 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoE-Inference-Bench: Performance Evaluation of Mixture of Expert Large Language and Vision Models
Aug 24, 2025Mixture of Experts (MoE) models have enabled the scaling of Large Language Models (LLMs) and Vision Language Models (VLMs) by achieving massive parameter counts while maintaining computational efficiency. However, MoEs introduce several inference-time challenges, including load imbalance across experts and the additional routing computational overhead. To address these challenges and fully harness the benefits of MoE, a systematic evaluation of hardware acceleration techniques is essential. We present MoE-Inference-Bench, a comprehensive study to evaluate MoE performance across diverse scenarios. We analyze the impact of batch size, sequence length, and critical MoE hyperparameters such as FFN dimensions and number of experts on throughput. We evaluate several optimization techniques on Nvidia H100 GPUs, including pruning, Fused MoE operations, speculative decoding, quantization, and various parallelization strategies. Our evaluation includes MoEs from the Mixtral, DeepSeek, OLMoE and Qwen families. The results reveal performance differences across configurations and provide insights for the efficient deployment of MoEs.
Llama-3-Nanda-10B-Chat: An Open Generative Large Language Model for Hindi
Apr 08, 2025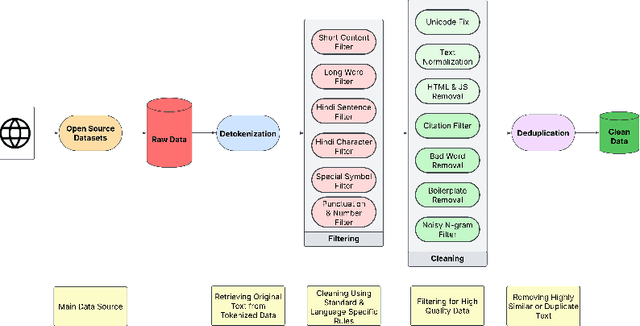

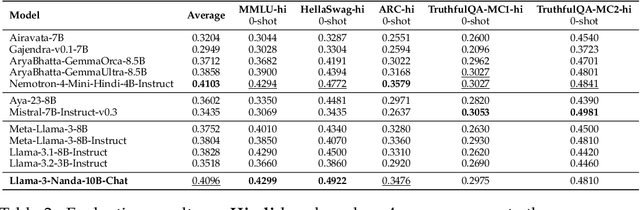

Developing high-quality large language models (LLMs) for moderately resourced languages presents unique challenges in data availability, model adaptation, and evaluation. We introduce Llama-3-Nanda-10B-Chat, or Nanda for short, a state-of-the-art Hindi-centric instruction-tuned generative LLM, designed to push the boundaries of open-source Hindi language models. Built upon Llama-3-8B, Nanda incorporates continuous pre-training with expanded transformer blocks, leveraging the Llama Pro methodology. A key challenge was the limited availability of high-quality Hindi text data; we addressed this through rigorous data curation, augmentation, and strategic bilingual training, balancing Hindi and English corpora to optimize cross-linguistic knowledge transfer. With 10 billion parameters, Nanda stands among the top-performing open-source Hindi and multilingual models of similar scale, demonstrating significant advantages over many existing models. We provide an in-depth discussion of training strategies, fine-tuning techniques, safety alignment, and evaluation metrics, demonstrating how these approaches enabled Nanda to achieve state-of-the-art results. By open-sourcing Nanda, we aim to advance research in Hindi LLMs and support a wide range of real-world applications across academia, industry, and public services.
