 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehavior and Representation in Large Language Models for Combinatorial Optimization: From Feature Extraction to Algorithm Selection
Dec 15, 2025
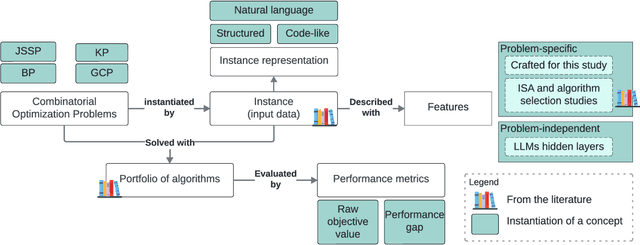

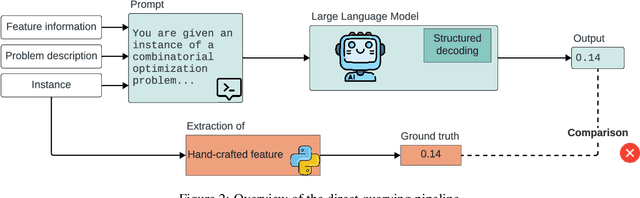
Recent advances in Large Language Models (LLMs) have opened new perspectives for automation in optimization. While several studies have explored how LLMs can generate or solve optimization models, far less is understood about what these models actually learn regarding problem structure or algorithmic behavior. This study investigates how LLMs internally represent combinatorial optimization problems and whether such representations can support downstream decision tasks. We adopt a twofold methodology combining direct querying, which assesses LLM capacity to explicitly extract instance features, with probing analyses that examine whether such information is implicitly encoded within their hidden layers. The probing framework is further extended to a per-instance algorithm selection task, evaluating whether LLM-derived representations can predict the best-performing solver. Experiments span four benchmark problems and three instance representations. Results show that LLMs exhibit moderate ability to recover feature information from problem instances, either through direct querying or probing. Notably, the predictive power of LLM hidden-layer representations proves comparable to that achieved through traditional feature extraction, suggesting that LLMs capture meaningful structural information relevant to optimization performance.
On Robustness and Reliability of Benchmark-Based Evaluation of LLMs
Sep 04, 2025Large Language Models (LLMs) effectiveness is usually evaluated by means of benchmarks such as MMLU, ARC-C, or HellaSwag, where questions are presented in their original wording, thus in a fixed, standardized format. However, real-world applications involve linguistic variability, requiring models to maintain their effectiveness across diverse rewordings of the same question or query. In this study, we systematically assess the robustness of LLMs to paraphrased benchmark questions and investigate whether benchmark-based evaluations provide a reliable measure of model capabilities. We systematically generate various paraphrases of all the questions across six different common benchmarks, and measure the resulting variations in effectiveness of 34 state-of-the-art LLMs, of different size and effectiveness. Our findings reveal that while LLM rankings remain relatively stable across paraphrased inputs, absolute effectiveness scores change, and decline significantly. This suggests that LLMs struggle with linguistic variability, raising concerns about their generalization abilities and evaluation methodologies. Furthermore, the observed performance drop challenges the reliability of benchmark-based evaluations, indicating that high benchmark scores may not fully capture a model's robustness to real-world input variations. We discuss the implications of these findings for LLM evaluation methodologies, emphasizing the need for robustness-aware benchmarks that better reflect practical deployment scenarios.
