 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStress Testing Factual Consistency Metrics for Long-Document Summarization
Nov 10, 2025Evaluating the factual consistency of abstractive text summarization remains a significant challenge, particularly for long documents, where conventional metrics struggle with input length limitations and long-range dependencies. In this work, we systematically evaluate the reliability of six widely used reference-free factuality metrics, originally proposed for short-form summarization, in the long-document setting. We probe metric robustness through seven factuality-preserving perturbations applied to summaries, namely paraphrasing, simplification, synonym replacement, logically equivalent negations, vocabulary reduction, compression, and source text insertion, and further analyze their sensitivity to retrieval context and claim information density. Across three long-form benchmark datasets spanning science fiction, legal, and scientific domains, our results reveal that existing short-form metrics produce inconsistent scores for semantically equivalent summaries and exhibit declining reliability for information-dense claims whose content is semantically similar to many parts of the source document. While expanding the retrieval context improves stability in some domains, no metric consistently maintains factual alignment under long-context conditions. Finally, our results highlight concrete directions for improving factuality evaluation, including multi-span reasoning, context-aware calibration, and training on meaning-preserving variations to enhance robustness in long-form summarization. We release all code, perturbed data, and scripts required to reproduce our results at https://github.com/zainmujahid/metricEval-longSum.
Profiling News Media for Factuality and Bias Using LLMs and the Fact-Checking Methodology of Human Experts
Jun 14, 2025In an age characterized by the proliferation of mis- and disinformation online, it is critical to empower readers to understand the content they are reading. Important efforts in this direction rely on manual or automatic fact-checking, which can be challenging for emerging claims with limited information. Such scenarios can be handled by assessing the reliability and the political bias of the source of the claim, i.e., characterizing entire news outlets rather than individual claims or articles. This is an important but understudied research direction. While prior work has looked into linguistic and social contexts, we do not analyze individual articles or information in social media. Instead, we propose a novel methodology that emulates the criteria that professional fact-checkers use to assess the factuality and political bias of an entire outlet. Specifically, we design a variety of prompts based on these criteria and elicit responses from large language models (LLMs), which we aggregate to make predictions. In addition to demonstrating sizable improvements over strong baselines via extensive experiments with multiple LLMs, we provide an in-depth error analysis of the effect of media popularity and region on model performance. Further, we conduct an ablation study to highlight the key components of our dataset that contribute to these improvements. To facilitate future research, we released our dataset and code at https://github.com/mbzuai-nlp/llm-media-profiling.
LLM-as-a-qualitative-judge: automating error analysis in natural language generation
Jun 10, 2025Prompting large language models (LLMs) to evaluate generated text, known as LLM-as-a-judge, has become a standard evaluation approach in natural language generation (NLG), but is primarily used as a quantitative tool, i.e. with numerical scores as main outputs. In this work, we propose LLM-as-a-qualitative-judge, an LLM-based evaluation approach with the main output being a structured report of common issue types in the NLG system outputs. Our approach is targeted at providing developers with meaningful insights on what improvements can be done to a given NLG system and consists of two main steps, namely open-ended per-instance issue analysis and clustering of the discovered issues using an intuitive cumulative algorithm. We also introduce a strategy for evaluating the proposed approach, coupled with ~300 annotations of issues in instances from 12 NLG datasets. Our results show that LLM-as-a-qualitative-judge correctly recognizes instance-specific issues in 2/3 cases and is capable of producing error type reports resembling the reports composed by human annotators. Our code and data are publicly available at https://github.com/tunde-ajayi/llm-as-a-qualitative-judge.
Unstructured Evidence Attribution for Long Context Query Focused Summarization
Feb 20, 2025Large language models (LLMs) are capable of generating coherent summaries from very long contexts given a user query. Extracting and properly citing evidence spans could help improve the transparency and reliability of these summaries. At the same time, LLMs suffer from positional biases in terms of which information they understand and attend to, which could affect evidence citation. Whereas previous work has focused on evidence citation with predefined levels of granularity (e.g. sentence, paragraph, document, etc.), we propose the task of long-context query focused summarization with unstructured evidence citation. We show how existing systems struggle to generate and properly cite unstructured evidence from their context, and that evidence tends to be "lost-in-the-middle". To help mitigate this, we create the Summaries with Unstructured Evidence Text dataset (SUnsET), a synthetic dataset generated using a novel domain-agnostic pipeline which can be used as supervision to adapt LLMs to this task. We demonstrate across 5 LLMs of different sizes and 4 datasets with varying document types and lengths that LLMs adapted with SUnsET data generate more relevant and factually consistent evidence than their base models, extract evidence from more diverse locations in their context, and can generate more relevant and consistent summaries.
