 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJudging the Judges: A Collection of LLM-Generated Relevance Judgements
Feb 19, 2025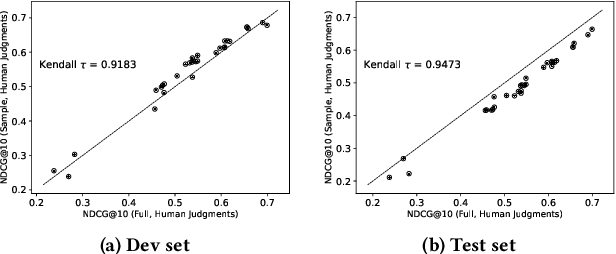
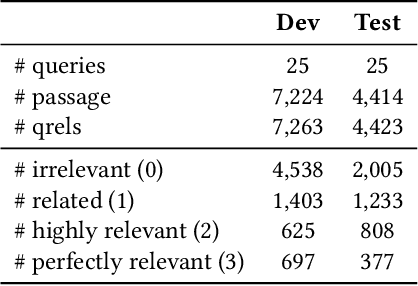
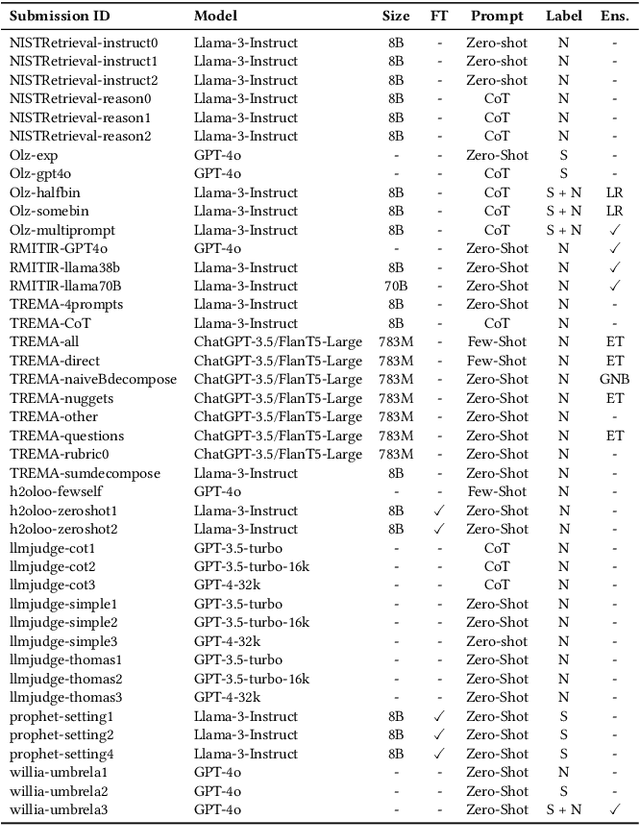
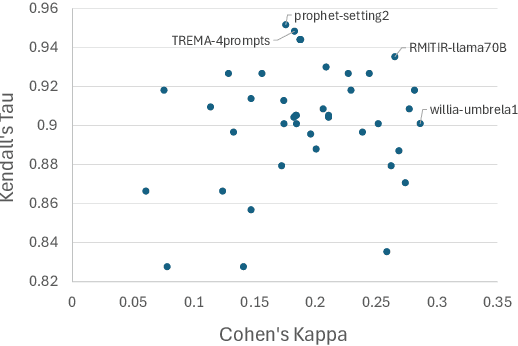
Using Large Language Models (LLMs) for relevance assessments offers promising opportunities to improve Information Retrieval (IR), Natural Language Processing (NLP), and related fields. Indeed, LLMs hold the promise of allowing IR experimenters to build evaluation collections with a fraction of the manual human labor currently required. This could help with fresh topics on which there is still limited knowledge and could mitigate the challenges of evaluating ranking systems in low-resource scenarios, where it is challenging to find human annotators. Given the fast-paced recent developments in the domain, many questions concerning LLMs as assessors are yet to be answered. Among the aspects that require further investigation, we can list the impact of various components in a relevance judgment generation pipeline, such as the prompt used or the LLM chosen. This paper benchmarks and reports on the results of a large-scale automatic relevance judgment evaluation, the LLMJudge challenge at SIGIR 2024, where different relevance assessment approaches were proposed. In detail, we release and benchmark 42 LLM-generated labels of the TREC 2023 Deep Learning track relevance judgments produced by eight international teams who participated in the challenge. Given their diverse nature, these automatically generated relevance judgments can help the community not only investigate systematic biases caused by LLMs but also explore the effectiveness of ensemble models, analyze the trade-offs between different models and human assessors, and advance methodologies for improving automated evaluation techniques. The released resource is available at the following link: https://llm4eval.github.io/LLMJudge-benchmark/
Multi-Turn Multi-Modal Question Clarification for Enhanced Conversational Understanding
Feb 17, 2025