Prot42: a Novel Family of Protein Language Models for Target-aware Protein Binder Generation
Apr 06, 2025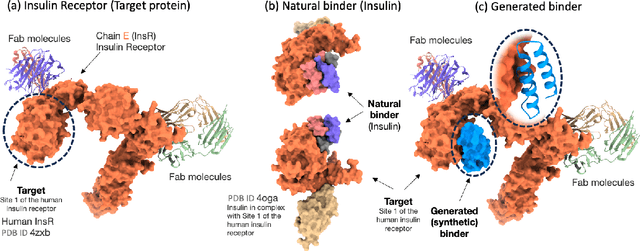
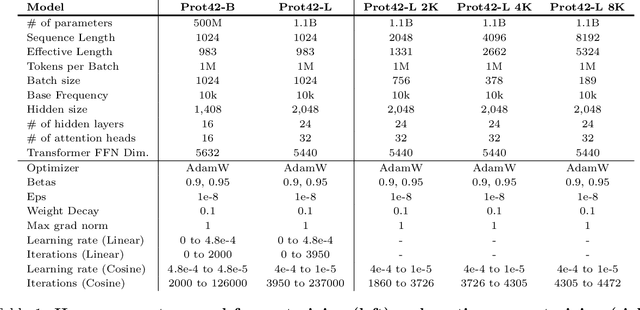

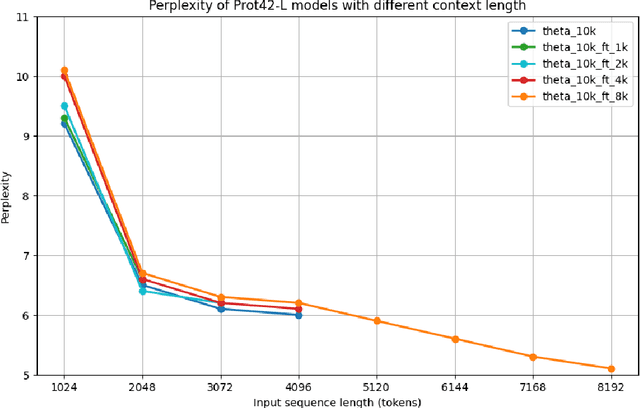
Unlocking the next generation of biotechnology and therapeutic innovation demands overcoming the inherent complexity and resource-intensity of conventional protein engineering methods. Recent GenAI-powered computational techniques often rely on the availability of the target protein's 3D structures and specific binding sites to generate high-affinity binders, constraints exhibited by models such as AlphaProteo and RFdiffusion. In this work, we explore the use of Protein Language Models (pLMs) for high-affinity binder generation. We introduce Prot42, a novel family of Protein Language Models (pLMs) pretrained on vast amounts of unlabeled protein sequences. By capturing deep evolutionary, structural, and functional insights through an advanced auto-regressive, decoder-only architecture inspired by breakthroughs in natural language processing, Prot42 dramatically expands the capabilities of computational protein design based on language only. Remarkably, our models handle sequences up to 8,192 amino acids, significantly surpassing standard limitations and enabling precise modeling of large proteins and complex multi-domain sequences. Demonstrating powerful practical applications, Prot42 excels in generating high-affinity protein binders and sequence-specific DNA-binding proteins. Our innovative models are publicly available, offering the scientific community an efficient and precise computational toolkit for rapid protein engineering.
Gene42: Long-Range Genomic Foundation Model With Dense Attention
Mar 20, 2025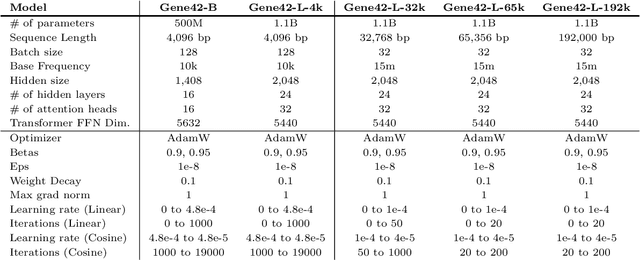
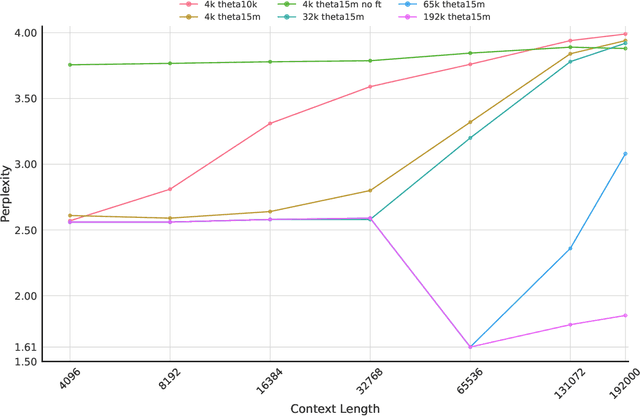
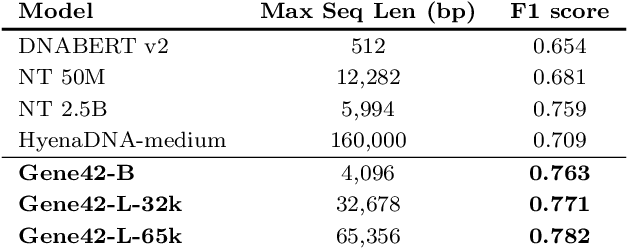
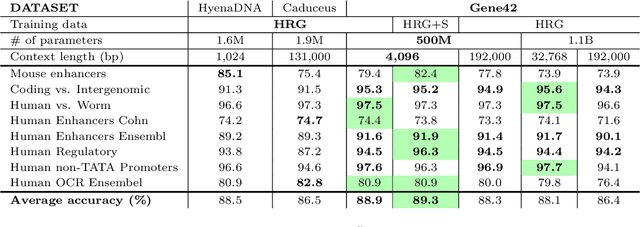
We introduce Gene42, a novel family of Genomic Foundation Models (GFMs) designed to manage context lengths of up to 192,000 base pairs (bp) at a single-nucleotide resolution. Gene42 models utilize a decoder-only (LLaMA-style) architecture with a dense self-attention mechanism. Initially trained on fixed-length sequences of 4,096 bp, our models underwent continuous pretraining to extend the context length to 192,000 bp. This iterative extension allowed for the comprehensive processing of large-scale genomic data and the capture of intricate patterns and dependencies within the human genome. Gene42 is the first dense attention model capable of handling such extensive long context lengths in genomics, challenging state-space models that often rely on convolutional operators among other mechanisms. Our pretrained models exhibit notably low perplexity values and high reconstruction accuracy, highlighting their strong ability to model genomic data. Extensive experiments on various genomic benchmarks have demonstrated state-of-the-art performance across multiple tasks, including biotype classification, regulatory region identification, chromatin profiling prediction, variant pathogenicity prediction, and species classification. The models are publicly available at huggingface.co/inceptionai.
