 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Do Evolutionary Coding Agents Evolve?
May 19, 2026Recent work pairs LLMs with evolutionary search to iteratively generate, modify, and select code using task-specific feedback. These systems have produced strong results in mathematical discovery and algorithm design, yet a fundamental question remains: what do they actually evolve? Progress is typically summarized by the best score a run reaches under a task-specific evaluator, but that score can reflect several different mechanisms: new algorithmic structure, re-tuning an existing strategy, recombining ideas already in the model's internal knowledge, or overfitting to the evaluator. Distinguishing these mechanisms requires inspecting the search process itself, not only its final outcome. We introduce EvoTrace, a dataset of evolutionary coding traces spanning four evolutionary frameworks, reasoning and non-reasoning models, and 16 tasks across mathematics and algorithm design. To analyze these traces, we develop EvoReplay, a replay-based methodology that reconstructs the local search states behind high-scoring solutions and tests controlled interventions, including adjusting constants, removing program components and substituting models or prompting contexts. We annotate every code edit in EvoTrace with one of nine recurring edit types using an LLM-as-judge pipeline validated against blind human re-annotation. Across EvoTrace, most score gains come from a small subset of these edit types. We further find a deterministic cycling pattern: about 30% of code lines added during search are byte-identical re-introductions of previously-deleted lines, present throughout nearly every run. These results show that benchmark gains in evolutionary coding agents can arise from qualitatively different mechanisms, only some of which correspond to new algorithmic structure. EvoTrace enables more diagnostic evaluation of evolutionary coding agents beyond final benchmark scores.
When Does Sparsity Mitigate the Curse of Depth in LLMs
Mar 16, 2026Recent work has demonstrated the curse of depth in large language models (LLMs), where later layers contribute less to learning and representation than earlier layers. Such under-utilization is linked to the accumulated growth of variance in Pre-Layer Normalization, which can push deep blocks toward near-identity behavior. In this paper, we demonstrate that, sparsity, beyond enabling efficiency, acts as a regulator of variance propagation and thereby improves depth utilization. Our investigation covers two sources of sparsity: (i) implicit sparsity, which emerges from training and data conditions, including weight sparsity induced by weight decay and attention sparsity induced by long context inputs; and (ii) explicit sparsity, which is enforced by architectural design, including key/value-sharing sparsity in Grouped-Query Attention and expert-activation sparsity in Mixtureof-Experts. Our claim is thoroughly supported by controlled depth-scaling experiments and targeted layer effectiveness interventions. Across settings, we observe a consistent relationship: sparsity improves layer utilization by reducing output variance and promoting functional differentiation. We eventually distill our findings into a practical rule-of-thumb recipe for training deptheffective LLMs, yielding a notable 4.6% accuracy improvement on downstream tasks. Our results reveal sparsity, arising naturally from standard design choices, as a key yet previously overlooked mechanism for effective depth scaling in LLMs. Code is available at https://github.com/pUmpKin-Co/SparsityAndCoD.
The Agentic Researcher: A Practical Guide to AI-Assisted Research in Mathematics and Machine Learning
Mar 16, 2026AI tools and agents are reshaping how researchers work, from proving theorems to training neural networks. Yet for many, it remains unclear how these tools fit into everyday research practice. This paper is a practical guide to AI-assisted research in mathematics and machine learning: We discuss how researchers can use modern AI systems productively, where these systems help most, and what kinds of guardrails are needed to use them responsibly. It is organized into three parts: (I) a five-level taxonomy of AI integration, (II) an open-source framework that, through a set of methodological rules formulated as agent prompts, turns CLI coding agents (e.g., Claude Code, Codex CLI, OpenCode) into autonomous research assistants, and (III) case studies from deep learning and mathematics. The framework runs inside a sandboxed container, works with any frontier LLM through existing CLI agents, is simple enough to install and use within minutes, and scales from personal-laptop prototyping to multi-node, multi-GPU experimentation across compute clusters. In practice, our longest autonomous session ran for over 20 hours, dispatching independent experiments across multiple nodes without human intervention. We stress that our framework is not intended to replace the researcher in the loop, but to augment them. Our code is publicly available at https://github.com/ZIB-IOL/The-Agentic-Researcher.
ECHOSAT: Estimating Canopy Height Over Space And Time
Feb 24, 2026Forest monitoring is critical for climate change mitigation. However, existing global tree height maps provide only static snapshots and do not capture temporal forest dynamics, which are essential for accurate carbon accounting. We introduce ECHOSAT, a global and temporally consistent tree height map at 10 m resolution spanning multiple years. To this end, we resort to multi-sensor satellite data to train a specialized vision transformer model, which performs pixel-level temporal regression. A self-supervised growth loss regularizes the predictions to follow growth curves that are in line with natural tree development, including gradual height increases over time, but also abrupt declines due to forest loss events such as fires. Our experimental evaluation shows that our model improves state-of-the-art accuracies in the context of single-year predictions. We also provide the first global-scale height map that accurately quantifies tree growth and disturbances over time. We expect ECHOSAT to advance global efforts in carbon monitoring and disturbance assessment. The maps can be accessed at https://github.com/ai4forest/echosat.