Qorgau: Evaluating LLM Safety in Kazakh-Russian Bilingual Contexts
Feb 19, 2025Large language models (LLMs) are known to have the potential to generate harmful content, posing risks to users. While significant progress has been made in developing taxonomies for LLM risks and safety evaluation prompts, most studies have focused on monolingual contexts, primarily in English. However, language- and region-specific risks in bilingual contexts are often overlooked, and core findings can diverge from those in monolingual settings. In this paper, we introduce Qorgau, a novel dataset specifically designed for safety evaluation in Kazakh and Russian, reflecting the unique bilingual context in Kazakhstan, where both Kazakh (a low-resource language) and Russian (a high-resource language) are spoken. Experiments with both multilingual and language-specific LLMs reveal notable differences in safety performance, emphasizing the need for tailored, region-specific datasets to ensure the responsible and safe deployment of LLMs in countries like Kazakhstan. Warning: this paper contains example data that may be offensive, harmful, or biased.
LLM-DetectAIve: a Tool for Fine-Grained Machine-Generated Text Detection
Aug 08, 2024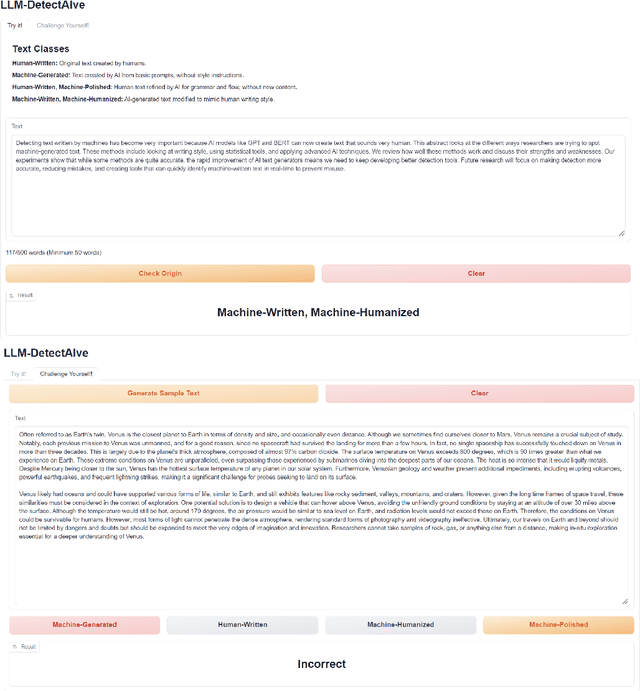
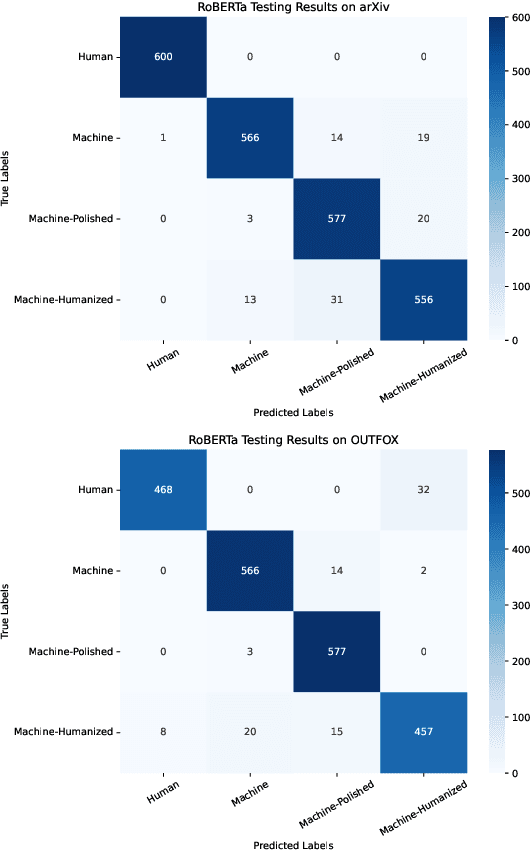
The widespread accessibility of large language models (LLMs) to the general public has significantly amplified the dissemination of machine-generated texts (MGTs). Advancements in prompt manipulation have exacerbated the difficulty in discerning the origin of a text (human-authored vs machinegenerated). This raises concerns regarding the potential misuse of MGTs, particularly within educational and academic domains. In this paper, we present $\textbf{LLM-DetectAIve}$ -- a system designed for fine-grained MGT detection. It is able to classify texts into four categories: human-written, machine-generated, machine-written machine-humanized, and human-written machine-polished. Contrary to previous MGT detectors that perform binary classification, introducing two additional categories in LLM-DetectiAIve offers insights into the varying degrees of LLM intervention during the text creation. This might be useful in some domains like education, where any LLM intervention is usually prohibited. Experiments show that LLM-DetectAIve can effectively identify the authorship of textual content, proving its usefulness in enhancing integrity in education, academia, and other domains. LLM-DetectAIve is publicly accessible at https://huggingface.co/spaces/raj-tomar001/MGT-New. The video describing our system is available at https://youtu.be/E8eT_bE7k8c.