Conversational query clarification enables users to refine their search queries through interactive dialogue, improving search effectiveness. Traditional approaches rely on text-based clarifying questions, which often fail to capture complex user preferences, particularly those involving visual attributes. While recent work has explored single-turn multi-modal clarification with images alongside text, such methods do not fully support the progressive nature of user intent refinement over multiple turns. Motivated by this, we introduce the Multi-turn Multi-modal Clarifying Questions (MMCQ) task, which combines text and visual modalities to refine user queries in a multi-turn conversation. To facilitate this task, we create a large-scale dataset named ClariMM comprising over 13k multi-turn interactions and 33k question-answer pairs containing multi-modal clarifying questions. We propose Mario, a retrieval framework that employs a two-phase ranking strategy: initial retrieval with BM25, followed by a multi-modal generative re-ranking model that integrates textual and visual information from conversational history. Our experiments show that multi-turn multi-modal clarification outperforms uni-modal and single-turn approaches, improving MRR by 12.88%. The gains are most significant in longer interactions, demonstrating the value of progressive refinement for complex queries.
AGENT-CQ: Automatic Generation and Evaluation of Clarifying Questions for Conversational Search with LLMs
Oct 25, 2024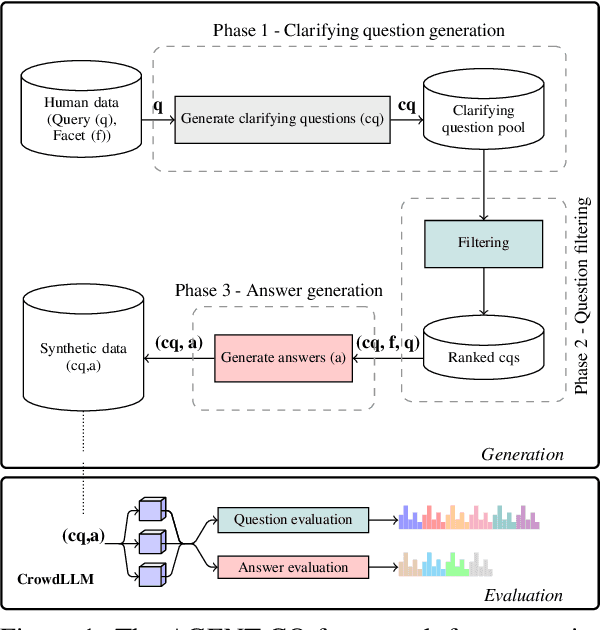



Generating diverse and effective clarifying questions is crucial for improving query understanding and retrieval performance in open-domain conversational search (CS) systems. We propose AGENT-CQ (Automatic GENeration, and evaluaTion of Clarifying Questions), an end-to-end LLM-based framework addressing the challenges of scalability and adaptability faced by existing methods that rely on manual curation or template-based approaches. AGENT-CQ consists of two stages: a generation stage employing LLM prompting strategies to generate clarifying questions, and an evaluation stage (CrowdLLM) that simulates human crowdsourcing judgments using multiple LLM instances to assess generated questions and answers based on comprehensive quality metrics. Extensive experiments on the ClariQ dataset demonstrate CrowdLLM's effectiveness in evaluating question and answer quality. Human evaluation and CrowdLLM show that the AGENT-CQ - generation stage, consistently outperforms baselines in various aspects of question and answer quality. In retrieval-based evaluation, LLM-generated questions significantly enhance retrieval effectiveness for both BM25 and cross-encoder models compared to human-generated questions.