Chem42: a Family of chemical Language Models for Target-aware Ligand Generation
Mar 20, 2025Revolutionizing drug discovery demands more than just understanding molecular interactions - it requires generative models that can design novel ligands tailored to specific biological targets. While chemical Language Models (cLMs) have made strides in learning molecular properties, most fail to incorporate target-specific insights, restricting their ability to drive de-novo ligand generation. Chem42, a cutting-edge family of generative chemical Language Models, is designed to bridge this gap. By integrating atomic-level interactions with multimodal inputs from Prot42, a complementary protein Language Model, Chem42 achieves a sophisticated cross-modal representation of molecular structures, interactions, and binding patterns. This innovative framework enables the creation of structurally valid, synthetically accessible ligands with enhanced target specificity. Evaluations across diverse protein targets confirm that Chem42 surpasses existing approaches in chemical validity, target-aware design, and predicted binding affinity. By reducing the search space of viable drug candidates, Chem42 could accelerate the drug discovery pipeline, offering a powerful generative AI tool for precision medicine. Our Chem42 models set a new benchmark in molecule property prediction, conditional molecule generation, and target-aware ligand design. The models are publicly available at huggingface.co/inceptionai.
Llama-3.1-Sherkala-8B-Chat: An Open Large Language Model for Kazakh
Mar 03, 2025Llama-3.1-Sherkala-8B-Chat, or Sherkala-Chat (8B) for short, is a state-of-the-art instruction-tuned open generative large language model (LLM) designed for Kazakh. Sherkala-Chat (8B) aims to enhance the inclusivity of LLM advancements for Kazakh speakers. Adapted from the LLaMA-3.1-8B model, Sherkala-Chat (8B) is trained on 45.3B tokens across Kazakh, English, Russian, and Turkish. With 8 billion parameters, it demonstrates strong knowledge and reasoning abilities in Kazakh, significantly outperforming existing open Kazakh and multilingual models of similar scale while achieving competitive performance in English. We release Sherkala-Chat (8B) as an open-weight instruction-tuned model and provide a detailed overview of its training, fine-tuning, safety alignment, and evaluation, aiming to advance research and support diverse real-world applications.
