 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProt42: a Novel Family of Protein Language Models for Target-aware Protein Binder Generation
Apr 06, 2025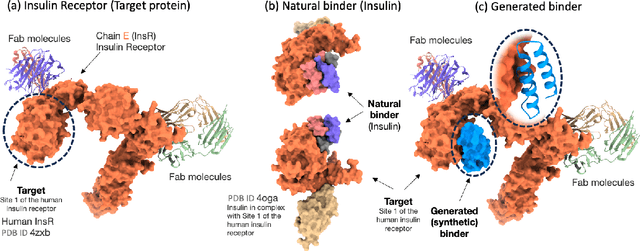
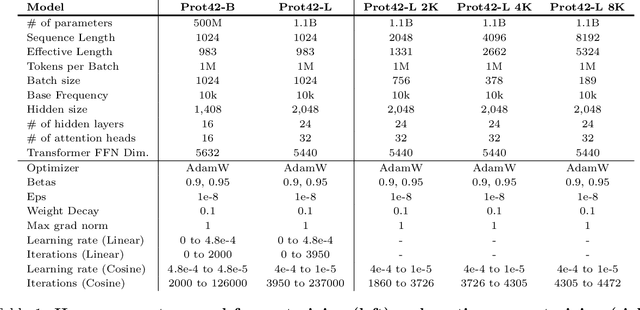

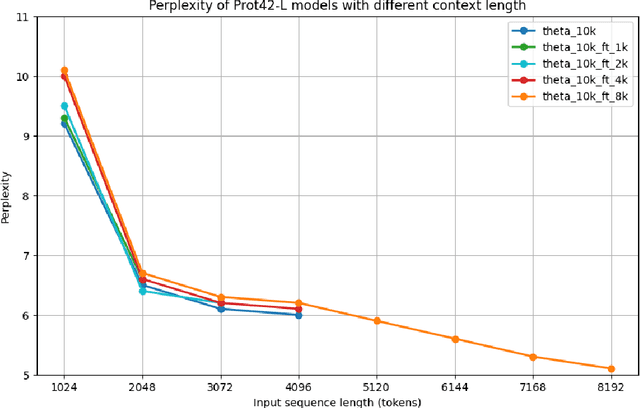
Unlocking the next generation of biotechnology and therapeutic innovation demands overcoming the inherent complexity and resource-intensity of conventional protein engineering methods. Recent GenAI-powered computational techniques often rely on the availability of the target protein's 3D structures and specific binding sites to generate high-affinity binders, constraints exhibited by models such as AlphaProteo and RFdiffusion. In this work, we explore the use of Protein Language Models (pLMs) for high-affinity binder generation. We introduce Prot42, a novel family of Protein Language Models (pLMs) pretrained on vast amounts of unlabeled protein sequences. By capturing deep evolutionary, structural, and functional insights through an advanced auto-regressive, decoder-only architecture inspired by breakthroughs in natural language processing, Prot42 dramatically expands the capabilities of computational protein design based on language only. Remarkably, our models handle sequences up to 8,192 amino acids, significantly surpassing standard limitations and enabling precise modeling of large proteins and complex multi-domain sequences. Demonstrating powerful practical applications, Prot42 excels in generating high-affinity protein binders and sequence-specific DNA-binding proteins. Our innovative models are publicly available, offering the scientific community an efficient and precise computational toolkit for rapid protein engineering.
