 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-as-a-qualitative-judge: automating error analysis in natural language generation
Jun 10, 2025Prompting large language models (LLMs) to evaluate generated text, known as LLM-as-a-judge, has become a standard evaluation approach in natural language generation (NLG), but is primarily used as a quantitative tool, i.e. with numerical scores as main outputs. In this work, we propose LLM-as-a-qualitative-judge, an LLM-based evaluation approach with the main output being a structured report of common issue types in the NLG system outputs. Our approach is targeted at providing developers with meaningful insights on what improvements can be done to a given NLG system and consists of two main steps, namely open-ended per-instance issue analysis and clustering of the discovered issues using an intuitive cumulative algorithm. We also introduce a strategy for evaluating the proposed approach, coupled with ~300 annotations of issues in instances from 12 NLG datasets. Our results show that LLM-as-a-qualitative-judge correctly recognizes instance-specific issues in 2/3 cases and is capable of producing error type reports resembling the reports composed by human annotators. Our code and data are publicly available at https://github.com/tunde-ajayi/llm-as-a-qualitative-judge.
AfriQA: Cross-lingual Open-Retrieval Question Answering for African Languages
May 11, 2023



African languages have far less in-language content available digitally, making it challenging for question answering systems to satisfy the information needs of users. Cross-lingual open-retrieval question answering (XOR QA) systems -- those that retrieve answer content from other languages while serving people in their native language -- offer a means of filling this gap. To this end, we create AfriQA, the first cross-lingual QA dataset with a focus on African languages. AfriQA includes 12,000+ XOR QA examples across 10 African languages. While previous datasets have focused primarily on languages where cross-lingual QA augments coverage from the target language, AfriQA focuses on languages where cross-lingual answer content is the only high-coverage source of answer content. Because of this, we argue that African languages are one of the most important and realistic use cases for XOR QA. Our experiments demonstrate the poor performance of automatic translation and multilingual retrieval methods. Overall, AfriQA proves challenging for state-of-the-art QA models. We hope that the dataset enables the development of more equitable QA technology.
MasakhaNEWS: News Topic Classification for African languages
Apr 19, 2023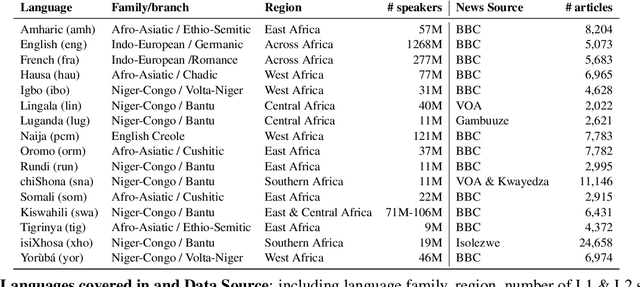
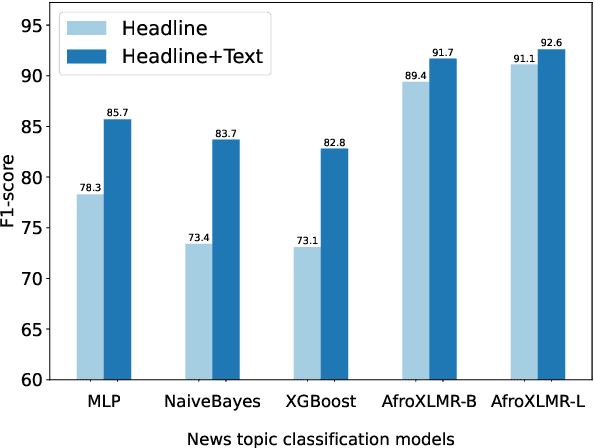
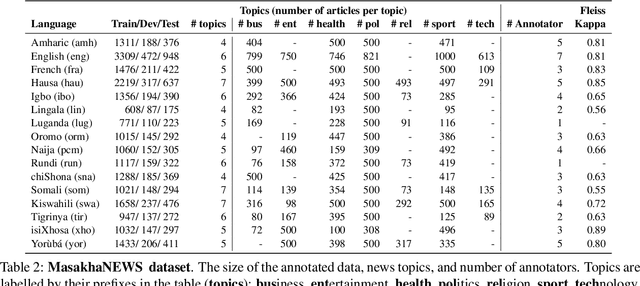
African languages are severely under-represented in NLP research due to lack of datasets covering several NLP tasks. While there are individual language specific datasets that are being expanded to different tasks, only a handful of NLP tasks (e.g. named entity recognition and machine translation) have standardized benchmark datasets covering several geographical and typologically-diverse African languages. In this paper, we develop MasakhaNEWS -- a new benchmark dataset for news topic classification covering 16 languages widely spoken in Africa. We provide an evaluation of baseline models by training classical machine learning models and fine-tuning several language models. Furthermore, we explore several alternatives to full fine-tuning of language models that are better suited for zero-shot and few-shot learning such as cross-lingual parameter-efficient fine-tuning (like MAD-X), pattern exploiting training (PET), prompting language models (like ChatGPT), and prompt-free sentence transformer fine-tuning (SetFit and Cohere Embedding API). Our evaluation in zero-shot setting shows the potential of prompting ChatGPT for news topic classification in low-resource African languages, achieving an average performance of 70 F1 points without leveraging additional supervision like MAD-X. In few-shot setting, we show that with as little as 10 examples per label, we achieved more than 90\% (i.e. 86.0 F1 points) of the performance of full supervised training (92.6 F1 points) leveraging the PET approach.
Evaluating the Robustness of Machine Reading Comprehension Models to Low Resource Entity Renaming
Apr 06, 2023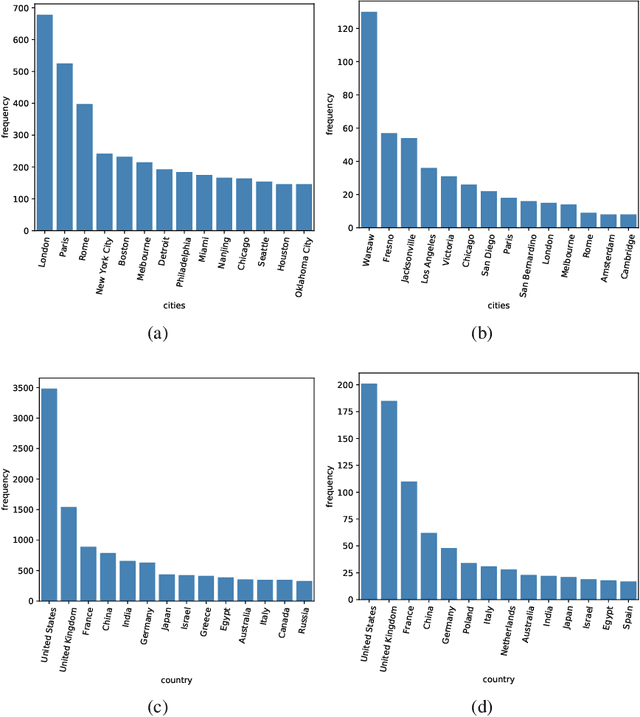
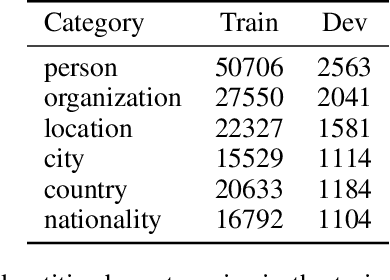


