 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Associations to Activations: Comparing Behavioral and Hidden-State Semantic Geometry in LLMs
Jan 31, 2026We investigate the extent to which an LLM's hidden-state geometry can be recovered from its behavior in psycholinguistic experiments. Across eight instruction-tuned transformer models, we run two experimental paradigms -- similarity-based forced choice and free association -- over a shared 5,000-word vocabulary, collecting 17.5M+ trials to build behavior-based similarity matrices. Using representational similarity analysis, we compare behavioral geometries to layerwise hidden-state similarity and benchmark against FastText, BERT, and cross-model consensus. We find that forced-choice behavior aligns substantially more with hidden-state geometry than free association. In a held-out-words regression, behavioral similarity (especially forced choice) predicts unseen hidden-state similarities beyond lexical baselines and cross-model consensus, indicating that behavior-only measurements retain recoverable information about internal semantic geometry. Finally, we discuss implications for the ability of behavioral tasks to uncover hidden cognitive states.
SparseSwaps: Tractable LLM Pruning Mask Refinement at Scale
Dec 11, 2025The resource requirements of Neural Networks can be significantly reduced through pruning -- the removal of seemingly less important parameters. However, with the rise of Large Language Models (LLMs), full retraining to recover pruning-induced performance degradation is often prohibitive and classical approaches such as global magnitude pruning are suboptimal on Transformer architectures. State-of-the-art methods hence solve a layer-wise mask selection problem, the problem of finding a pruning mask which minimizes the per-layer pruning error on a small set of calibration data. Exactly solving this problem to optimality using Integer Programming (IP) solvers is computationally infeasible due to its combinatorial nature and the size of the search space, and existing approaches therefore rely on approximations or heuristics. In this work, we demonstrate that the mask selection problem can be made drastically more tractable at LLM scale. To that end, we decouple the rows by enforcing equal sparsity levels per row. This allows us to derive optimal 1-swaps (exchanging one kept and one pruned weight) that can be computed efficiently using the Gram matrix of the calibration data. Using these observations, we propose a tractable and simple 1-swap algorithm that warm starts from any pruning mask, runs efficiently on GPUs at LLM scale, and is essentially hyperparameter-free. We demonstrate that our approach reduces per-layer pruning error by up to 60% over Wanda (Sun et al., 2023) and consistently improves perplexity and zero-shot accuracy across state-of-the-art GPT architectures.
A Free Lunch in LLM Compression: Revisiting Retraining after Pruning
Oct 16, 2025While Neural Network pruning typically requires retraining the model to recover pruning-induced performance degradation, state-of-the-art Large Language Models (LLMs) pruning methods instead solve a layer-wise mask selection and reconstruction problem on a small set of calibration data to avoid full retraining, as it is considered computationally infeasible for LLMs. Reconstructing single matrices in isolation has favorable properties, such as convexity of the objective and significantly reduced memory requirements compared to full retraining. In practice, however, reconstruction is often implemented at coarser granularities, e.g., reconstructing a whole transformer block against its dense activations instead of a single matrix. In this work, we study the key design choices when reconstructing or retraining the remaining weights after pruning. We conduct an extensive computational study on state-of-the-art GPT architectures, and report several surprising findings that challenge common intuitions about retraining after pruning. In particular, we observe a free lunch scenario: reconstructing attention and MLP components separately within each transformer block is nearly the most resource-efficient yet achieves the best perplexity. Most importantly, this Pareto-optimal setup achieves better performance than full retraining, despite requiring only a fraction of the memory. Furthermore, we demonstrate that simple and efficient pruning criteria such as Wanda can outperform much more complex approaches when the reconstruction step is properly executed, highlighting its importance. Our findings challenge the narrative that retraining should be avoided at all costs and provide important insights into post-pruning performance recovery for LLMs.
Implicit Riemannian Optimism with Applications to Min-Max Problems
Jan 30, 2025



We introduce a Riemannian optimistic online learning algorithm for Hadamard manifolds based on inexact implicit updates. Unlike prior work, our method can handle in-manifold constraints, and matches the best known regret bounds in the Euclidean setting with no dependence on geometric constants, like the minimum curvature. Building on this, we develop algorithms for g-convex, g-concave smooth min-max problems on Hadamard manifolds. Notably, one method nearly matches the gradient oracle complexity of the lower bound for Euclidean problems, for the first time.
On the Byzantine-Resilience of Distillation-Based Federated Learning
Feb 19, 2024



