 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Discovery in Mathematics: Do Machines Dream of Colored Planes?
Jan 30, 2025



We demonstrate how neural networks can drive mathematical discovery through a case study of the Hadwiger-Nelson problem, a long-standing open problem from discrete geometry and combinatorics about coloring the plane avoiding monochromatic unit-distance pairs. Using neural networks as approximators, we reformulate this mixed discrete-continuous geometric coloring problem as an optimization task with a probabilistic, differentiable loss function. This enables gradient-based exploration of admissible configurations that most significantly led to the discovery of two novel six-colorings, providing the first improvements in thirty years to the off-diagonal variant of the original problem (Mundinger et al., 2024a). Here, we establish the underlying machine learning approach used to obtain these results and demonstrate its broader applicability through additional results and numerical insights.
PERP: Rethinking the Prune-Retrain Paradigm in the Era of LLMs
Dec 23, 2023



Neural Networks can be efficiently compressed through pruning, significantly reducing storage and computational demands while maintaining predictive performance. Simple yet effective methods like Iterative Magnitude Pruning (IMP, Han et al., 2015) remove less important parameters and require a costly retraining procedure to recover performance after pruning. However, with the rise of Large Language Models (LLMs), full retraining has become infeasible due to memory and compute constraints. In this study, we challenge the practice of retraining all parameters by demonstrating that updating only a small subset of highly expressive parameters is often sufficient to recover or even improve performance compared to full retraining. Surprisingly, retraining as little as 0.27%-0.35% of the parameters of GPT-architectures (OPT-2.7B/6.7B/13B/30B) achieves comparable performance to One Shot IMP across various sparsity levels. Our method, Parameter-Efficient Retraining after Pruning (PERP), drastically reduces compute and memory demands, enabling pruning and retraining of up to 30 billion parameter models on a single NVIDIA A100 GPU within minutes. Despite magnitude pruning being considered as unsuited for pruning LLMs, our findings show that PERP positions it as a strong contender against state-of-the-art retraining-free approaches such as Wanda (Sun et al., 2023) and SparseGPT (Frantar & Alistarh, 2023), opening up a promising alternative to avoiding retraining.
Sparse Model Soups: A Recipe for Improved Pruning via Model Averaging
Jun 29, 2023



Neural networks can be significantly compressed by pruning, leading to sparse models requiring considerably less storage and floating-point operations while maintaining predictive performance. Model soups (Wortsman et al., 2022) improve generalization and out-of-distribution performance by averaging the parameters of multiple models into a single one without increased inference time. However, identifying models in the same loss basin to leverage both sparsity and parameter averaging is challenging, as averaging arbitrary sparse models reduces the overall sparsity due to differing sparse connectivities. In this work, we address these challenges by demonstrating that exploring a single retraining phase of Iterative Magnitude Pruning (IMP) with varying hyperparameter configurations, such as batch ordering or weight decay, produces models that are suitable for averaging and share the same sparse connectivity by design. Averaging these models significantly enhances generalization performance compared to their individual components. Building on this idea, we introduce Sparse Model Soups (SMS), a novel method for merging sparse models by initiating each prune-retrain cycle with the averaged model of the previous phase. SMS maintains sparsity, exploits sparse network benefits being modular and fully parallelizable, and substantially improves IMP's performance. Additionally, we demonstrate that SMS can be adapted to enhance the performance of state-of-the-art pruning during training approaches.
Compression-aware Training of Neural Networks using Frank-Wolfe
May 24, 2022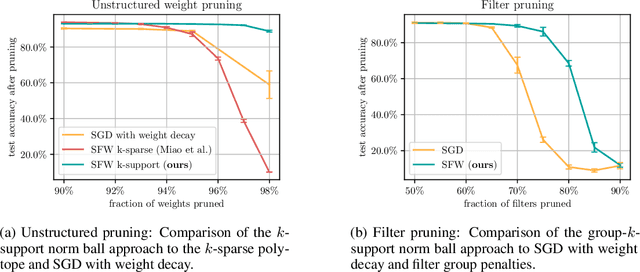