From Associations to Activations: Comparing Behavioral and Hidden-State Semantic Geometry in LLMs
Jan 31, 2026We investigate the extent to which an LLM's hidden-state geometry can be recovered from its behavior in psycholinguistic experiments. Across eight instruction-tuned transformer models, we run two experimental paradigms -- similarity-based forced choice and free association -- over a shared 5,000-word vocabulary, collecting 17.5M+ trials to build behavior-based similarity matrices. Using representational similarity analysis, we compare behavioral geometries to layerwise hidden-state similarity and benchmark against FastText, BERT, and cross-model consensus. We find that forced-choice behavior aligns substantially more with hidden-state geometry than free association. In a held-out-words regression, behavioral similarity (especially forced choice) predicts unseen hidden-state similarities beyond lexical baselines and cross-model consensus, indicating that behavior-only measurements retain recoverable information about internal semantic geometry. Finally, we discuss implications for the ability of behavioral tasks to uncover hidden cognitive states.
SparseSwaps: Tractable LLM Pruning Mask Refinement at Scale
Dec 11, 2025The resource requirements of Neural Networks can be significantly reduced through pruning -- the removal of seemingly less important parameters. However, with the rise of Large Language Models (LLMs), full retraining to recover pruning-induced performance degradation is often prohibitive and classical approaches such as global magnitude pruning are suboptimal on Transformer architectures. State-of-the-art methods hence solve a layer-wise mask selection problem, the problem of finding a pruning mask which minimizes the per-layer pruning error on a small set of calibration data. Exactly solving this problem to optimality using Integer Programming (IP) solvers is computationally infeasible due to its combinatorial nature and the size of the search space, and existing approaches therefore rely on approximations or heuristics. In this work, we demonstrate that the mask selection problem can be made drastically more tractable at LLM scale. To that end, we decouple the rows by enforcing equal sparsity levels per row. This allows us to derive optimal 1-swaps (exchanging one kept and one pruned weight) that can be computed efficiently using the Gram matrix of the calibration data. Using these observations, we propose a tractable and simple 1-swap algorithm that warm starts from any pruning mask, runs efficiently on GPUs at LLM scale, and is essentially hyperparameter-free. We demonstrate that our approach reduces per-layer pruning error by up to 60% over Wanda (Sun et al., 2023) and consistently improves perplexity and zero-shot accuracy across state-of-the-art GPT architectures.
A Free Lunch in LLM Compression: Revisiting Retraining after Pruning
Oct 16, 2025While Neural Network pruning typically requires retraining the model to recover pruning-induced performance degradation, state-of-the-art Large Language Models (LLMs) pruning methods instead solve a layer-wise mask selection and reconstruction problem on a small set of calibration data to avoid full retraining, as it is considered computationally infeasible for LLMs. Reconstructing single matrices in isolation has favorable properties, such as convexity of the objective and significantly reduced memory requirements compared to full retraining. In practice, however, reconstruction is often implemented at coarser granularities, e.g., reconstructing a whole transformer block against its dense activations instead of a single matrix. In this work, we study the key design choices when reconstructing or retraining the remaining weights after pruning. We conduct an extensive computational study on state-of-the-art GPT architectures, and report several surprising findings that challenge common intuitions about retraining after pruning. In particular, we observe a free lunch scenario: reconstructing attention and MLP components separately within each transformer block is nearly the most resource-efficient yet achieves the best perplexity. Most importantly, this Pareto-optimal setup achieves better performance than full retraining, despite requiring only a fraction of the memory. Furthermore, we demonstrate that simple and efficient pruning criteria such as Wanda can outperform much more complex approaches when the reconstruction step is properly executed, highlighting its importance. Our findings challenge the narrative that retraining should be avoided at all costs and provide important insights into post-pruning performance recovery for LLMs.
