 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSERA-H: Beyond Native Sentinel Spatial Limits for High-Resolution Canopy Height Mapping
Dec 19, 2025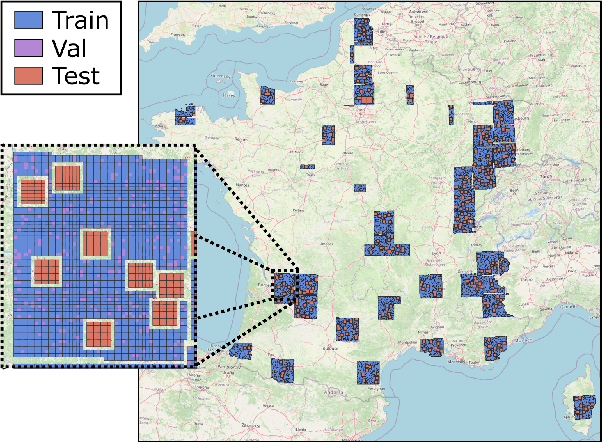
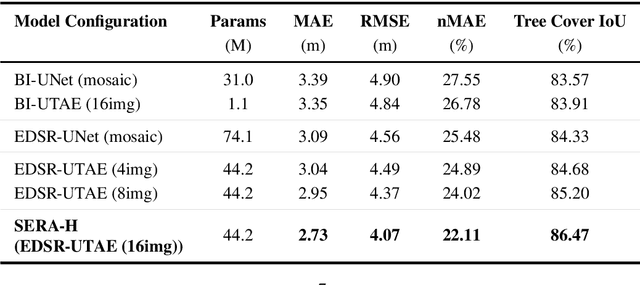
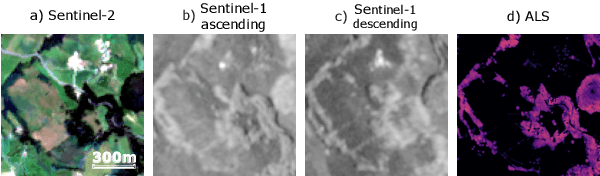
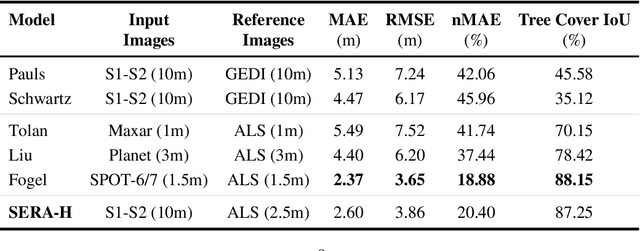
High-resolution mapping of canopy height is essential for forest management and biodiversity monitoring. Although recent studies have led to the advent of deep learning methods using satellite imagery to predict height maps, these approaches often face a trade-off between data accessibility and spatial resolution. To overcome these limitations, we present SERA-H, an end-to-end model combining a super-resolution module (EDSR) and temporal attention encoding (UTAE). Trained under the supervision of high-density LiDAR data (ALS), our model generates 2.5 m resolution height maps from freely available Sentinel-1 and Sentinel-2 (10 m) time series data. Evaluated on an open-source benchmark dataset in France, SERA-H, with a MAE of 2.6 m and a coefficient of determination of 0.82, not only outperforms standard Sentinel-1/2 baselines but also achieves performance comparable to or better than methods relying on commercial very high-resolution imagery (SPOT-6/7, PlanetScope, Maxar). These results demonstrate that combining high-resolution supervision with the spatiotemporal information embedded in time series enables the reconstruction of details beyond the input sensors' native resolution. SERA-H opens the possibility of freely mapping forests with high revisit frequency, achieving accuracy comparable to that of costly commercial imagery. The source code is available at https://github.com/ThomasBoudras/SERA-H#
DUNIA: Pixel-Sized Embeddings via Cross-Modal Alignment for Earth Observation Applications