Geospatial Mechanistic Interpretability of Large Language Models
May 06, 2025Large Language Models (LLMs) have demonstrated unprecedented capabilities across various natural language processing tasks. Their ability to process and generate viable text and code has made them ubiquitous in many fields, while their deployment as knowledge bases and "reasoning" tools remains an area of ongoing research. In geography, a growing body of literature has been focusing on evaluating LLMs' geographical knowledge and their ability to perform spatial reasoning. However, very little is still known about the internal functioning of these models, especially about how they process geographical information. In this chapter, we establish a novel framework for the study of geospatial mechanistic interpretability - using spatial analysis to reverse engineer how LLMs handle geographical information. Our aim is to advance our understanding of the internal representations that these complex models generate while processing geographical information - what one might call "how LLMs think about geographic information" if such phrasing was not an undue anthropomorphism. We first outline the use of probing in revealing internal structures within LLMs. We then introduce the field of mechanistic interpretability, discussing the superposition hypothesis and the role of sparse autoencoders in disentangling polysemantic internal representations of LLMs into more interpretable, monosemantic features. In our experiments, we use spatial autocorrelation to show how features obtained for placenames display spatial patterns related to their geographic location and can thus be interpreted geospatially, providing insights into how these models process geographical information. We conclude by discussing how our framework can help shape the study and use of foundation models in geography.
Collecting Cost-Effective, High-Quality Truthfulness Assessments with LLM Summarized Evidence
Jan 30, 2025



With the degradation of guardrails against mis- and disinformation online, it is more critical than ever to be able to effectively combat it. In this paper, we explore the efficiency and effectiveness of using crowd-sourced truthfulness assessments based on condensed, large language model (LLM) generated summaries of online sources. We compare the use of generated summaries to the use of original web pages in an A/B testing setting, where we employ a large and diverse pool of crowd-workers to perform the truthfulness assessment. We evaluate the quality of assessments, the efficiency with which assessments are performed, and the behavior and engagement of participants. Our results demonstrate that the Summary modality, which relies on summarized evidence, offers no significant change in assessment accuracy over the Standard modality, while significantly increasing the speed with which assessments are performed. Workers using summarized evidence produce a significantly higher number of assessments in the same time frame, reducing the cost needed to acquire truthfulness assessments. Additionally, the Summary modality maximizes both the inter-annotator agreements as well as the reliance on and perceived usefulness of evidence, demonstrating the utility of summarized evidence without sacrificing the quality of assessments.
Data Bias Management
May 15, 2023

Due to the widespread use of data-powered systems in our everyday lives, concepts like bias and fairness gained significant attention among researchers and practitioners, in both industry and academia. Such issues typically emerge from the data, which comes with varying levels of quality, used to train supervised machine learning systems. With the commercialization and deployment of such systems that are sometimes delegated to make life-changing decisions, significant efforts are being made towards the identification and removal of possible sources of data bias that may resurface to the final end user or in the decisions being made. In this paper, we present research results that show how bias in data affects end users, where bias is originated, and provide a viewpoint about what we should do about it. We argue that data bias is not something that should necessarily be removed in all cases, and that research attention should instead shift from bias removal towards the identification, measurement, indexing, surfacing, and adapting for bias, which we name bias management.
Managing Bias in Human-Annotated Data: Moving Beyond Bias Removal
Oct 26, 2021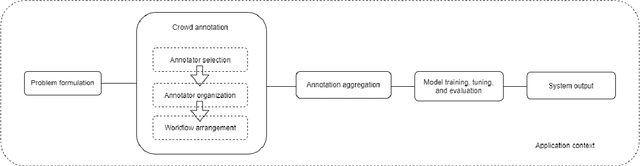
Due to the widespread use of data-powered systems in our everyday lives, the notions of bias and fairness gained significant attention among researchers and practitioners, in both industry and academia. Such issues typically emerge from the data, which comes with varying levels of quality, used to train systems. With the commercialization and employment of such systems that are sometimes delegated to make life-changing decisions, a significant effort is being made towards the identification and removal of possible sources of bias that may surface to the final end-user. In this position paper, we instead argue that bias is not something that should necessarily be removed in all cases, and the attention and effort should shift from bias removal to the identification, measurement, indexing, surfacing, and adjustment of bias, which we name bias management. We argue that if correctly managed, bias can be a resource that can be made transparent to the the users and empower them to make informed choices about their experience with the system.
