 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLlama-3-Nanda-10B-Chat: An Open Generative Large Language Model for Hindi
Apr 08, 2025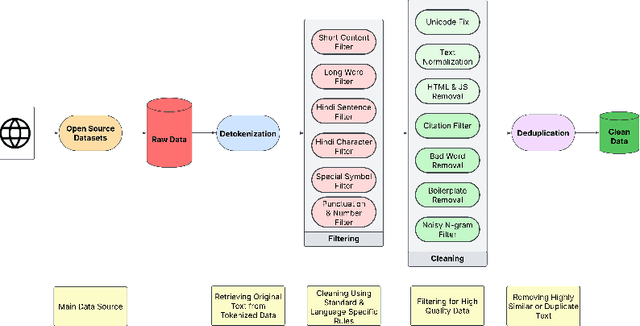

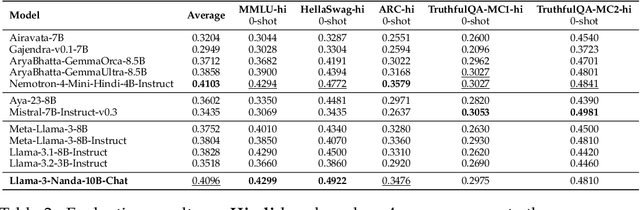

Developing high-quality large language models (LLMs) for moderately resourced languages presents unique challenges in data availability, model adaptation, and evaluation. We introduce Llama-3-Nanda-10B-Chat, or Nanda for short, a state-of-the-art Hindi-centric instruction-tuned generative LLM, designed to push the boundaries of open-source Hindi language models. Built upon Llama-3-8B, Nanda incorporates continuous pre-training with expanded transformer blocks, leveraging the Llama Pro methodology. A key challenge was the limited availability of high-quality Hindi text data; we addressed this through rigorous data curation, augmentation, and strategic bilingual training, balancing Hindi and English corpora to optimize cross-linguistic knowledge transfer. With 10 billion parameters, Nanda stands among the top-performing open-source Hindi and multilingual models of similar scale, demonstrating significant advantages over many existing models. We provide an in-depth discussion of training strategies, fine-tuning techniques, safety alignment, and evaluation metrics, demonstrating how these approaches enabled Nanda to achieve state-of-the-art results. By open-sourcing Nanda, we aim to advance research in Hindi LLMs and support a wide range of real-world applications across academia, industry, and public services.
Bilingual Adaptation of Monolingual Foundation Models
Jul 13, 2024
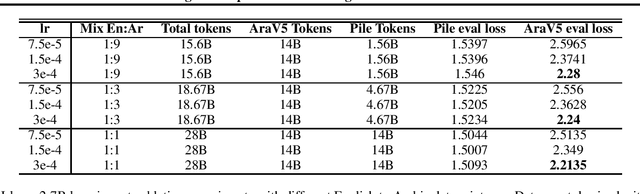