Question answering (QA) models have shown compelling results in the task of Machine Reading Comprehension (MRC). Recently these systems have proved to perform better than humans on held-out test sets of datasets e.g. SQuAD, but their robustness is not guaranteed. The QA model's brittleness is exposed when evaluated on adversarial generated examples by a performance drop. In this study, we explore the robustness of MRC models to entity renaming, with entities from low-resource regions such as Africa. We propose EntSwap, a method for test-time perturbations, to create a test set whose entities have been renamed. In particular, we rename entities of type: country, person, nationality, location, organization, and city, to create AfriSQuAD2. Using the perturbed test set, we evaluate the robustness of three popular MRC models. We find that compared to base models, large models perform well comparatively on novel entities. Furthermore, our analysis indicates that entity type person highly challenges the MRC models' performance.
A Few Thousand Translations Go a Long Way! Leveraging Pre-trained Models for African News Translation
May 04, 2022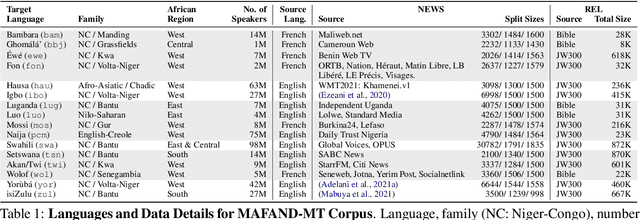
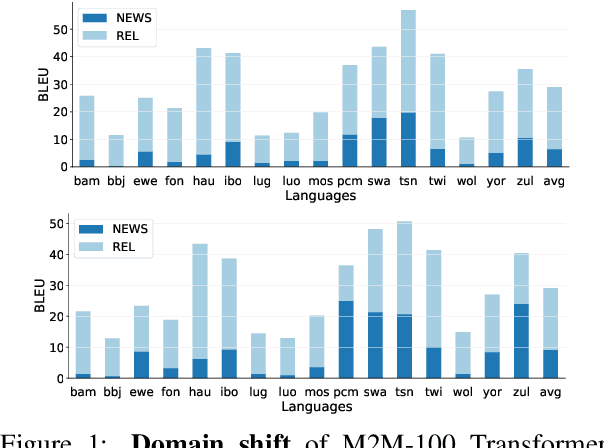

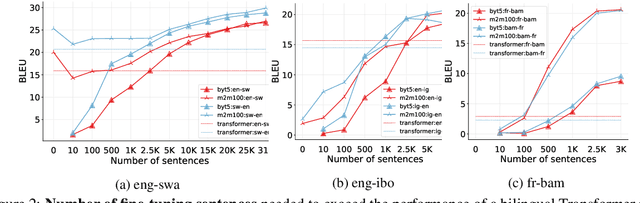
Recent advances in the pre-training of language models leverage large-scale datasets to create multilingual models. However, low-resource languages are mostly left out in these datasets. This is primarily because many widely spoken languages are not well represented on the web and therefore excluded from the large-scale crawls used to create datasets. Furthermore, downstream users of these models are restricted to the selection of languages originally chosen for pre-training. This work investigates how to optimally leverage existing pre-trained models to create low-resource translation systems for 16 African languages. We focus on two questions: 1) How can pre-trained models be used for languages not included in the initial pre-training? and 2) How can the resulting translation models effectively transfer to new domains? To answer these questions, we create a new African news corpus covering 16 languages, of which eight languages are not part of any existing evaluation dataset. We demonstrate that the most effective strategy for transferring both to additional languages and to additional domains is to fine-tune large pre-trained models on small quantities of high-quality translation data.