 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantification of Biodiversity from Historical Survey Text with LLM-based Best-Worst Scaling
Feb 06, 2025In this study, we evaluate methods to determine the frequency of species via quantity estimation from historical survey text. To that end, we formulate classification tasks and finally show that this problem can be adequately framed as a regression task using Best-Worst Scaling (BWS) with Large Language Models (LLMs). We test Ministral-8B, DeepSeek-V3, and GPT-4, finding that the latter two have reasonable agreement with humans and each other. We conclude that this approach is more cost-effective and similarly robust compared to a fine-grained multi-class approach, allowing automated quantity estimation across species.
Distant Reading of the German Coalition Deal: Recognizing Policy Positions with BERT-based Text Classification
Dec 30, 2022Automated text analysis has become a widely used tool in political science. In this research, we use a BERT model trained on German party manifestos to identify the individual parties' contribution to the coalition agreement of 2021.
Identifying the root cause of cable network problems with machine learning
Mar 15, 2022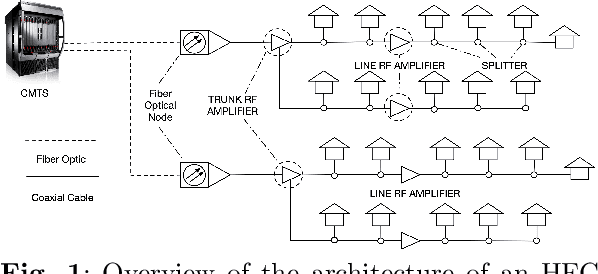
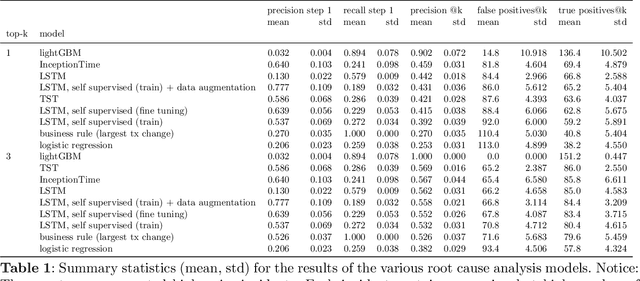
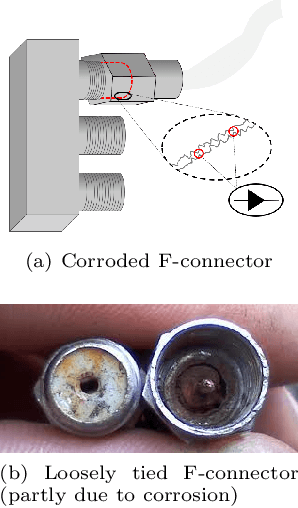
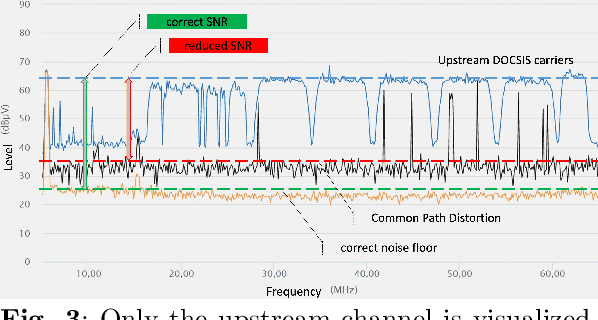
Good quality network connectivity is ever more important. For hybrid fiber coaxial (HFC) networks, searching for upstream high noise in the past was cumbersome and time-consuming. Even with machine learning due to the heterogeneity of the network and its topological structure, the task remains challenging. We present the automation of a simple business rule (largest change of a specific value) and compare its performance with state-of-the-art machine-learning methods and conclude that the precision@1 can be improved by 2.3 times. As it is best when a fault does not occur in the first place, we secondly evaluate multiple approaches to forecast network faults, which would allow performing predictive maintenance on the network.
Metrical Tagging in the Wild: Building and Annotating Poetry Corpora with Rhythmic Features
Feb 17, 2021
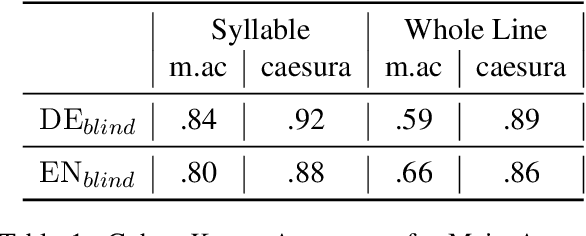
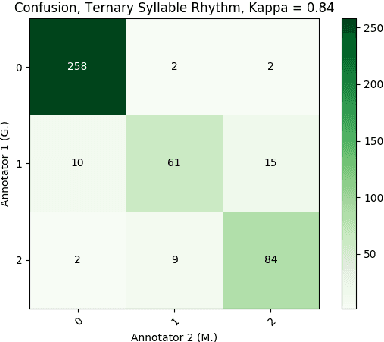
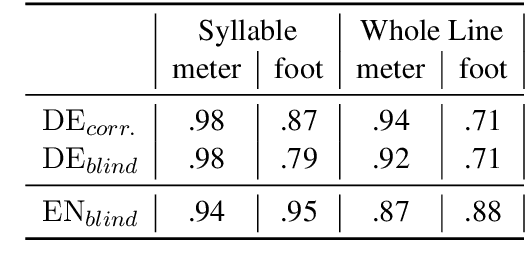
A prerequisite for the computational study of literature is the availability of properly digitized texts, ideally with reliable meta-data and ground-truth annotation. Poetry corpora do exist for a number of languages, but larger collections lack consistency and are encoded in various standards, while annotated corpora are typically constrained to a particular genre and/or were designed for the analysis of certain linguistic features (like rhyme). In this work, we provide large poetry corpora for English and German, and annotate prosodic features in smaller corpora to train corpus driven neural models that enable robust large scale analysis. We show that BiLSTM-CRF models with syllable embeddings outperform a CRF baseline and different BERT-based approaches. In a multi-task setup, particular beneficial task relations illustrate the inter-dependence of poetic features. A model learns foot boundaries better when jointly predicting syllable stress, aesthetic emotions and verse measures benefit from each other, and we find that caesuras are quite dependent on syntax and also integral to shaping the overall measure of the line.