We present an efficient method for adapting a monolingual Large Language Model (LLM) to another language, addressing challenges of catastrophic forgetting and tokenizer limitations. We focus this study on adapting Llama 2 to Arabic. Our two-stage approach begins with expanding the vocabulary and training only the embeddings matrix, followed by full model continual pretraining on a bilingual corpus. By continually pretraining on a mix of Arabic and English corpora, the model retains its proficiency in English while acquiring capabilities in Arabic. Our approach results in significant improvements in Arabic and slight enhancements in English, demonstrating cost-effective cross-lingual transfer. We also perform extensive ablations on embedding initialization techniques, data mix ratios, and learning rates and release a detailed training recipe.
Jais and Jais-chat: Arabic-Centric Foundation and Instruction-Tuned Open Generative Large Language Models
Aug 30, 2023
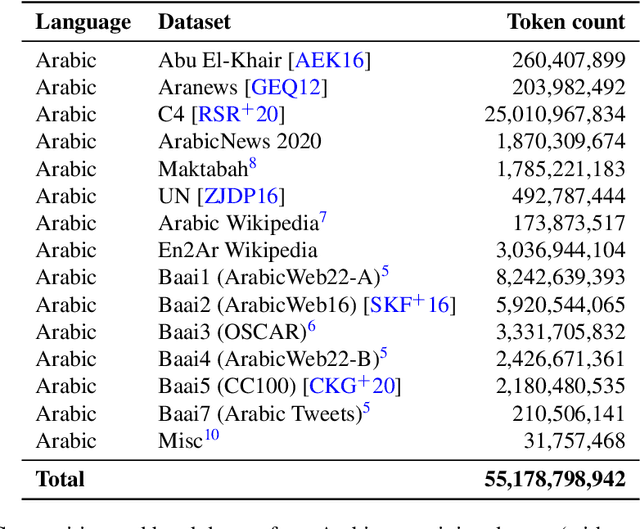
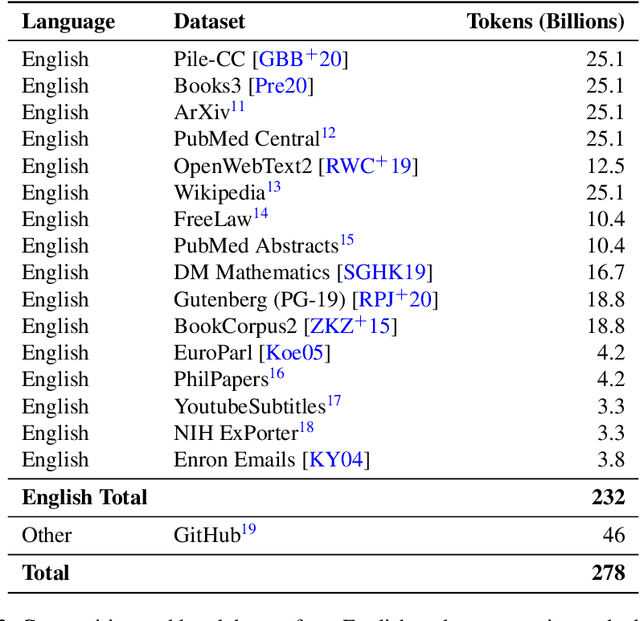
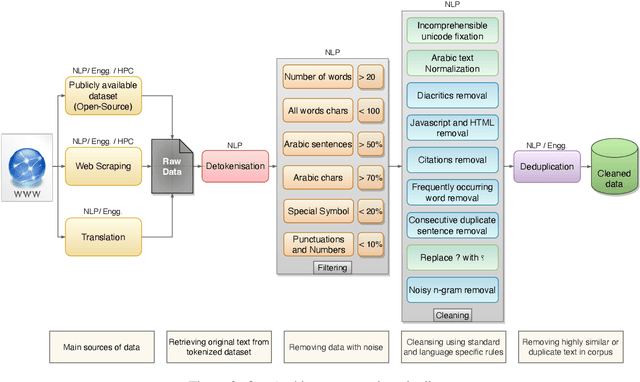
We introduce Jais and Jais-chat, new state-of-the-art Arabic-centric foundation and instruction-tuned open generative large language models (LLMs). The models are based on the GPT-3 decoder-only architecture and are pretrained on a mixture of Arabic and English texts, including source code in various programming languages. With 13 billion parameters, they demonstrate better knowledge and reasoning capabilities in Arabic than any existing open Arabic and multilingual models by a sizable margin, based on extensive evaluation. Moreover, the models are competitive in English compared to English-centric open models of similar size, despite being trained on much less English data. We provide a detailed description of the training, the tuning, the safety alignment, and the evaluation of the models. We release two open versions of the model -- the foundation Jais model, and an instruction-tuned Jais-chat variant -- with the aim of promoting research on Arabic LLMs. Available at https://huggingface.co/inception-mbzuai/jais-13b-chat
Probing for Bridging Inference in Transformer Language Models
Apr 19, 2021



We probe pre-trained transformer language models for bridging inference. We first investigate individual attention heads in BERT and observe that attention heads at higher layers prominently focus on bridging relations in-comparison with the lower and middle layers, also, few specific attention heads concentrate consistently on bridging. More importantly, we consider language models as a whole in our second approach where bridging anaphora resolution is formulated as a masked token prediction task (Of-Cloze test). Our formulation produces optimistic results without any fine-tuning, which indicates that pre-trained language models substantially capture bridging inference. Our further investigation shows that the distance between anaphor-antecedent and the context provided to language models play an important role in the inference.