Crystal: Illuminating LLM Abilities on Language and Code
Nov 06, 2024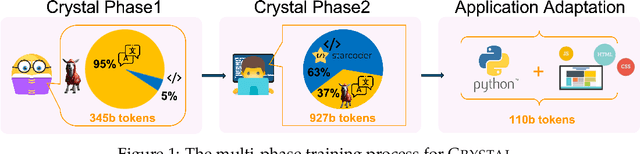
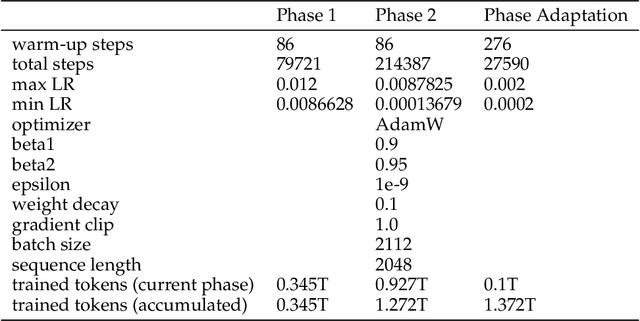
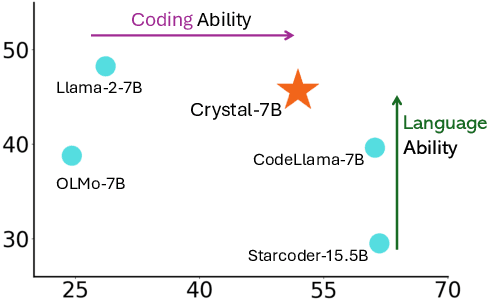
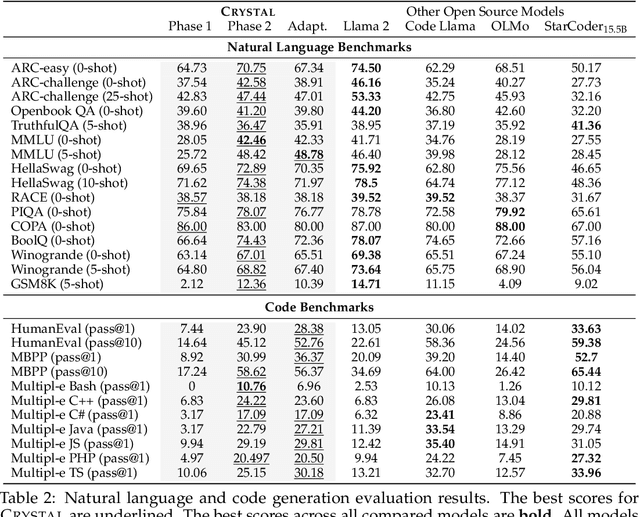
Large Language Models (LLMs) specializing in code generation (which are also often referred to as code LLMs), e.g., StarCoder and Code Llama, play increasingly critical roles in various software development scenarios. It is also crucial for code LLMs to possess both code generation and natural language abilities for many specific applications, such as code snippet retrieval using natural language or code explanations. The intricate interaction between acquiring language and coding skills complicates the development of strong code LLMs. Furthermore, there is a lack of thorough prior studies on the LLM pretraining strategy that mixes code and natural language. In this work, we propose a pretraining strategy to enhance the integration of natural language and coding capabilities within a single LLM. Specifically, it includes two phases of training with appropriately adjusted code/language ratios. The resulting model, Crystal, demonstrates remarkable capabilities in both domains. Specifically, it has natural language and coding performance comparable to that of Llama 2 and Code Llama, respectively. Crystal exhibits better data efficiency, using 1.4 trillion tokens compared to the more than 2 trillion tokens used by Llama 2 and Code Llama. We verify our pretraining strategy by analyzing the training process and observe consistent improvements in most benchmarks. We also adopted a typical application adaptation phase with a code-centric data mixture, only to find that it did not lead to enhanced performance or training efficiency, underlining the importance of a carefully designed data recipe. To foster research within the community, we commit to open-sourcing every detail of the pretraining, including our training datasets, code, loggings and 136 checkpoints throughout the training.
