 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNacala-Roof-Material: Drone Imagery for Roof Detection, Classification, and Segmentation to Support Mosquito-borne Disease Risk Assessment
Jun 07, 2024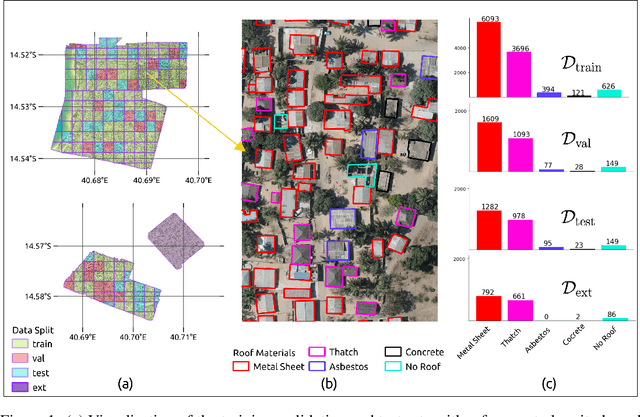
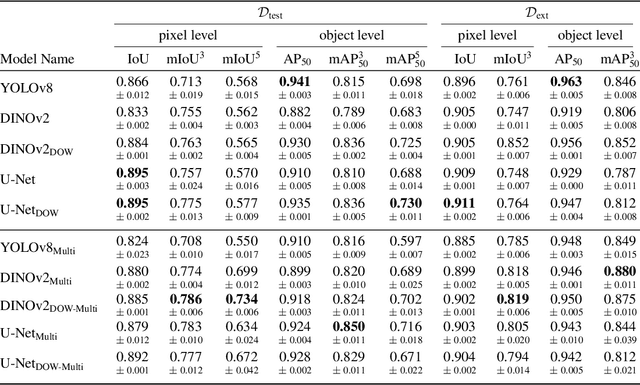
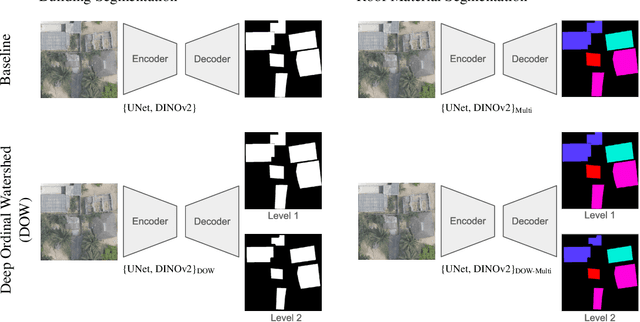

As low-quality housing and in particular certain roof characteristics are associated with an increased risk of malaria, classification of roof types based on remote sensing imagery can support the assessment of malaria risk and thereby help prevent the disease. To support research in this area, we release the Nacala-Roof-Material dataset, which contains high-resolution drone images from Mozambique with corresponding labels delineating houses and specifying their roof types. The dataset defines a multi-task computer vision problem, comprising object detection, classification, and segmentation. In addition, we benchmarked various state-of-the-art approaches on the dataset. Canonical U-Nets, YOLOv8, and a custom decoder on pretrained DINOv2 served as baselines. We show that each of the methods has its advantages but none is superior on all tasks, which highlights the potential of our dataset for future research in multi-task learning. While the tasks are closely related, accurate segmentation of objects does not necessarily imply accurate instance separation, and vice versa. We address this general issue by introducing a variant of the deep ordinal watershed (DOW) approach that additionally separates the interior of objects, allowing for improved object delineation and separation. We show that our DOW variant is a generic approach that improves the performance of both U-Net and DINOv2 backbones, leading to a better trade-off between semantic segmentation and instance segmentation.
MMEarth: Exploring Multi-Modal Pretext Tasks For Geospatial Representation Learning
May 04, 2024



The volume of unlabelled Earth observation (EO) data is huge, but many important applications lack labelled training data. However, EO data offers the unique opportunity to pair data from different modalities and sensors automatically based on geographic location and time, at virtually no human labor cost. We seize this opportunity to create a diverse multi-modal pretraining dataset at global scale. Using this new corpus of 1.2 million locations, we propose a Multi-Pretext Masked Autoencoder (MP-MAE) approach to learn general-purpose representations for optical satellite images. Our approach builds on the ConvNeXt V2 architecture, a fully convolutional masked autoencoder (MAE). Drawing upon a suite of multi-modal pretext tasks, we demonstrate that our MP-MAE approach outperforms both MAEs pretrained on ImageNet and MAEs pretrained on domain-specific satellite images. This is shown on several downstream tasks including image classification and semantic segmentation. We find that multi-modal pretraining notably improves the linear probing performance, e.g. 4pp on BigEarthNet and 16pp on So2Sat, compared to pretraining on optical satellite images only. We show that this also leads to better label and parameter efficiency which are crucial aspects in global scale applications.
Predicting urban tree cover from incomplete point labels and limited background information
Nov 20, 2023