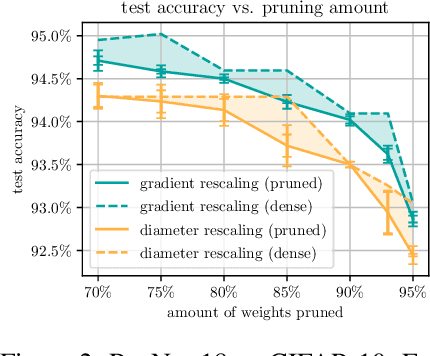

Many existing Neural Network pruning approaches either rely on retraining to compensate for pruning-caused performance degradation or they induce strong biases to converge to a specific sparse solution throughout training. A third paradigm obtains a wide range of compression ratios from a single dense training run while also avoiding retraining. Recent work of Pokutta et al. (2020) and Miao et al. (2022) suggests that the Stochastic Frank-Wolfe (SFW) algorithm is particularly suited for training state-of-the-art models that are robust to compression. We propose leveraging $k$-support norm ball constraints and demonstrate significant improvements over the results of Miao et al. (2022) in the case of unstructured pruning. We also extend these ideas to the structured pruning domain and propose novel approaches to both ensure robustness to the pruning of convolutional filters as well as to low-rank tensor decompositions of convolutional layers. In the latter case, our approach performs on-par with nuclear-norm regularization baselines while requiring only half of the computational resources. Our findings also indicate that the robustness of SFW-trained models largely depends on the gradient rescaling of the learning rate and we establish a theoretical foundation for that practice.
Back to Basics: Efficient Network Compression via IMP
Nov 01, 2021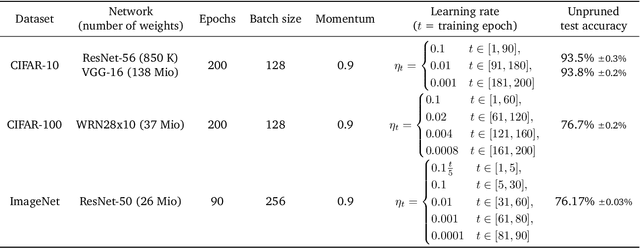
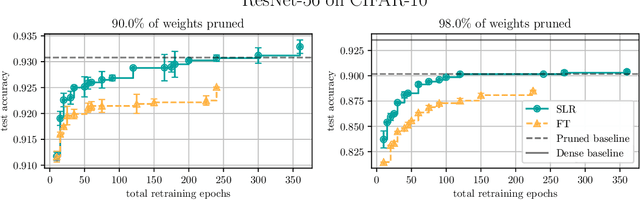
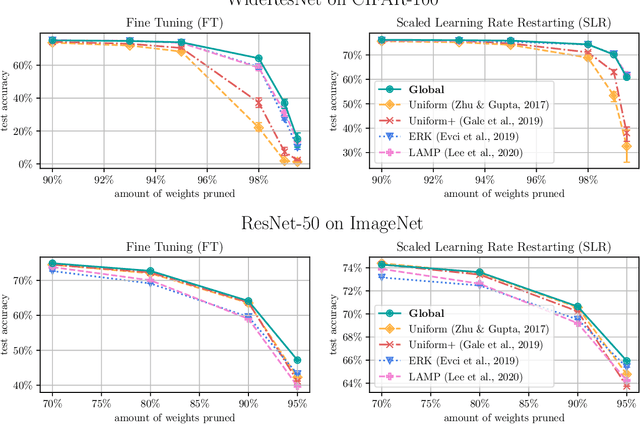