Report on the 1st Workshop on Large Language Model for Evaluation in Information Retrieval (LLM4Eval 2024) at SIGIR 2024
Aug 09, 2024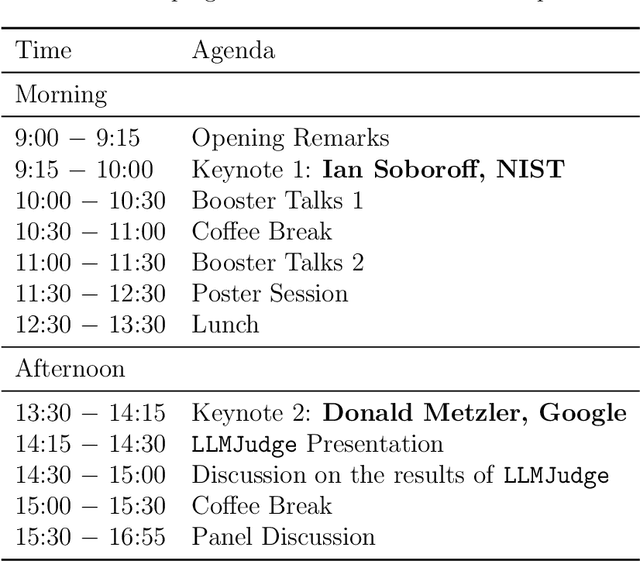
The first edition of the workshop on Large Language Model for Evaluation in Information Retrieval (LLM4Eval 2024) took place in July 2024, co-located with the ACM SIGIR Conference 2024 in the USA (SIGIR 2024). The aim was to bring information retrieval researchers together around the topic of LLMs for evaluation in information retrieval that gathered attention with the advancement of large language models and generative AI. Given the novelty of the topic, the workshop was focused around multi-sided discussions, namely panels and poster sessions of the accepted proceedings papers.
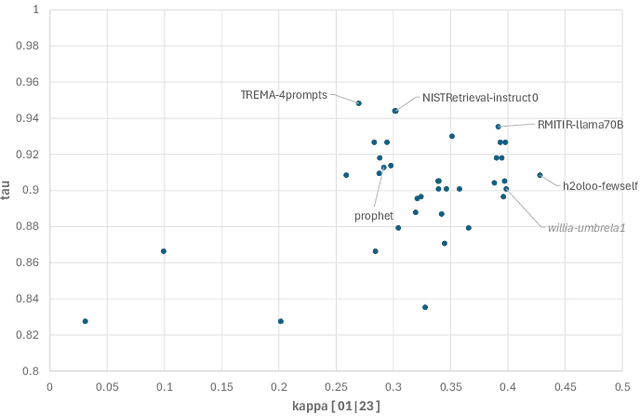
LLMJudge: LLMs for Relevance Judgments
Aug 09, 2024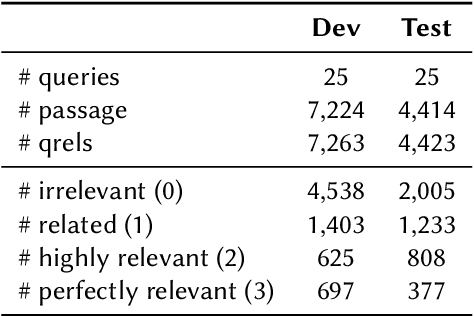
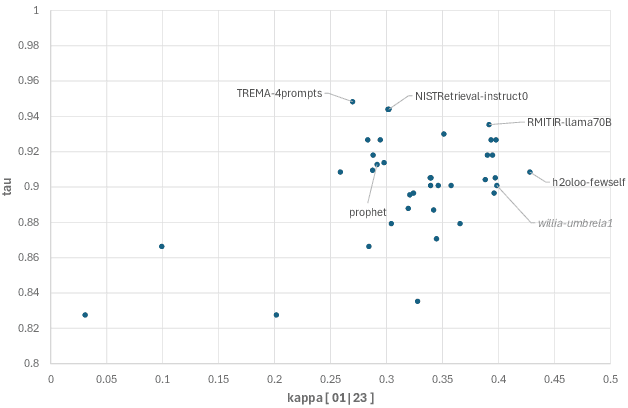
The LLMJudge challenge is organized as part of the LLM4Eval workshop at SIGIR 2024. Test collections are essential for evaluating information retrieval (IR) systems. The evaluation and tuning of a search system is largely based on relevance labels, which indicate whether a document is useful for a specific search and user. However, collecting relevance judgments on a large scale is costly and resource-intensive. Consequently, typical experiments rely on third-party labelers who may not always produce accurate annotations. The LLMJudge challenge aims to explore an alternative approach by using LLMs to generate relevance judgments. Recent studies have shown that LLMs can generate reliable relevance judgments for search systems. However, it remains unclear which LLMs can match the accuracy of human labelers, which prompts are most effective, how fine-tuned open-source LLMs compare to closed-source LLMs like GPT-4, whether there are biases in synthetically generated data, and if data leakage affects the quality of generated labels. This challenge will investigate these questions, and the collected data will be released as a package to support automatic relevance judgment research in information retrieval and search.
