 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Bias Management
Paper and Code
May 15, 2023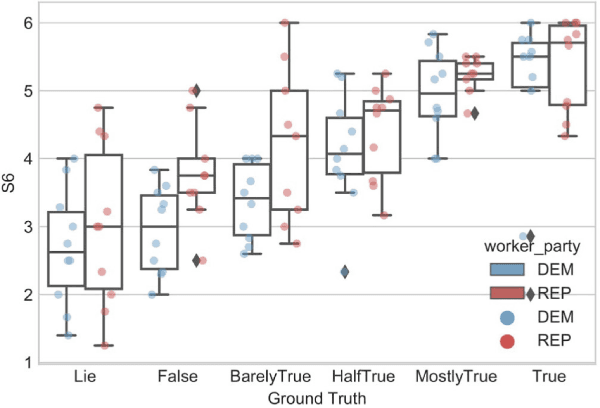

Due to the widespread use of data-powered systems in our everyday lives, concepts like bias and fairness gained significant attention among researchers and practitioners, in both industry and academia. Such issues typically emerge from the data, which comes with varying levels of quality, used to train supervised machine learning systems. With the commercialization and deployment of such systems that are sometimes delegated to make life-changing decisions, significant efforts are being made towards the identification and removal of possible sources of data bias that may resurface to the final end user or in the decisions being made. In this paper, we present research results that show how bias in data affects end users, where bias is originated, and provide a viewpoint about what we should do about it. We argue that data bias is not something that should necessarily be removed in all cases, and that research attention should instead shift from bias removal towards the identification, measurement, indexing, surfacing, and adapting for bias, which we name bias management.