 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCanopy Tree Height Estimation Using Quantile Regression: Modeling and Evaluating Uncertainty in Remote Sensing
Apr 08, 2026Accurate tree height estimation is vital for ecological monitoring and biomass assessment. We apply quantile regression to existing tree height estimation models based on satellite data to incorporate uncertainty quantification. Most current approaches for tree height estimation rely on point predictions, which limits their applicability in risk-sensitive scenarios. In this work, we show that, with minor modifications of a given prediction head, existing models can be adapted to provide statistically calibrated uncertainty estimates via quantile regression. Furthermore, we demonstrate how our results correlate with known challenges in remote sensing (e.g., terrain complexity, vegetation heterogeneity), indicating that the model is less confident in more challenging conditions.
Trainable Bitwise Soft Quantization for Input Feature Compression
Mar 05, 2026The growing demand for machine learning applications in the context of the Internet of Things calls for new approaches to optimize the use of limited compute and memory resources. Despite significant progress that has been made w.r.t. reducing model sizes and improving efficiency, many applications still require remote servers to provide the required resources. However, such approaches rely on transmitting data from edge devices to remote servers, which may not always be feasible due to bandwidth, latency, or energy constraints. We propose a task-specific, trainable feature quantization layer that compresses the input features of a neural network. This can significantly reduce the amount of data that needs to be transferred from the device to a remote server. In particular, the layer allows each input feature to be quantized to a user-defined number of bits, enabling a simple on-device compression at the time of data collection. The layer is designed to approximate step functions with sigmoids, enabling trainable quantization thresholds. By concatenating outputs from multiple sigmoids, introduced as bitwise soft quantization, it achieves trainable quantized values when integrated with a neural network. We compare our method to full-precision inference as well as to several quantization baselines. Experiments show that our approach outperforms standard quantization methods, while maintaining accuracy levels close to those of full-precision models. In particular, depending on the dataset, compression factors of $5\times$ to $16\times$ can be achieved compared to $32$-bit input without significant performance loss.
ECHOSAT: Estimating Canopy Height Over Space And Time
Feb 24, 2026Forest monitoring is critical for climate change mitigation. However, existing global tree height maps provide only static snapshots and do not capture temporal forest dynamics, which are essential for accurate carbon accounting. We introduce ECHOSAT, a global and temporally consistent tree height map at 10 m resolution spanning multiple years. To this end, we resort to multi-sensor satellite data to train a specialized vision transformer model, which performs pixel-level temporal regression. A self-supervised growth loss regularizes the predictions to follow growth curves that are in line with natural tree development, including gradual height increases over time, but also abrupt declines due to forest loss events such as fires. Our experimental evaluation shows that our model improves state-of-the-art accuracies in the context of single-year predictions. We also provide the first global-scale height map that accurately quantifies tree growth and disturbances over time. We expect ECHOSAT to advance global efforts in carbon monitoring and disturbance assessment. The maps can be accessed at https://github.com/ai4forest/echosat.
Boosted Trees on a Diet: Compact Models for Resource-Constrained Devices
Oct 30, 2025Deploying machine learning models on compute-constrained devices has become a key building block of modern IoT applications. In this work, we present a compression scheme for boosted decision trees, addressing the growing need for lightweight machine learning models. Specifically, we provide techniques for training compact boosted decision tree ensembles that exhibit a reduced memory footprint by rewarding, among other things, the reuse of features and thresholds during training. Our experimental evaluation shows that models achieved the same performance with a compression ratio of 4-16x compared to LightGBM models using an adapted training process and an alternative memory layout. Once deployed, the corresponding IoT devices can operate independently of constant communication or external energy supply, and, thus, autonomously, requiring only minimal computing power and energy. This capability opens the door to a wide range of IoT applications, including remote monitoring, edge analytics, and real-time decision making in isolated or power-limited environments.
DUNIA: Pixel-Sized Embeddings via Cross-Modal Alignment for Earth Observation Applications
Feb 24, 2025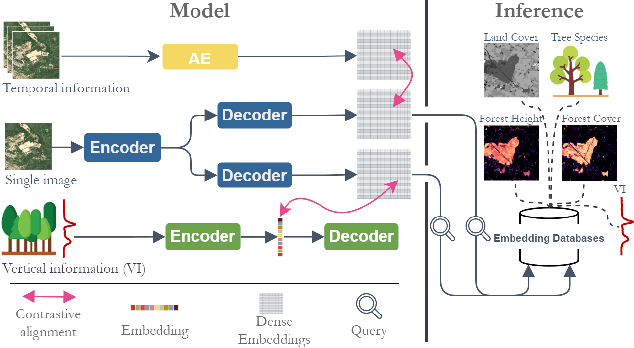
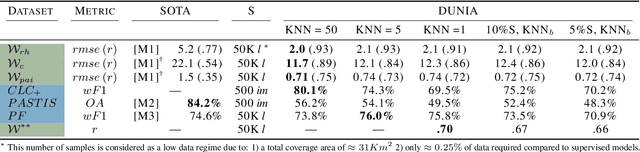
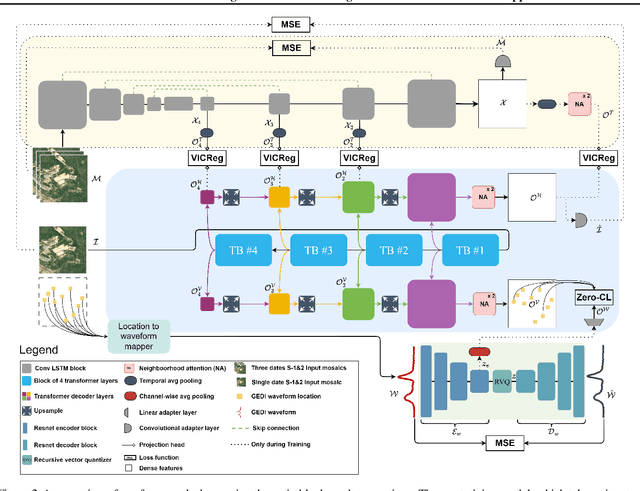