Network pruning is a widely used technique for effectively compressing Deep Neural Networks with little to no degradation in performance during inference. Iterative Magnitude Pruning (IMP) is one of the most established approaches for network pruning, consisting of several iterative training and pruning steps, where a significant amount of the network's performance is lost after pruning and then recovered in the subsequent retraining phase. While commonly used as a benchmark reference, it is often argued that a) it reaches suboptimal states by not incorporating sparsification into the training phase, b) its global selection criterion fails to properly determine optimal layer-wise pruning rates and c) its iterative nature makes it slow and non-competitive. In light of recently proposed retraining techniques, we investigate these claims through rigorous and consistent experiments where we compare IMP to pruning-during-training algorithms, evaluate proposed modifications of its selection criterion and study the number of iterations and total training time actually required. We find that IMP with SLR for retraining can outperform state-of-the-art pruning-during-training approaches without or with only little computational overhead, that the global magnitude selection criterion is largely competitive with more complex approaches and that only few retraining epochs are needed in practice to achieve most of the sparsity-vs.-performance tradeoff of IMP. Our goals are both to demonstrate that basic IMP can already provide state-of-the-art pruning results on par with or even outperforming more complex or heavily parameterized approaches and also to establish a more realistic yet easily realisable baseline for future research.
Deep Neural Network Training with Frank-Wolfe
Oct 21, 2020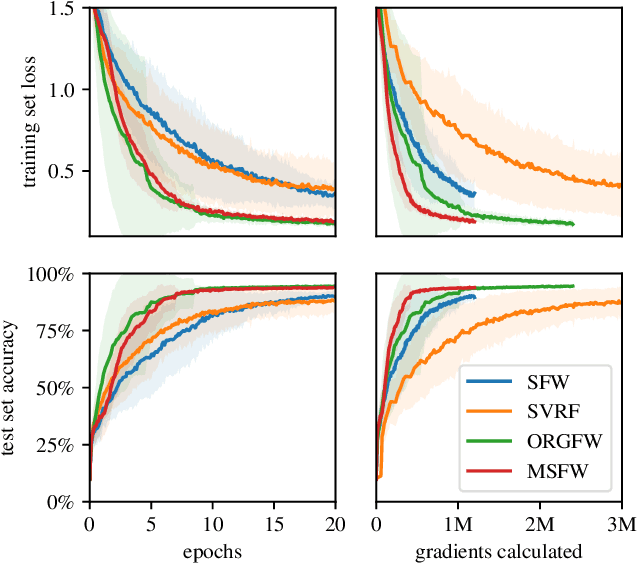

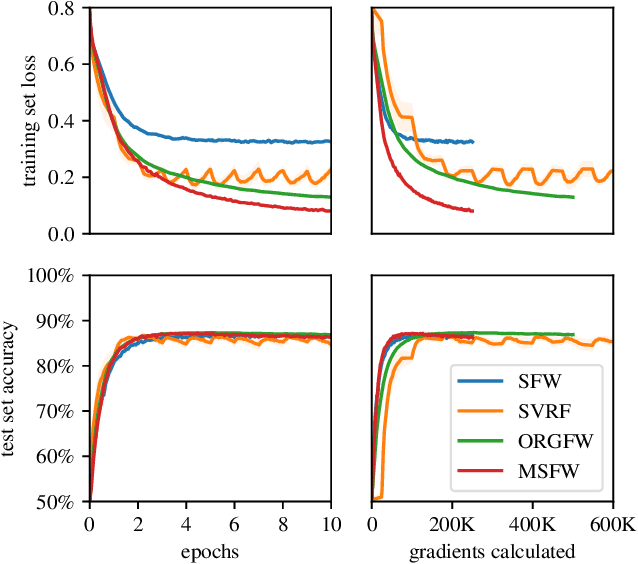

This paper studies the empirical efficacy and benefits of using projection-free first-order methods in the form of Conditional Gradients, a.k.a. Frank-Wolfe methods, for training Neural Networks with constrained parameters. We draw comparisons both to current state-of-the-art stochastic Gradient Descent methods as well as across different variants of stochastic Conditional Gradients. In particular, we show the general feasibility of training Neural Networks whose parameters are constrained by a convex feasible region using Frank-Wolfe algorithms and compare different stochastic variants. We then show that, by choosing an appropriate region, one can achieve performance exceeding that of unconstrained stochastic Gradient Descent and matching state-of-the-art results relying on $L^2$-regularization. Lastly, we also demonstrate that, besides impacting performance, the particular choice of constraints can have a drastic impact on the learned representations.
Projection-Free Adaptive Gradients for Large-Scale Optimization
Oct 16, 2020



The complexity in large-scale optimization can lie in both handling the objective function and handling the constraint set. In this respect, stochastic Frank-Wolfe algorithms occupy a unique position as they alleviate both computational burdens, by querying only approximate first-order information from the objective and by maintaining feasibility of the iterates without using projections. In this paper, we improve the quality of their first-order information by blending in adaptive gradients. Starting from the design of adaptive gradient algorithms, we propose to solve the occurring constrained optimization subproblems \emph{very} incompletely via a fixed and small number of iterations of the Frank-Wolfe algorithm (often times only $2$ iterations), in order to preserve the low per-iteration complexity. We derive convergence rates and demonstrate the computational advantage of our method over the state-of-the-art stochastic Frank-Wolfe algorithms on both convex and nonconvex objectives.