Rethinking the Evaluation of Dialogue Systems: Effects of User Feedback on Crowdworkers and LLMs
Apr 19, 2024



In ad-hoc retrieval, evaluation relies heavily on user actions, including implicit feedback. In a conversational setting such signals are usually unavailable due to the nature of the interactions, and, instead, the evaluation often relies on crowdsourced evaluation labels. The role of user feedback in annotators' assessment of turns in a conversational perception has been little studied. We focus on how the evaluation of task-oriented dialogue systems (TDSs), is affected by considering user feedback, explicit or implicit, as provided through the follow-up utterance of a turn being evaluated. We explore and compare two methodologies for assessing TDSs: one includes the user's follow-up utterance and one without. We use both crowdworkers and large language models (LLMs) as annotators to assess system responses across four aspects: relevance, usefulness, interestingness, and explanation quality. Our findings indicate that there is a distinct difference in ratings assigned by both annotator groups in the two setups, indicating user feedback does influence system evaluation. Workers are more susceptible to user feedback on usefulness and interestingness compared to LLMs on interestingness and relevance. User feedback leads to a more personalized assessment of usefulness by workers, aligning closely with the user's explicit feedback. Additionally, in cases of ambiguous or complex user requests, user feedback improves agreement among crowdworkers. These findings emphasize the significance of user feedback in refining system evaluations and suggest the potential for automated feedback integration in future research. We publicly release the annotated data to foster research in this area.
Context Does Matter: Implications for Crowdsourced Evaluation Labels in Task-Oriented Dialogue Systems
Apr 15, 2024



Crowdsourced labels play a crucial role in evaluating task-oriented dialogue systems (TDSs). Obtaining high-quality and consistent ground-truth labels from annotators presents challenges. When evaluating a TDS, annotators must fully comprehend the dialogue before providing judgments. Previous studies suggest using only a portion of the dialogue context in the annotation process. However, the impact of this limitation on label quality remains unexplored. This study investigates the influence of dialogue context on annotation quality, considering the truncated context for relevance and usefulness labeling. We further propose to use large language models (LLMs) to summarize the dialogue context to provide a rich and short description of the dialogue context and study the impact of doing so on the annotator's performance. Reducing context leads to more positive ratings. Conversely, providing the entire dialogue context yields higher-quality relevance ratings but introduces ambiguity in usefulness ratings. Using the first user utterance as context leads to consistent ratings, akin to those obtained using the entire dialogue, with significantly reduced annotation effort. Our findings show how task design, particularly the availability of dialogue context, affects the quality and consistency of crowdsourced evaluation labels.
Asking Multimodal Clarifying Questions in Mixed-Initiative Conversational Search
Feb 12, 2024



In mixed-initiative conversational search systems, clarifying questions are used to help users who struggle to express their intentions in a single query. These questions aim to uncover user's information needs and resolve query ambiguities. We hypothesize that in scenarios where multimodal information is pertinent, the clarification process can be improved by using non-textual information. Therefore, we propose to add images to clarifying questions and formulate the novel task of asking multimodal clarifying questions in open-domain, mixed-initiative conversational search systems. To facilitate research into this task, we collect a dataset named Melon that contains over 4k multimodal clarifying questions, enriched with over 14k images. We also propose a multimodal query clarification model named Marto and adopt a prompt-based, generative fine-tuning strategy to perform the training of different stages with different prompts. Several analyses are conducted to understand the importance of multimodal contents during the query clarification phase. Experimental results indicate that the addition of images leads to significant improvements of up to 90% in retrieval performance when selecting the relevant images. Extensive analyses are also performed to show the superiority of Marto compared with discriminative baselines in terms of effectiveness and efficiency.
