 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplexity of Linear Minimization and Projection on Some Sets
Jan 25, 2021
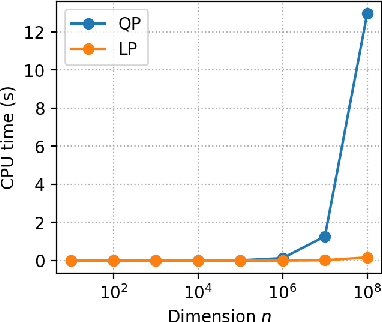
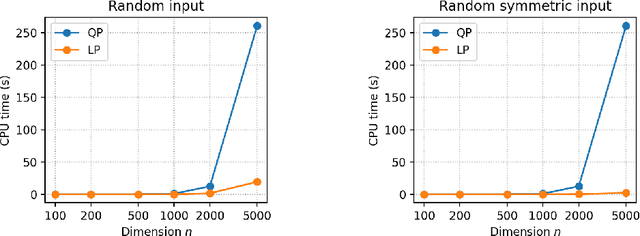
The Frank-Wolfe algorithm is a method for constrained optimization that relies on linear minimizations, as opposed to projections. Therefore, a motivation put forward in a large body of work on the Frank-Wolfe algorithm is the computational advantage of solving linear minimizations instead of projections. However, the discussions supporting this advantage are often too succinct or incomplete. In this paper, we review the complexity bounds for both tasks on several sets commonly used in optimization. Projection methods onto the $\ell_p$-ball, $p\in\left]1,2\right[\cup\left]2,+\infty\right[$, and the Birkhoff polytope are also proposed.
Projection-Free Adaptive Gradients for Large-Scale Optimization
Oct 16, 2020



The complexity in large-scale optimization can lie in both handling the objective function and handling the constraint set. In this respect, stochastic Frank-Wolfe algorithms occupy a unique position as they alleviate both computational burdens, by querying only approximate first-order information from the objective and by maintaining feasibility of the iterates without using projections. In this paper, we improve the quality of their first-order information by blending in adaptive gradients. Starting from the design of adaptive gradient algorithms, we propose to solve the occurring constrained optimization subproblems \emph{very} incompletely via a fixed and small number of iterations of the Frank-Wolfe algorithm (often times only $2$ iterations), in order to preserve the low per-iteration complexity. We derive convergence rates and demonstrate the computational advantage of our method over the state-of-the-art stochastic Frank-Wolfe algorithms on both convex and nonconvex objectives.
Boosting Frank-Wolfe by Chasing Gradients
Mar 13, 2020



The Frank-Wolfe algorithm has become a popular first-order optimization algorithm for it is simple and projection-free, and it has been successfully applied to a variety of real-world problems. Its main drawback however lies in its convergence rate, which can be excessively slow due to naive descent directions. We propose to speed-up the Frank-Wolfe algorithm by better aligning the descent direction with that of the negative gradient via a subroutine. This subroutine chases the negative gradient direction in a matching pursuit-style while still preserving the projection-free property. Although the approach is reasonably natural, it produces very significant results. We derive convergence rates $\mathcal{O}(1/t)$ to $\mathcal{O}(e^{-\omega t^p})$ of our method where $p\in\left]0,1\right]$, and we demonstrate its competitive advantage both per iteration and in CPU time over the state-of-the-art in a series of computational experiments.
Revisiting the Approximate Carathéodory Problem via the Frank-Wolfe Algorithm
Nov 11, 2019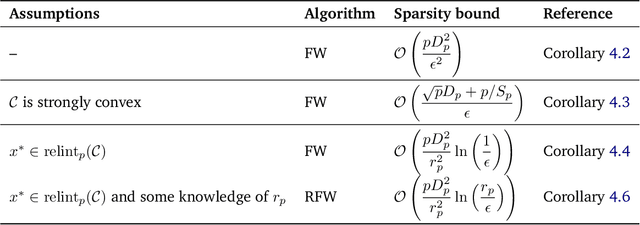
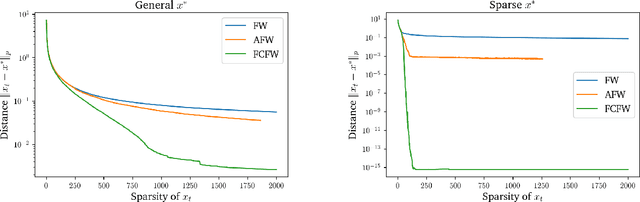
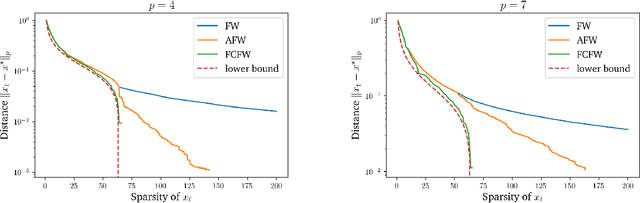
The approximate Carath\'eodory theorem states that given a polytope $\mathcal{P}$, each point in $\mathcal{P}$ can be approximated within $\epsilon$-accuracy in $\ell_p$-norm as the convex combination of $\mathcal{O}(pD_p^2/\epsilon^2)$ vertices, where $p\geq2$ and $D_p$ is the diameter of $\mathcal{P}$ in $\ell_p$-norm. A solution satisfying these properties can be built using probabilistic arguments [Barman, 2015] or by applying mirror descent to the dual problem [Mirrokni et al., 2017]. We revisit the approximate Carath\'eodory problem by solving the primal problem via the Frank-Wolfe algorithm, providing a simplified analysis and leading to an efficient practical method. Sublinear to linear sparsity bounds are derived naturally using existing convergence results of the Frank-Wolfe algorithm in different scenarios.
Blended Matching Pursuit
Apr 28, 2019



Matching pursuit algorithms are an important class of algorithms in signal processing and machine learning. We present a blended matching pursuit algorithm, combining coordinate descent-like steps with stronger gradient descent steps, for minimizing a smooth convex function over a linear space spanned by a set of atoms. We derive sublinear to linear convergence rates according to the smoothness and sharpness orders of the function and demonstrate computational superiority of our approach. In particular, we derive linear rates for a wide class of non-strongly convex functions, and we demonstrate in experiments that our algorithm enjoys very fast rates of convergence and wall-clock speed while maintaining a sparsity of iterates very comparable to that of the (much slower) orthogonal matching pursuit.