Bilingual Adaptation of Monolingual Foundation Models
Jul 13, 2024
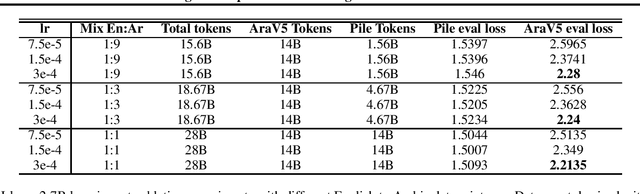


We present an efficient method for adapting a monolingual Large Language Model (LLM) to another language, addressing challenges of catastrophic forgetting and tokenizer limitations. We focus this study on adapting Llama 2 to Arabic. Our two-stage approach begins with expanding the vocabulary and training only the embeddings matrix, followed by full model continual pretraining on a bilingual corpus. By continually pretraining on a mix of Arabic and English corpora, the model retains its proficiency in English while acquiring capabilities in Arabic. Our approach results in significant improvements in Arabic and slight enhancements in English, demonstrating cost-effective cross-lingual transfer. We also perform extensive ablations on embedding initialization techniques, data mix ratios, and learning rates and release a detailed training recipe.
Med42 -- Evaluating Fine-Tuning Strategies for Medical LLMs: Full-Parameter vs. Parameter-Efficient Approaches
Apr 23, 2024



This study presents a comprehensive analysis and comparison of two predominant fine-tuning methodologies - full-parameter fine-tuning and parameter-efficient tuning - within the context of medical Large Language Models (LLMs). We developed and refined a series of LLMs, based on the Llama-2 architecture, specifically designed to enhance medical knowledge retrieval, reasoning, and question-answering capabilities. Our experiments systematically evaluate the effectiveness of these tuning strategies across various well-known medical benchmarks. Notably, our medical LLM Med42 showed an accuracy level of 72% on the US Medical Licensing Examination (USMLE) datasets, setting a new standard in performance for openly available medical LLMs. Through this comparative analysis, we aim to identify the most effective and efficient method for fine-tuning LLMs in the medical domain, thereby contributing significantly to the advancement of AI-driven healthcare applications.
BTLM-3B-8K: 7B Parameter Performance in a 3B Parameter Model
Sep 20, 2023



We introduce the Bittensor Language Model, called "BTLM-3B-8K", a new state-of-the-art 3 billion parameter open-source language model. BTLM-3B-8K was trained on 627B tokens from the SlimPajama dataset with a mixture of 2,048 and 8,192 context lengths. BTLM-3B-8K outperforms all existing 3B parameter models by 2-5.5% across downstream tasks. BTLM-3B-8K is even competitive with some 7B parameter models. Additionally, BTLM-3B-8K provides excellent long context performance, outperforming MPT-7B-8K and XGen-7B-8K on tasks up to 8,192 context length. We trained the model on a cleaned and deduplicated SlimPajama dataset; aggressively tuned the \textmu P hyperparameters and schedule; used ALiBi position embeddings; and adopted the SwiGLU nonlinearity. On Hugging Face, the most popular models have 7B parameters, indicating that users prefer the quality-size ratio of 7B models. Compacting the 7B parameter model to one with 3B parameters, with little performance impact, is an important milestone. BTLM-3B-8K needs only 3GB of memory with 4-bit precision and takes 2.5x less inference compute than 7B models, helping to open up access to a powerful language model on mobile and edge devices. BTLM-3B-8K is available under an Apache 2.0 license on Hugging Face: https://huggingface.co/cerebras/btlm-3b-8k-base.