 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegular-pattern-sensitive CRFs for Distant Label Interactions
Nov 19, 2024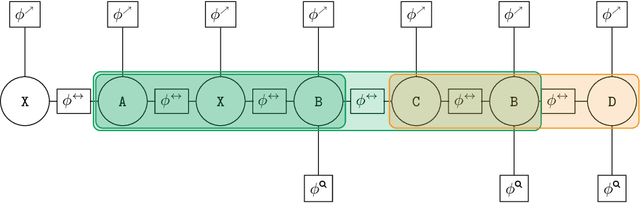

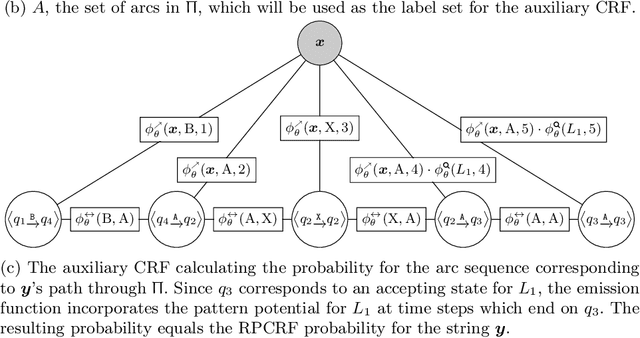

Linear-chain conditional random fields (CRFs) are a common model component for sequence labeling tasks when modeling the interactions between different labels is important. However, the Markov assumption limits linear-chain CRFs to only directly modeling interactions between adjacent labels. Weighted finite-state transducers (FSTs) are a related approach which can be made to model distant label-label interactions, but exact label inference is intractable for these models in the general case, and the task of selecting an appropriate automaton structure for the desired interaction types poses a practical challenge. In this work, we present regular-pattern-sensitive CRFs (RPCRFs), a method of enriching standard linear-chain CRFs with the ability to learn long-distance label interactions which occur in user-specified patterns. This approach allows users to write regular-expression label patterns concisely specifying which types of interactions the model should take into account, allowing the model to learn from data whether and in which contexts these patterns occur. The result can be interpreted alternatively as a CRF augmented with additional, non-local potentials, or as a finite-state transducer whose structure is defined by a set of easily-interpretable patterns. Critically, unlike the general case for FSTs (and for non-chain CRFs), exact training and inference are tractable for many pattern sets. In this work, we detail how a RPCRF can be automatically constructed from a set of user-specified patterns, and demonstrate the model's effectiveness on synthetic data, showing how different types of patterns can capture different nonlocal dependency structures in label sequences.
Distributional Analysis of Function Words
Jul 24, 2019



This paper is a first attempt at reconciling the current methods of distributional semantics with the function word emphasis of formal linguistics. We consider a multiply polysemous function word, the German reflexive pronoun "sich", and investigate in which ways natural subclasses of this word known from the theoretical and typological literature map onto recent models from distributional semantics.
Instantiation
Aug 05, 2018



In computational linguistics, a large body of work exists on distributed modeling of lexical relations, focussing largely on lexical relations such as hypernymy (scientist -- person) that hold between two categories, as expressed by common nouns. In contrast, computational linguistics has paid little attention to entities denoted by proper nouns (Marie Curie, Mumbai, ...). These have investigated in detail by the Knowledge Representation and Semantic Web communities, but generally not with regard to their linguistic properties. Our paper closes this gap by investigating and modeling the lexical relation of instantiation, which holds between an entity-denoting and a category-denoting expression (Marie Curie -- scientist or Mumbai -- city). We present a new, principled dataset for the task of instantiation detection as well as experiments and analyses on this dataset. We obtain the following results: (a), entities belonging to one category form a region in distributional space, but the embedding for the category word is typically located outside this subspace; (b) it is easy to learn to distinguish entities from categories from distributional evidence, but due to (a), instantiation proper is much harder to learn when using common nouns as representations of categories; (c) this problem can be alleviated by using category representations based on entity rather than category word embeddings.
Cross-lingual Annotation Projection for Semantic Roles
Jan 15, 2014
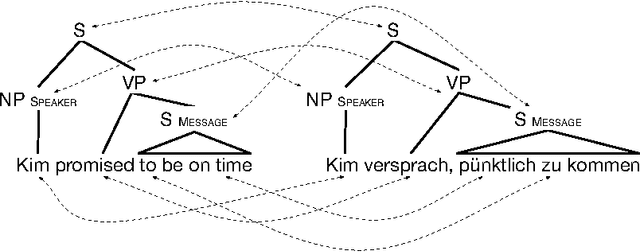


This article considers the task of automatically inducing role-semantic annotations in the FrameNet paradigm for new languages. We propose a general framework that is based on annotation projection, phrased as a graph optimization problem. It is relatively inexpensive and has the potential to reduce the human effort involved in creating role-semantic resources. Within this framework, we present projection models that exploit lexical and syntactic information. We provide an experimental evaluation on an English-German parallel corpus which demonstrates the feasibility of inducing high-precision German semantic role annotation both for manually and automatically annotated English data.