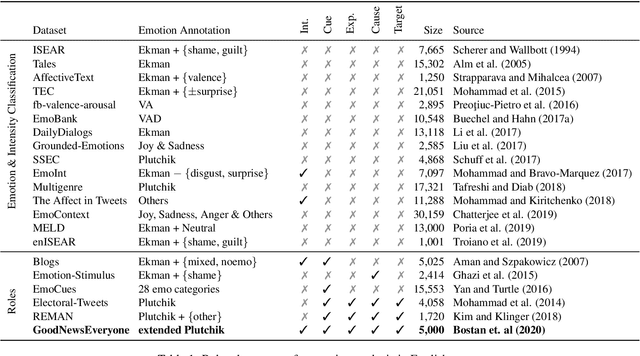
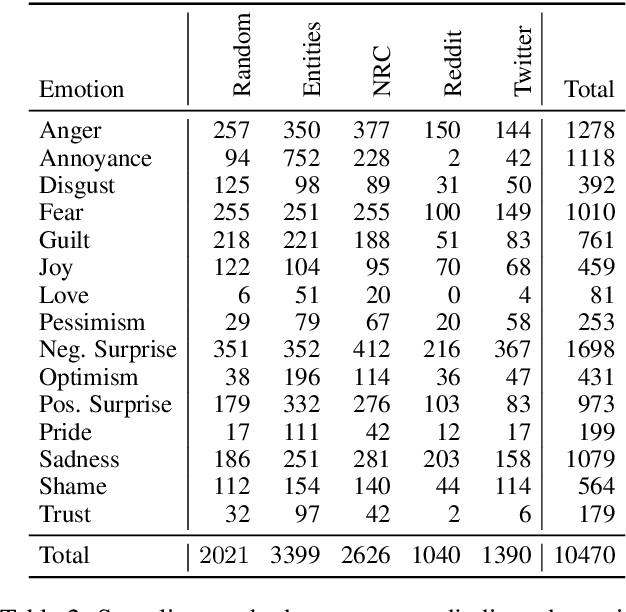
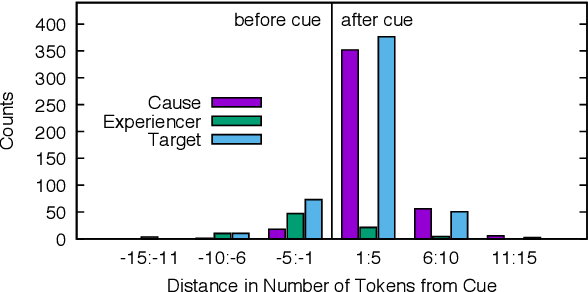
Most research on emotion analysis from text focuses on the task of emotion classification or emotion intensity regression. Fewer works address emotions as structured phenomena, which can be explained by the lack of relevant datasets and methods. We fill this gap by releasing a dataset of 5000 English news headlines annotated via crowdsourcing with their dominant emotions, emotion experiencers and textual cues, emotion causes and targets, as well as the reader's perception and emotion of the headline. We propose a multiphase annotation procedure which leads to high quality annotations on such a task via crowdsourcing. Finally, we develop a baseline for the task of automatic prediction of structures and discuss results. The corpus we release enables further research on emotion classification, emotion intensity prediction, emotion cause detection, and supports further qualitative studies.