Gene42: Long-Range Genomic Foundation Model With Dense Attention
Mar 20, 2025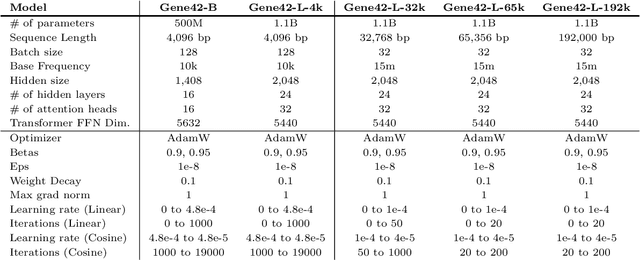
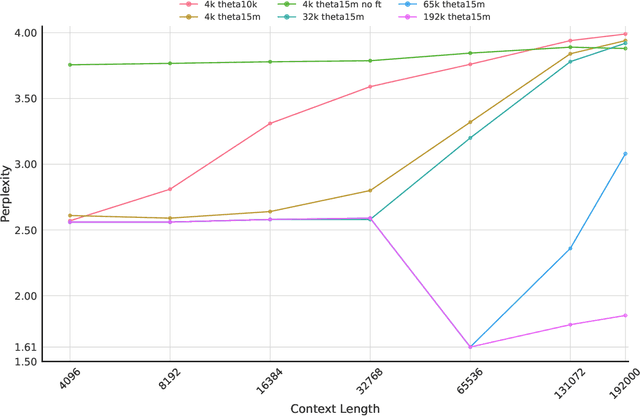
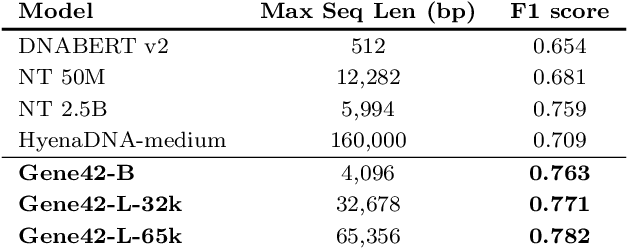
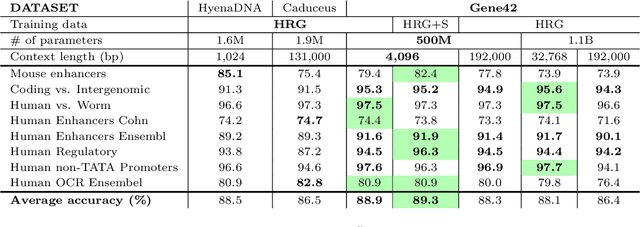
We introduce Gene42, a novel family of Genomic Foundation Models (GFMs) designed to manage context lengths of up to 192,000 base pairs (bp) at a single-nucleotide resolution. Gene42 models utilize a decoder-only (LLaMA-style) architecture with a dense self-attention mechanism. Initially trained on fixed-length sequences of 4,096 bp, our models underwent continuous pretraining to extend the context length to 192,000 bp. This iterative extension allowed for the comprehensive processing of large-scale genomic data and the capture of intricate patterns and dependencies within the human genome. Gene42 is the first dense attention model capable of handling such extensive long context lengths in genomics, challenging state-space models that often rely on convolutional operators among other mechanisms. Our pretrained models exhibit notably low perplexity values and high reconstruction accuracy, highlighting their strong ability to model genomic data. Extensive experiments on various genomic benchmarks have demonstrated state-of-the-art performance across multiple tasks, including biotype classification, regulatory region identification, chromatin profiling prediction, variant pathogenicity prediction, and species classification. The models are publicly available at huggingface.co/inceptionai.
Chem42: a Family of chemical Language Models for Target-aware Ligand Generation
Mar 20, 2025Revolutionizing drug discovery demands more than just understanding molecular interactions - it requires generative models that can design novel ligands tailored to specific biological targets. While chemical Language Models (cLMs) have made strides in learning molecular properties, most fail to incorporate target-specific insights, restricting their ability to drive de-novo ligand generation. Chem42, a cutting-edge family of generative chemical Language Models, is designed to bridge this gap. By integrating atomic-level interactions with multimodal inputs from Prot42, a complementary protein Language Model, Chem42 achieves a sophisticated cross-modal representation of molecular structures, interactions, and binding patterns. This innovative framework enables the creation of structurally valid, synthetically accessible ligands with enhanced target specificity. Evaluations across diverse protein targets confirm that Chem42 surpasses existing approaches in chemical validity, target-aware design, and predicted binding affinity. By reducing the search space of viable drug candidates, Chem42 could accelerate the drug discovery pipeline, offering a powerful generative AI tool for precision medicine. Our Chem42 models set a new benchmark in molecule property prediction, conditional molecule generation, and target-aware ligand design. The models are publicly available at huggingface.co/inceptionai.
Spoken Word2Vec: A Perspective And Some Techniques
Nov 15, 2023Text word embeddings that encode distributional semantic features work by modeling contextual similarities of frequently occurring words. Acoustic word embeddings, on the other hand, typically encode low-level phonetic similarities. Semantic embeddings for spoken words have been previously explored using similar algorithms to Word2Vec, but the resulting vectors still mainly encoded phonetic rather than semantic features. In this paper, we examine the assumptions and architectures used in previous works and show experimentally how Word2Vec algorithms fail to encode distributional semantics when the input units are acoustically correlated. In addition, previous works relied on the simplifying assumptions of perfect word segmentation and clustering by word type. Given these conditions, a trivial solution identical to text-based embeddings has been overlooked. We follow this simpler path using automatic word type clustering and examine the effects on the resulting embeddings, highlighting the true challenges in this task.