Trees inside cities are important for the urban microclimate, contributing positively to the physical and mental health of the urban dwellers. Despite their importance, often only limited information about city trees is available. Therefore in this paper, we propose a method for mapping urban trees in high-resolution aerial imagery using limited datasets and deep learning. Deep learning has become best-practice for this task, however, existing approaches rely on large and accurately labelled training datasets, which can be difficult and expensive to obtain. However, often noisy and incomplete data may be available that can be combined and utilized to solve more difficult tasks than those datasets were intended for. This paper studies how to combine accurate point labels of urban trees along streets with crowd-sourced annotations from an open geographic database to delineate city trees in remote sensing images, a task which is challenging even for humans. To that end, we perform semantic segmentation of very high resolution aerial imagery using a fully convolutional neural network. The main challenge is that our segmentation maps are sparsely annotated and incomplete. Small areas around the point labels of the street trees coming from official and crowd-sourced data are marked as foreground class. Crowd-sourced annotations of streets, buildings, etc. define the background class. Since the tree data is incomplete, we introduce a masking to avoid class confusion. Our experiments in Hamburg, Germany, showed that the system is able to produce tree cover maps, not limited to trees along streets, without providing tree delineations. We evaluated the method on manually labelled trees and show that performance drastically deteriorates if the open geographic database is not used.
Benchmarking Individual Tree Mapping with Sub-meter Imagery
Nov 14, 2023

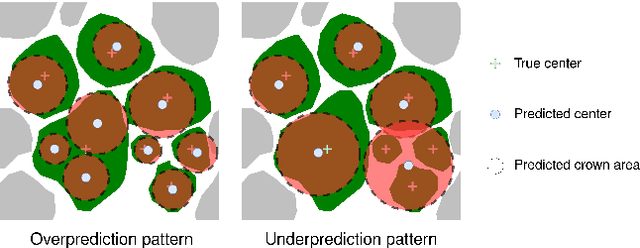

There is a rising interest in mapping trees using satellite or aerial imagery, but there is no standardized evaluation protocol for comparing and enhancing methods. In dense canopy areas, the high variability of tree sizes and their spatial proximity makes it arduous to define the quality of the predictions. Concurrently, object-centric approaches such as bounding box detection usuallyperform poorly on small and dense objects. It thus remains unclear what is the ideal framework for individual tree mapping, in regards to detection and segmentation approaches, convolutional neural networks and transformers. In this paper, we introduce an evaluation framework suited for individual tree mapping in any physical environment, with annotation costs and applicative goals in mind. We review and compare different approaches and deep architectures, and introduce a new method that we experimentally prove to be a good compromise between segmentation and detection.
MaskIt: Masking for efficient utilization of incomplete public datasets for training deep learning models
Jun 22, 2020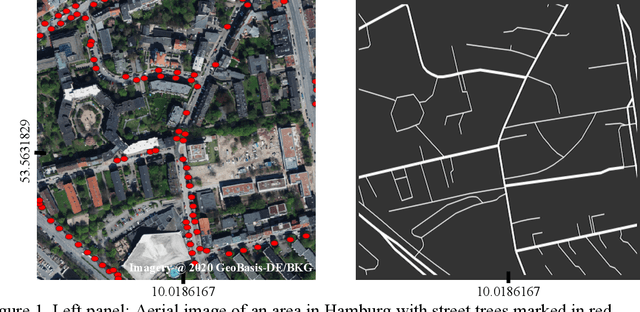
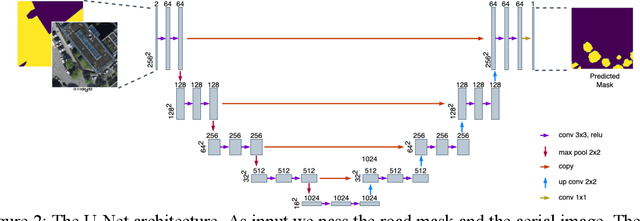

A major challenge in training deep learning models is the lack of high quality and complete datasets. In the paper, we present a masking approach for training deep learning models from a publicly available but incomplete dataset. For example, city of Hamburg, Germany maintains a list of trees along the roads, but this dataset does not contain any information about trees in private homes and parks. To train a deep learning model on such a dataset, we mask the street trees and aerial images with the road network. Road network used for creating the mask is downloaded from OpenStreetMap, and it marks the area where the training data is available. The mask is passed to the model as one of the inputs and it also coats the output. Our model learns to successfully predict trees only in the masked region with 78.4% accuracy.