Significant efforts have been directed towards adapting self-supervised multimodal learning for Earth observation applications. However, existing methods produce coarse patch-sized embeddings, limiting their effectiveness and integration with other modalities like LiDAR. To close this gap, we present DUNIA, an approach to learn pixel-sized embeddings through cross-modal alignment between images and full-waveform LiDAR data. As the model is trained in a contrastive manner, the embeddings can be directly leveraged in the context of a variety of environmental monitoring tasks in a zero-shot setting. In our experiments, we demonstrate the effectiveness of the embeddings for seven such tasks (canopy height mapping, fractional canopy cover, land cover mapping, tree species identification, plant area index, crop type classification, and per-pixel waveform-based vertical structure mapping). The results show that the embeddings, along with zero-shot classifiers, often outperform specialized supervised models, even in low data regimes. In the fine-tuning setting, we show strong low-shot capabilities with performances near or better than state-of-the-art on five out of six tasks.
Capturing Temporal Dynamics in Large-Scale Canopy Tree Height Estimation
Jan 31, 2025



With the rise in global greenhouse gas emissions, accurate large-scale tree canopy height maps are essential for understanding forest structure, estimating above-ground biomass, and monitoring ecological disruptions. To this end, we present a novel approach to generate large-scale, high-resolution canopy height maps over time. Our model accurately predicts canopy height over multiple years given Sentinel-2 time series satellite data. Using GEDI LiDAR data as the ground truth for training the model, we present the first 10m resolution temporal canopy height map of the European continent for the period 2019-2022. As part of this product, we also offer a detailed canopy height map for 2020, providing more precise estimates than previous studies. Our pipeline and the resulting temporal height map are publicly available, enabling comprehensive large-scale monitoring of forests and, hence, facilitating future research and ecological analyses. For an interactive viewer, see https://europetreemap.projects.earthengine.app/view/temporalcanopyheight.
CLIP-Branches: Interactive Fine-Tuning for Text-Image Retrieval
Jun 19, 2024



The advent of text-image models, most notably CLIP, has significantly transformed the landscape of information retrieval. These models enable the fusion of various modalities, such as text and images. One significant outcome of CLIP is its capability to allow users to search for images using text as a query, as well as vice versa. This is achieved via a joint embedding of images and text data that can, for instance, be used to search for similar items. Despite efficient query processing techniques such as approximate nearest neighbor search, the results may lack precision and completeness. We introduce CLIP-Branches, a novel text-image search engine built upon the CLIP architecture. Our approach enhances traditional text-image search engines by incorporating an interactive fine-tuning phase, which allows the user to further concretize the search query by iteratively defining positive and negative examples. Our framework involves training a classification model given the additional user feedback and essentially outputs all positively classified instances of the entire data catalog. By building upon recent techniques, this inference phase, however, is not implemented by scanning the entire data catalog, but by employing efficient index structures pre-built for the data. Our results show that the fine-tuned results can improve the initial search outputs in terms of relevance and accuracy while maintaining swift response times
Estimating Canopy Height at Scale
Jun 03, 2024



We propose a framework for global-scale canopy height estimation based on satellite data. Our model leverages advanced data preprocessing techniques, resorts to a novel loss function designed to counter geolocation inaccuracies inherent in the ground-truth height measurements, and employs data from the Shuttle Radar Topography Mission to effectively filter out erroneous labels in mountainous regions, enhancing the reliability of our predictions in those areas. A comparison between predictions and ground-truth labels yields an MAE / RMSE of 2.43 / 4.73 (meters) overall and 4.45 / 6.72 (meters) for trees taller than five meters, which depicts a substantial improvement compared to existing global-scale maps. The resulting height map as well as the underlying framework will facilitate and enhance ecological analyses at a global scale, including, but not limited to, large-scale forest and biomass monitoring.
Tree Counting by Bridging 3D Point Clouds with Imagery
Mar 12, 2024



Accurate and consistent methods for counting trees based on remote sensing data are needed to support sustainable forest management, assess climate change mitigation strategies, and build trust in tree carbon credits. Two-dimensional remote sensing imagery primarily shows overstory canopy, and it does not facilitate easy differentiation of individual trees in areas with a dense canopy and does not allow for easy separation of trees when the canopy is dense. We leverage the fusion of three-dimensional LiDAR measurements and 2D imagery to facilitate the accurate counting of trees. We compare a deep learning approach to counting trees in forests using 3D airborne LiDAR data and 2D imagery. The approach is compared with state-of-the-art algorithms, like operating on 3D point cloud and 2D imagery. We empirically evaluate the different methods on the NeonTreeCount data set, which we use to define a tree-counting benchmark. The experiments show that FuseCountNet yields more accurate tree counts.
End-to-End Neural Network Training for Hyperbox-Based Classification
Aug 01, 2023



Hyperbox-based classification has been seen as a promising technique in which decisions on the data are represented as a series of orthogonal, multidimensional boxes (i.e., hyperboxes) that are often interpretable and human-readable. However, existing methods are no longer capable of efficiently handling the increasing volume of data many application domains face nowadays. We address this gap by proposing a novel, fully differentiable framework for hyperbox-based classification via neural networks. In contrast to previous work, our hyperbox models can be efficiently trained in an end-to-end fashion, which leads to significantly reduced training times and superior classification results.