The Many Dimensions of Truthfulness: Crowdsourcing Misinformation Assessments on a Multidimensional Scale
Aug 23, 2021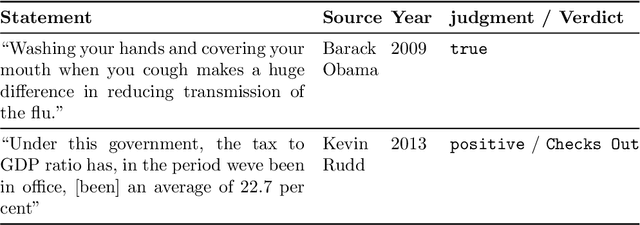
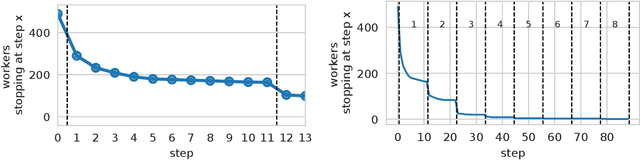
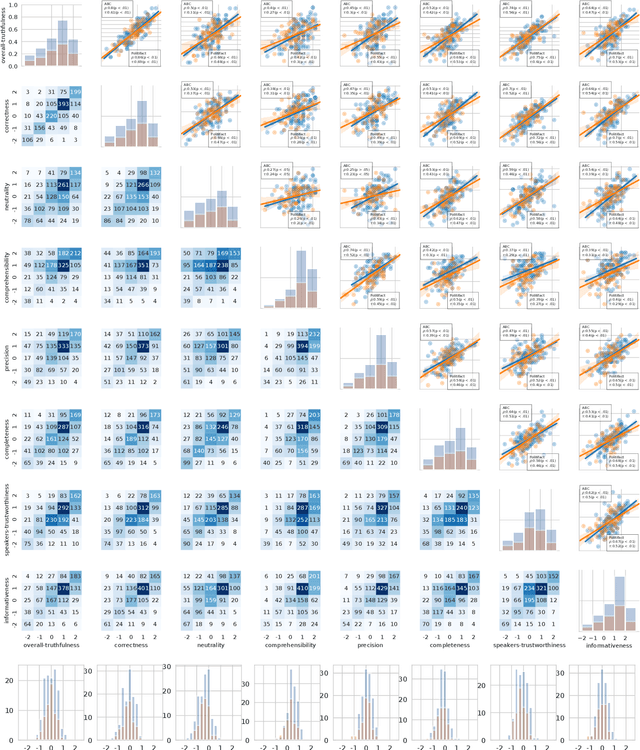
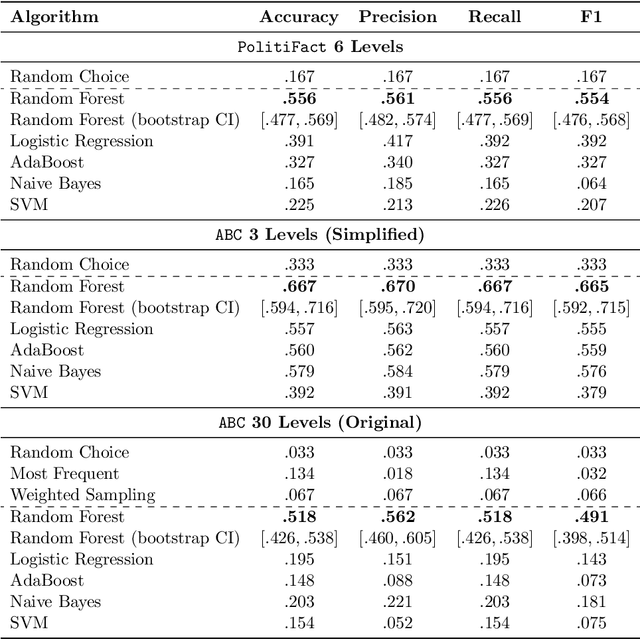
Recent work has demonstrated the viability of using crowdsourcing as a tool for evaluating the truthfulness of public statements. Under certain conditions such as: (1) having a balanced set of workers with different backgrounds and cognitive abilities; (2) using an adequate set of mechanisms to control the quality of the collected data; and (3) using a coarse grained assessment scale, the crowd can provide reliable identification of fake news. However, fake news are a subtle matter: statements can be just biased ("cherrypicked"), imprecise, wrong, etc. and the unidimensional truth scale used in existing work cannot account for such differences. In this paper we propose a multidimensional notion of truthfulness and we ask the crowd workers to assess seven different dimensions of truthfulness selected based on existing literature: Correctness, Neutrality, Comprehensibility, Precision, Completeness, Speaker's Trustworthiness, and Informativeness. We deploy a set of quality control mechanisms to ensure that the thousands of assessments collected on 180 publicly available fact-checked statements distributed over two datasets are of adequate quality, including a custom search engine used by the crowd workers to find web pages supporting their truthfulness assessments. A comprehensive analysis of crowdsourced judgments shows that: (1) the crowdsourced assessments are reliable when compared to an expert-provided gold standard; (2) the proposed dimensions of truthfulness capture independent pieces of information; (3) the crowdsourcing task can be easily learned by the workers; and (4) the resulting assessments provide a useful basis for a more complete estimation of statement truthfulness.