PO-EMO: Conceptualization, Annotation, and Modeling of Aesthetic Emotions in German and English Poetry
Mar 17, 2020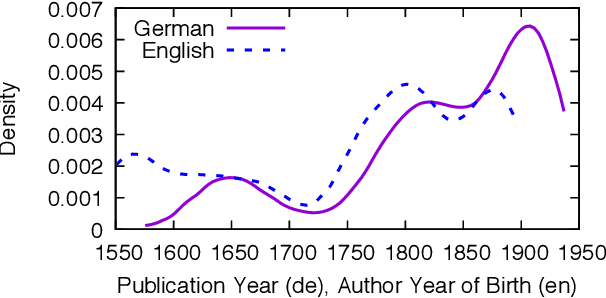
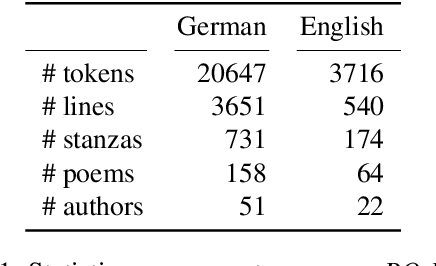
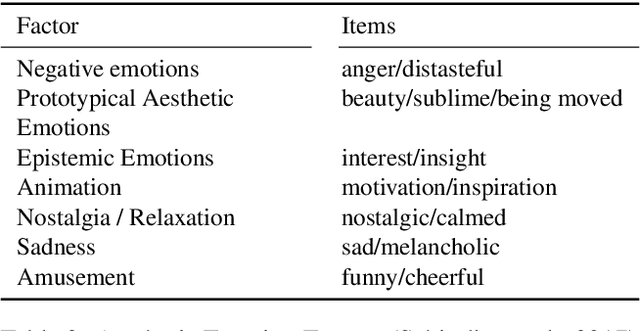
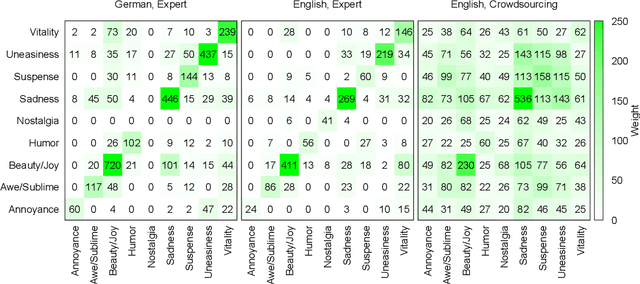
Most approaches to emotion analysis regarding social media, literature, news, and other domains focus exclusively on basic emotion categories as defined by Ekman or Plutchik. However, art (such as literature) enables engagement in a broader range of more complex and subtle emotions that have been shown to also include mixed emotional responses. We consider emotions as they are elicited in the reader, rather than what is expressed in the text or intended by the author. Thus, we conceptualize a set of aesthetic emotions that are predictive of aesthetic appreciation in the reader, and allow the annotation of multiple labels per line to capture mixed emotions within context. We evaluate this novel setting in an annotation experiment both with carefully trained experts and via crowdsourcing. Our annotation with experts leads to an acceptable agreement of kappa=.70, resulting in a consistent dataset for future large scale analysis. Finally, we conduct first emotion classification experiments based on BERT, showing that identifying aesthetic emotions is challenging in our data, with up to .52 F1-micro on the German subset. Data and resources are available at https://github.com/tnhaider/poetry-emotion
* Emotion, Aesthetic Emotions, Literature, Poetry, Annotation, Corpora, Emotion Recognition, Multi-Label
Semantic Change and Emerging Tropes In a Large Corpus of New High German Poetry
Sep 26, 2019
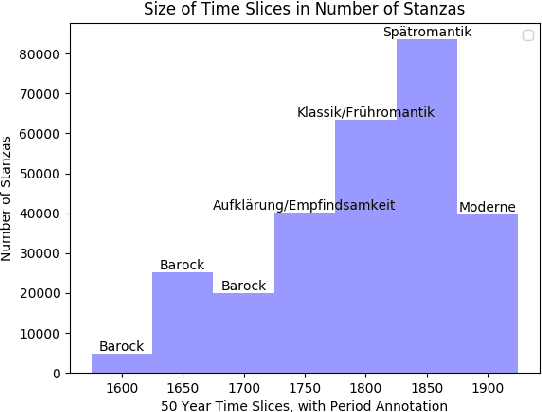


Due to its semantic succinctness and novelty of expression, poetry is a great test bed for semantic change analysis. However, so far there is a scarcity of large diachronic corpora. Here, we provide a large corpus of German poetry which consists of about 75k poems with more than 11 million tokens, with poems ranging from the 16th to early 20th century. We then track semantic change in this corpus by investigating the rise of tropes (`love is magic') over time and detecting change points of meaning, which we find to occur particularly within the German Romantic period. Additionally, through self-similarity, we reconstruct literary periods and find evidence that the law of linear semantic change also applies to poetry.
* Historical Language Change Workshop at ACL 2019, Florence