Feb 24, 2025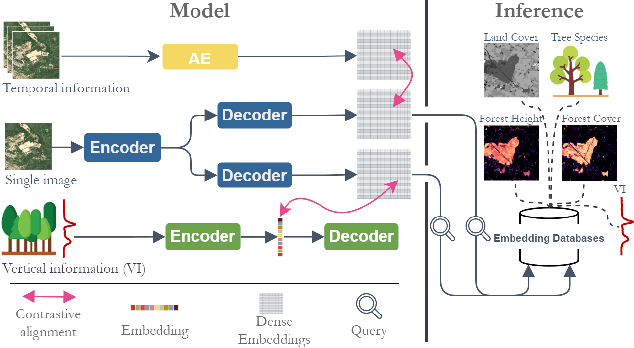
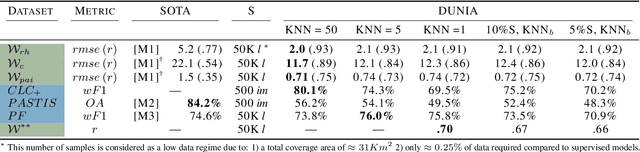
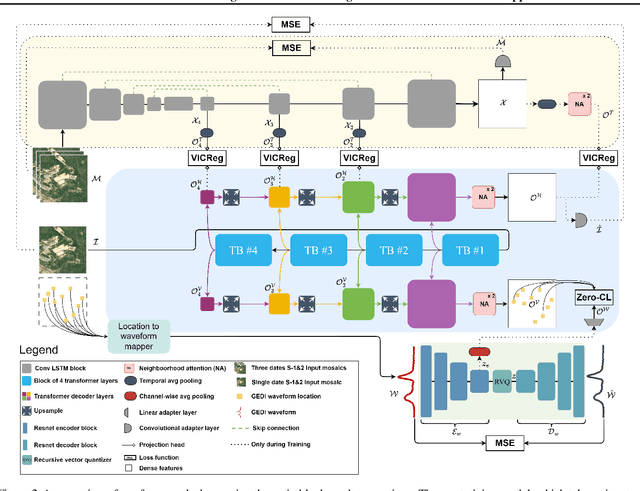

Significant efforts have been directed towards adapting self-supervised multimodal learning for Earth observation applications. However, existing methods produce coarse patch-sized embeddings, limiting their effectiveness and integration with other modalities like LiDAR. To close this gap, we present DUNIA, an approach to learn pixel-sized embeddings through cross-modal alignment between images and full-waveform LiDAR data. As the model is trained in a contrastive manner, the embeddings can be directly leveraged in the context of a variety of environmental monitoring tasks in a zero-shot setting. In our experiments, we demonstrate the effectiveness of the embeddings for seven such tasks (canopy height mapping, fractional canopy cover, land cover mapping, tree species identification, plant area index, crop type classification, and per-pixel waveform-based vertical structure mapping). The results show that the embeddings, along with zero-shot classifiers, often outperform specialized supervised models, even in low data regimes. In the fine-tuning setting, we show strong low-shot capabilities with performances near or better than state-of-the-art on five out of six tasks.
Optimization without Backpropagation
Sep 13, 2022
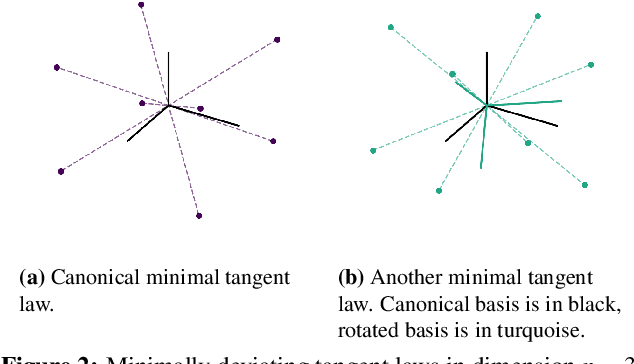


Forward gradients have been recently introduced to bypass backpropagation in autodifferentiation, while retaining unbiased estimators of true gradients. We derive an optimality condition to obtain best approximating forward gradients, which leads us to mathematical insights that suggest optimization in high dimension is challenging with forward gradients. Our extensive experiments on test functions support this claim.