* 33 pages; Paper accepted at Information Processing & Management on July 28, 2021; IP&M Special Issue on Dis/Misinformation Mining from Social Media
Can the Crowd Judge Truthfulness? A Longitudinal Study on Recent Misinformation about COVID-19
Jul 25, 2021
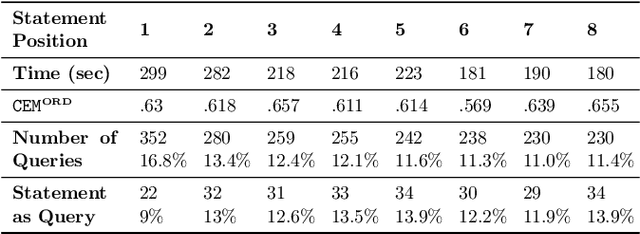
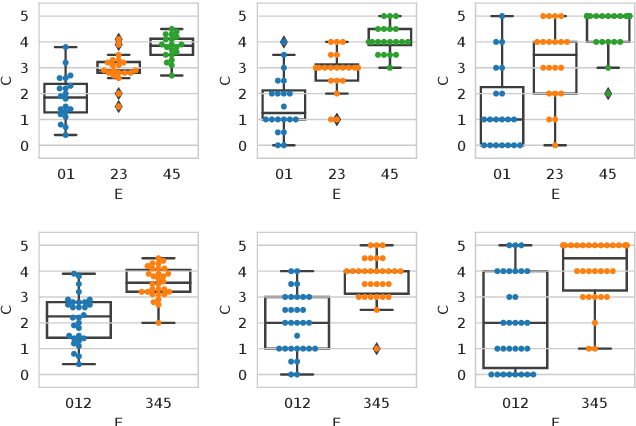
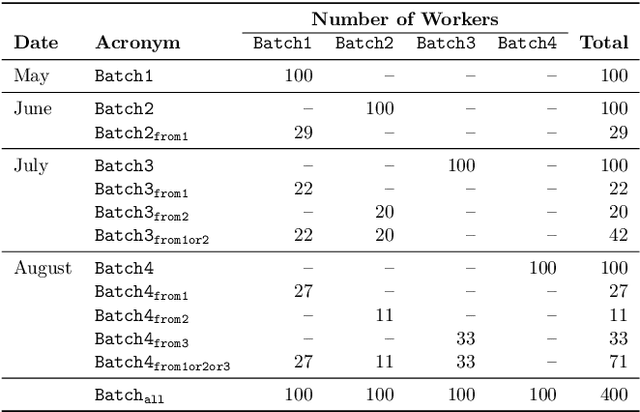
Recently, the misinformation problem has been addressed with a crowdsourcing-based approach: to assess the truthfulness of a statement, instead of relying on a few experts, a crowd of non-expert is exploited. We study whether crowdsourcing is an effective and reliable method to assess truthfulness during a pandemic, targeting statements related to COVID-19, thus addressing (mis)information that is both related to a sensitive and personal issue and very recent as compared to when the judgment is done. In our experiments, crowd workers are asked to assess the truthfulness of statements, and to provide evidence for the assessments. Besides showing that the crowd is able to accurately judge the truthfulness of the statements, we report results on workers behavior, agreement among workers, effect of aggregation functions, of scales transformations, and of workers background and bias. We perform a longitudinal study by re-launching the task multiple times with both novice and experienced workers, deriving important insights on how the behavior and quality change over time. Our results show that: workers are able to detect and objectively categorize online (mis)information related to COVID-19; both crowdsourced and expert judgments can be transformed and aggregated to improve quality; worker background and other signals (e.g., source of information, behavior) impact the quality of the data. The longitudinal study demonstrates that the time-span has a major effect on the quality of the judgments, for both novice and experienced workers. Finally, we provide an extensive failure analysis of the statements misjudged by the crowd-workers.