Factcheck-GPT: End-to-End Fine-Grained Document-Level Fact-Checking and Correction of LLM Output
Nov 16, 2023



The increased use of large language models (LLMs) across a variety of real-world applications calls for mechanisms to verify the factual accuracy of their outputs. In this work, we present a holistic end-to-end solution for annotating the factuality of LLM-generated responses, which encompasses a multi-stage annotation scheme designed to yield detailed labels concerning the verifiability and factual inconsistencies found in LLM outputs. We design and build an annotation tool to speed up the labelling procedure and ease the workload of raters. It allows flexible incorporation of automatic results in any stage, e.g. automatically-retrieved evidence. We further construct an open-domain document-level factuality benchmark in three-level granularity: claim, sentence and document. Preliminary experiments show that FacTool, FactScore and Perplexity.ai are struggling to identify false claims with the best F1=0.53. Annotation tool, benchmark and code are available at https://github.com/yuxiaw/Factcheck-GPT.
Jais and Jais-chat: Arabic-Centric Foundation and Instruction-Tuned Open Generative Large Language Models
Aug 30, 2023
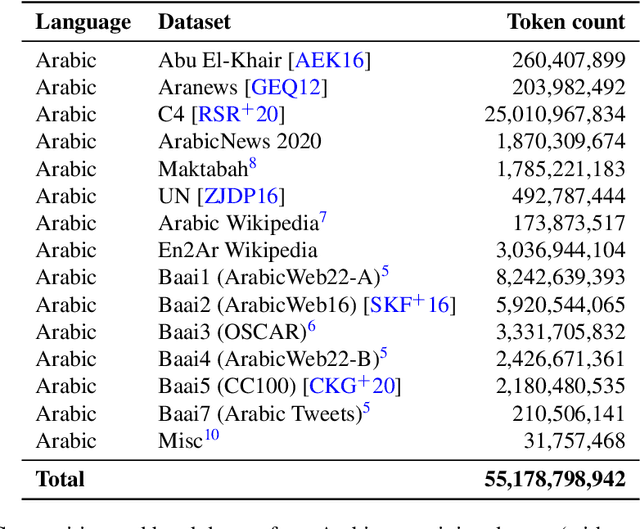
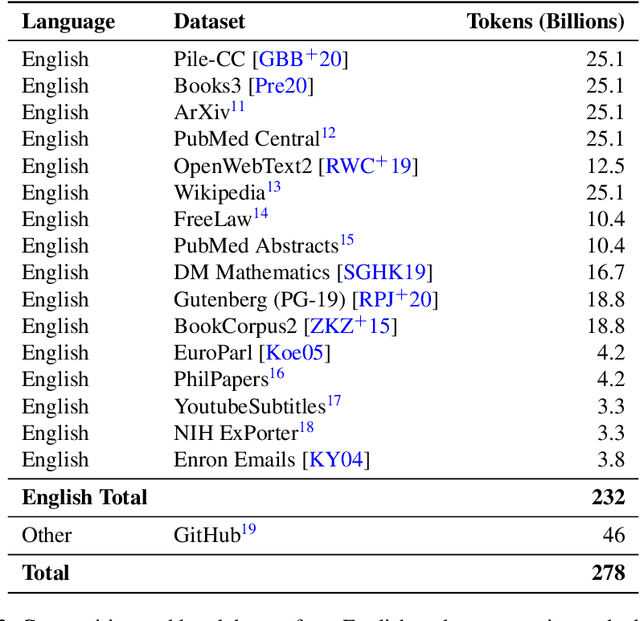
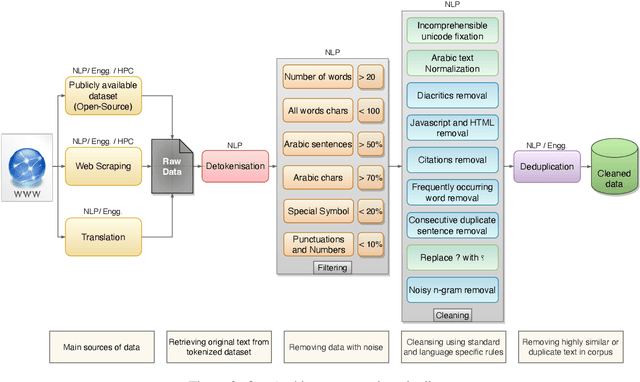
We introduce Jais and Jais-chat, new state-of-the-art Arabic-centric foundation and instruction-tuned open generative large language models (LLMs). The models are based on the GPT-3 decoder-only architecture and are pretrained on a mixture of Arabic and English texts, including source code in various programming languages. With 13 billion parameters, they demonstrate better knowledge and reasoning capabilities in Arabic than any existing open Arabic and multilingual models by a sizable margin, based on extensive evaluation. Moreover, the models are competitive in English compared to English-centric open models of similar size, despite being trained on much less English data. We provide a detailed description of the training, the tuning, the safety alignment, and the evaluation of the models. We release two open versions of the model -- the foundation Jais model, and an instruction-tuned Jais-chat variant -- with the aim of promoting research on Arabic LLMs. Available at https://huggingface.co/inception-mbzuai/jais-13b-chat