Federated Learning (FL) algorithms using Knowledge Distillation (KD) have received increasing attention due to their favorable properties with respect to privacy, non-i.i.d. data and communication cost. These methods depart from transmitting model parameters and, instead, communicate information about a learning task by sharing predictions on a public dataset. In this work, we study the performance of such approaches in the byzantine setting, where a subset of the clients act in an adversarial manner aiming to disrupt the learning process. We show that KD-based FL algorithms are remarkably resilient and analyze how byzantine clients can influence the learning process compared to Federated Averaging. Based on these insights, we introduce two new byzantine attacks and demonstrate that they are effective against prior byzantine-resilient methods. Additionally, we propose FilterExp, a novel method designed to enhance the byzantine resilience of KD-based FL algorithms and demonstrate its efficacy. Finally, we provide a general method to make attacks harder to detect, improving their effectiveness.
Accelerated Methods for Riemannian Min-Max Optimization Ensuring Bounded Geometric Penalties
May 25, 2023

In this work, we study optimization problems of the form $\min_x \max_y f(x, y)$, where $f(x, y)$ is defined on a product Riemannian manifold $\mathcal{M} \times \mathcal{N}$ and is $\mu_x$-strongly geodesically convex (g-convex) in $x$ and $\mu_y$-strongly g-concave in $y$, for $\mu_x, \mu_y \geq 0$. We design accelerated methods when $f$ is $(L_x, L_y, L_{xy})$-smooth and $\mathcal{M}$, $\mathcal{N}$ are Hadamard. To that aim we introduce new g-convex optimization results, of independent interest: we show global linear convergence for metric-projected Riemannian gradient descent and improve existing accelerated methods by reducing geometric constants. Additionally, we complete the analysis of two previous works applying to the Riemannian min-max case by removing an assumption about iterates staying in a pre-specified compact set.
Efficient Online-Bandit Strategies for Minimax Learning Problems
Jun 04, 2021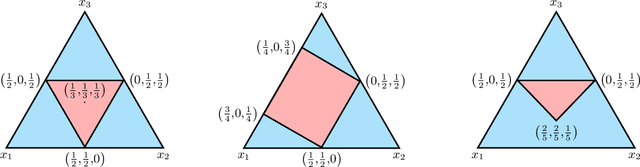
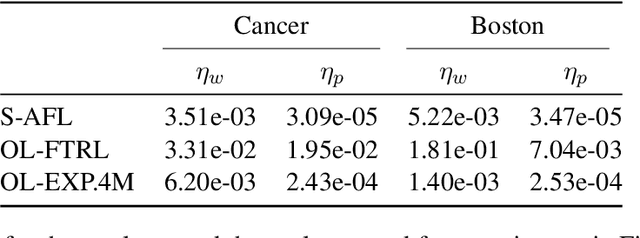
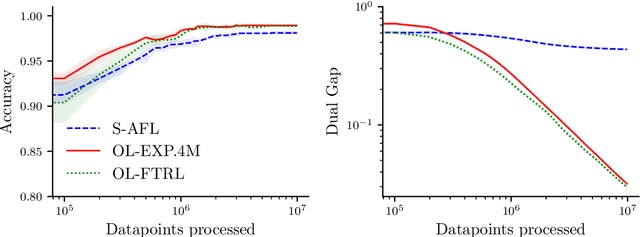

Several learning problems involve solving min-max problems, e.g., empirical distributional robust learning or learning with non-standard aggregated losses. More specifically, these problems are convex-linear problems where the minimization is carried out over the model parameters $w\in\mathcal{W}$ and the maximization over the empirical distribution $p\in\mathcal{K}$ of the training set indexes, where $\mathcal{K}$ is the simplex or a subset of it. To design efficient methods, we let an online learning algorithm play against a (combinatorial) bandit algorithm. We argue that the efficiency of such approaches critically depends on the structure of $\mathcal{K}$ and propose two properties of $\mathcal{K}$ that facilitate designing efficient algorithms. We focus on a specific family of sets $\mathcal{S}_{n,k}$ encompassing various learning applications and provide high-probability convergence guarantees to the minimax values.
Linear Bandits on Uniformly Convex Sets
Mar 10, 2021Linear bandit algorithms yield $\tilde{\mathcal{O}}(n\sqrt{T})$ pseudo-regret bounds on compact convex action sets $\mathcal{K}\subset\mathbb{R}^n$ and two types of structural assumptions lead to better pseudo-regret bounds. When $\mathcal{K}$ is the simplex or an $\ell_p$ ball with $p\in]1,2]$, there exist bandits algorithms with $\tilde{\mathcal{O}}(\sqrt{nT})$ pseudo-regret bounds. Here, we derive bandit algorithms for some strongly convex sets beyond $\ell_p$ balls that enjoy pseudo-regret bounds of $\tilde{\mathcal{O}}(\sqrt{nT})$, which answers an open question from [BCB12, \S 5.5.]. Interestingly, when the action set is uniformly convex but not necessarily strongly convex, we obtain pseudo-regret bounds with a dimension dependency smaller than $\mathcal{O}(\sqrt{n})$. However, this comes at the expense of asymptotic rates in $T$ varying between $\tilde{\mathcal{O}}(\sqrt{T})$ and $\tilde{\mathcal{O}}(T)$.