AfriMTE and AfriCOMET: Empowering COMET to Embrace Under-resourced African Languages
Nov 16, 2023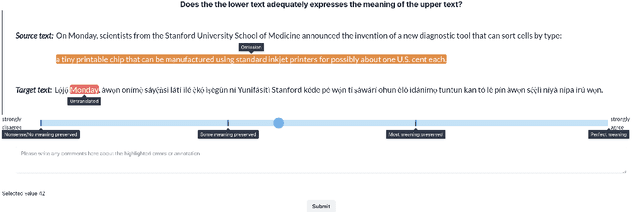
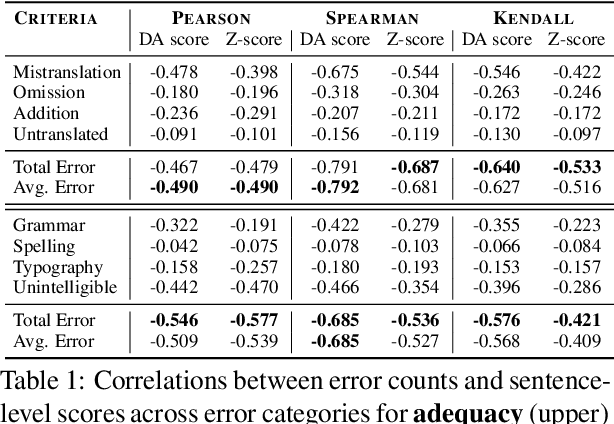
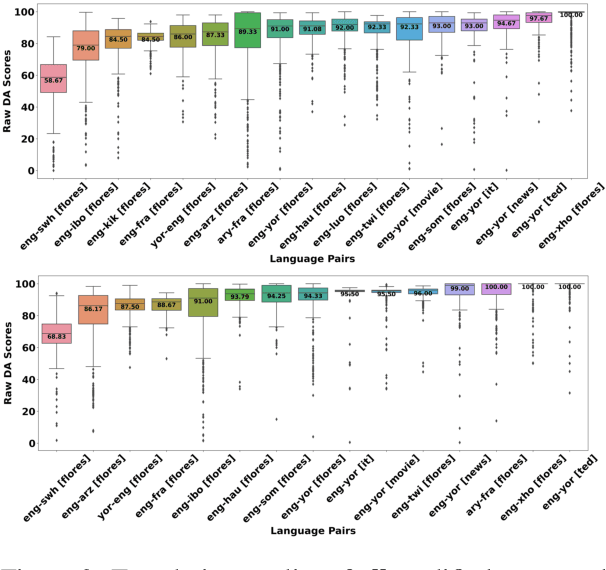
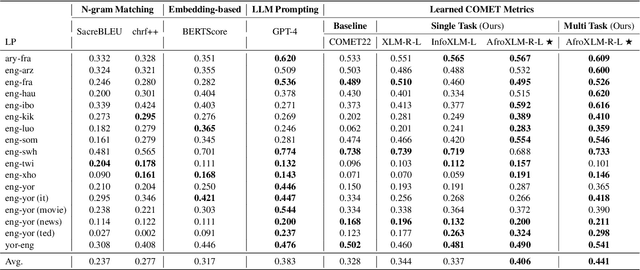
Despite the progress we have recorded in scaling multilingual machine translation (MT) models and evaluation data to several under-resourced African languages, it is difficult to measure accurately the progress we have made on these languages because evaluation is often performed on n-gram matching metrics like BLEU that often have worse correlation with human judgments. Embedding-based metrics such as COMET correlate better; however, lack of evaluation data with human ratings for under-resourced languages, complexity of annotation guidelines like Multidimensional Quality Metrics (MQM), and limited language coverage of multilingual encoders have hampered their applicability to African languages. In this paper, we address these challenges by creating high-quality human evaluation data with a simplified MQM guideline for error-span annotation and direct assessment (DA) scoring for 13 typologically diverse African languages. Furthermore, we develop AfriCOMET, a COMET evaluation metric for African languages by leveraging DA training data from high-resource languages and African-centric multilingual encoder (AfroXLM-Roberta) to create the state-of-the-art evaluation metric for African languages MT with respect to Spearman-rank correlation with human judgments (+0.406).
AfriQA: Cross-lingual Open-Retrieval Question Answering for African Languages
May 11, 2023



African languages have far less in-language content available digitally, making it challenging for question answering systems to satisfy the information needs of users. Cross-lingual open-retrieval question answering (XOR QA) systems -- those that retrieve answer content from other languages while serving people in their native language -- offer a means of filling this gap. To this end, we create AfriQA, the first cross-lingual QA dataset with a focus on African languages. AfriQA includes 12,000+ XOR QA examples across 10 African languages. While previous datasets have focused primarily on languages where cross-lingual QA augments coverage from the target language, AfriQA focuses on languages where cross-lingual answer content is the only high-coverage source of answer content. Because of this, we argue that African languages are one of the most important and realistic use cases for XOR QA. Our experiments demonstrate the poor performance of automatic translation and multilingual retrieval methods. Overall, AfriQA proves challenging for state-of-the-art QA models. We hope that the dataset enables the development of more equitable QA technology.