The COVID-19 Infodemic: Can the Crowd Judge Recent Misinformation Objectively?
Aug 13, 2020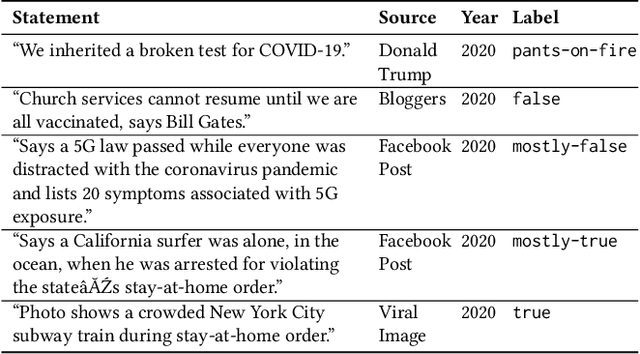
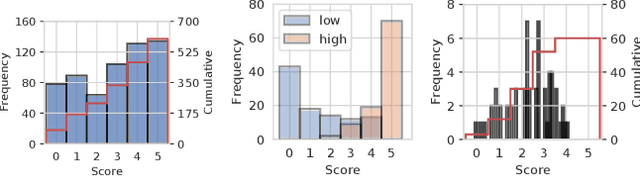

Misinformation is an ever increasing problem that is difficult to solve for the research community and has a negative impact on the society at large. Very recently, the problem has been addressed with a crowdsourcing-based approach to scale up labeling efforts: to assess the truthfulness of a statement, instead of relying on a few experts, a crowd of (non-expert) judges is exploited. We follow the same approach to study whether crowdsourcing is an effective and reliable method to assess statements truthfulness during a pandemic. We specifically target statements related to the COVID-19 health emergency, that is still ongoing at the time of the study and has arguably caused an increase of the amount of misinformation that is spreading online (a phenomenon for which the term "infodemic" has been used). By doing so, we are able to address (mis)information that is both related to a sensitive and personal issue like health and very recent as compared to when the judgment is done: two issues that have not been analyzed in related work. In our experiment, crowd workers are asked to assess the truthfulness of statements, as well as to provide evidence for the assessments as a URL and a text justification. Besides showing that the crowd is able to accurately judge the truthfulness of the statements, we also report results on many different aspects, including: agreement among workers, the effect of different aggregation functions, of scales transformations, and of workers background / bias. We also analyze workers behavior, in terms of queries submitted, URLs found / selected, text justifications, and other behavioral data like clicks and mouse actions collected by means of an ad hoc logger.