 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecovering Patient Journeys: A Corpus of Biomedical Entities and Relations on Twitter (BEAR)
Paper and Code
Apr 21, 2022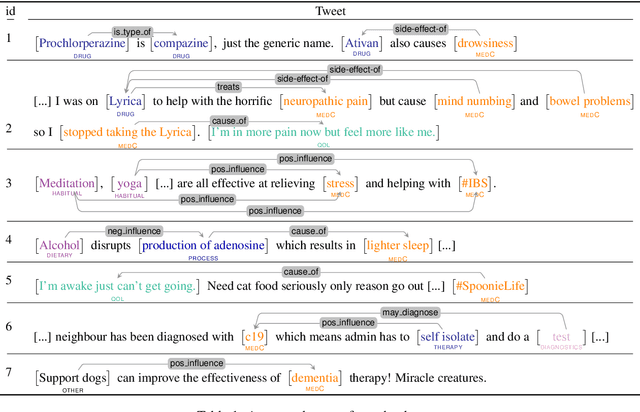
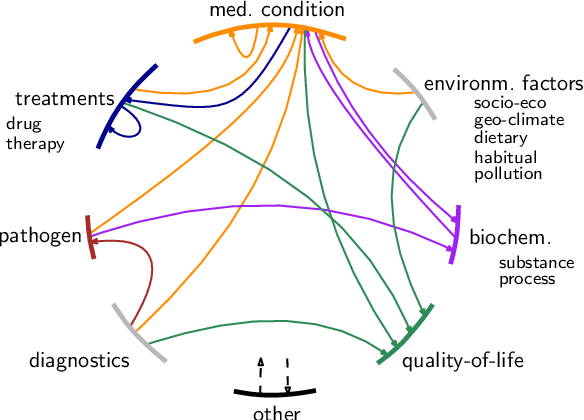
Text mining and information extraction for the medical domain has focused on scientific text generated by researchers. However, their direct access to individual patient experiences or patient-doctor interactions can be limited. Information provided on social media, e.g., by patients and their relatives, complements the knowledge in scientific text. It reflects the patient's journey and their subjective perspective on the process of developing symptoms, being diagnosed and offered a treatment, being cured or learning to live with a medical condition. The value of this type of data is therefore twofold: Firstly, it offers direct access to people's perspectives. Secondly, it might cover information that is not available elsewhere, including self-treatment or self-diagnoses. Named entity recognition and relation extraction are methods to structure information that is available in unstructured text. However, existing medical social media corpora focused on a comparably small set of entities and relations and particular domains, rather than putting the patient into the center of analyses. With this paper we contribute a corpus with a rich set of annotation layers following the motivation to uncover and model patients' journeys and experiences in more detail. We label 14 entity classes (incl. environmental factors, diagnostics, biochemical processes, patients' quality-of-life descriptions, pathogens, medical conditions, and treatments) and 20 relation classes (e.g., prevents, influences, interactions, causes) most of which have not been considered before for social media data. The publicly available dataset consists of 2,100 tweets with approx. 6,000 entity and 3,000 relation annotations. In a corpus analysis we find that over 80 % of documents contain relevant entities. Over 50 % of tweets express relations which we consider essential for uncovering patients' narratives about their journeys.