Computational Algebra with Attention: Transformer Oracles for Border Basis Algorithms
May 29, 2025Solving systems of polynomial equations, particularly those with finitely many solutions, is a crucial challenge across many scientific fields. Traditional methods like Gr\"obner and Border bases are fundamental but suffer from high computational costs, which have motivated recent Deep Learning approaches to improve efficiency, albeit at the expense of output correctness. In this work, we introduce the Oracle Border Basis Algorithm, the first Deep Learning approach that accelerates Border basis computation while maintaining output guarantees. To this end, we design and train a Transformer-based oracle that identifies and eliminates computationally expensive reduction steps, which we find to dominate the algorithm's runtime. By selectively invoking this oracle during critical phases of computation, we achieve substantial speedup factors of up to 3.5x compared to the base algorithm, without compromising the correctness of results. To generate the training data, we develop a sampling method and provide the first sampling theorem for border bases. We construct a tokenization and embedding scheme tailored to monomial-centered algebraic computations, resulting in a compact and expressive input representation, which reduces the number of tokens to encode an $n$-variate polynomial by a factor of $O(n)$. Our learning approach is data efficient, stable, and a practical enhancement to traditional computer algebra algorithms and symbolic computation.
RECON: Robust symmetry discovery via Explicit Canonical Orientation Normalization
May 19, 2025Real-world data often exhibits unknown or approximate symmetries, yet existing equivariant networks must commit to a fixed transformation group prior to training, e.g., continuous $SO(2)$ rotations. This mismatch degrades performance when the actual data symmetries differ from those in the transformation group. We introduce RECON, a framework to discover each input's intrinsic symmetry distribution from unlabeled data. RECON leverages class-pose decompositions and applies a data-driven normalization to align arbitrary reference frames into a common natural pose, yielding directly comparable and interpretable symmetry descriptors. We demonstrate effective symmetry discovery on 2D image benchmarks and -- for the first time -- extend it to 3D transformation groups, paving the way towards more flexible equivariant modeling.
DUNIA: Pixel-Sized Embeddings via Cross-Modal Alignment for Earth Observation Applications
Feb 24, 2025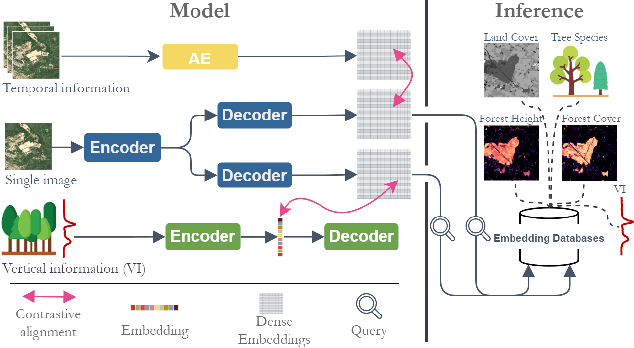
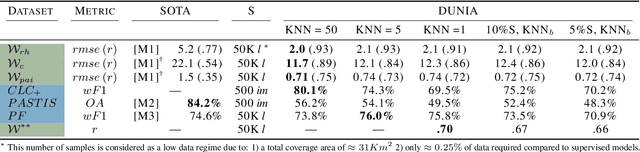
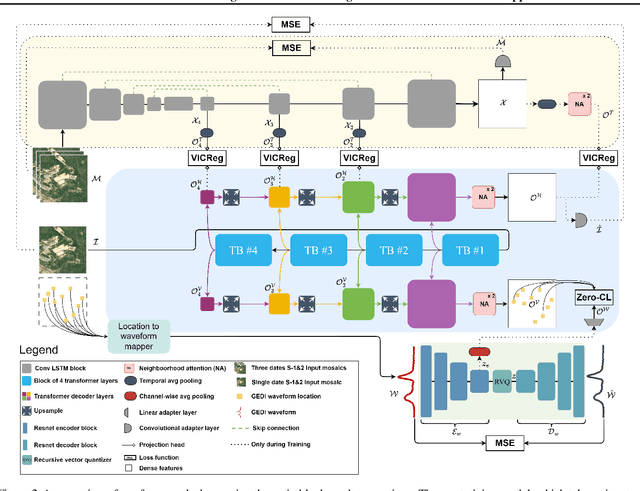

Significant efforts have been directed towards adapting self-supervised multimodal learning for Earth observation applications. However, existing methods produce coarse patch-sized embeddings, limiting their effectiveness and integration with other modalities like LiDAR. To close this gap, we present DUNIA, an approach to learn pixel-sized embeddings through cross-modal alignment between images and full-waveform LiDAR data. As the model is trained in a contrastive manner, the embeddings can be directly leveraged in the context of a variety of environmental monitoring tasks in a zero-shot setting. In our experiments, we demonstrate the effectiveness of the embeddings for seven such tasks (canopy height mapping, fractional canopy cover, land cover mapping, tree species identification, plant area index, crop type classification, and per-pixel waveform-based vertical structure mapping). The results show that the embeddings, along with zero-shot classifiers, often outperform specialized supervised models, even in low data regimes. In the fine-tuning setting, we show strong low-shot capabilities with performances near or better than state-of-the-art on five out of six tasks.